Поисковик своими руками / Хабр
Мне всегда не дает покоя идея поисковых машин, особенно то, что создатели в начале даже не подозревали о необыкновенных перспективах данной технологии.
Я решил на практике изучить, что же это такое – поисковый движок. Назвал его
nanorit.com. Но для экспериментов я не брал никакие известные API от Google, а решил создать свой.
Для начала я загрузил базу доменов, получилось около 70000 уникальных сайтов. Далее разработал поискового робота, который подключался поочередно к одному сайту и загружал все ссылки с главной страницы, которые относятся к данному сайту. Такое ограничение я сделал, чтобы робот не погряз в дебрях большого сайта, или раскрученного форума. Но, думаю, в дальнейшем оптимизировать алгоритм. Далее я ставлю метку для проиндексированного сайта с датой индексации и перехожу к следующему сайту.
Чего я добился на данный момент – в базе находится сейчас около 1.5 млн. документов, причем загружаю я только заголовки, потому что тело документа грузить весьма накладно по ресурсам.
Далее я рассказал про свою идею знакомому кандидату наук, вместе учились. Он мне рассказал про лингвистический анализ. Я решил разбить все заголовки на отдельные слова и составить реестр данных слов и связанную таблицу – в которой для каждого заголовка идет перечисление идентификаторов слов. В итоге получилось слов в индексе 139000, а связок для заголовков 2,184,204. Далее я сделал алгоритм поиска по данному индексу, но результат оказался хуже, чем если просто искать через like ‘%keyword%’, поэтому я решил пока не развивать алгоритм в эту сторону.
Потом я решил проверить интерес пользователей, и добавил рейтинг поисковых запросов, для каждого запроса считаю количество обращений. Самое интересное, что поисковые машины тоже начали «кликать», есть опасность что забанят, но яндекс пока индексирует.
Сейчас я добавил функцию добавления своего сайта в индекс, и также пользователи проявили интерес и регулярно добавляют свои сайты.
Какие выводы я получил – не боги горшки обжигают. Вот главный вывод. Думаю сейчас развить идею и приобрести выделенный сервер для поисковика. Ну а далее в планах изучить архитектуру кластерной обработки данных и оптимизировать скорость обработки запросов – сейчас честно говоря, по сравнению с гуглом очень медленно ищет.
Как создать свою собственную систему пользовательского поиска Google
НЕКЕШЕРОВАННЫЙ КОНТЕНТВы когда-нибудь хотели создать собственную поисковую систему Google, которая будет искать только определенные веб-сайты? Вы можете легко сделать это с помощью системы пользовательского поиска Google. Вы можете добавить свою поисковую систему в закладки и даже поделиться ею с другими людьми.
Этот трюк работает так же, как у Google

Создание системы пользовательского поиска
Для начала перейдите в Система пользовательского поиска Google страницу и нажмите кнопку Создать систему пользовательского поиска. Для этого вам понадобится учетная запись Google — поисковая система будет сохранена в вашей учетной записи Google.
Введите название и описание вашей поисковой системы — это может быть что угодно.
В Сайты для поиска Поле действительно имеет значение. Здесь вы указываете список веб-сайтов, на которых хотите выполнить поиск. Например, если вы хотите выполнить поиск как на howtogeek.com, так и на microsoft.com, вы должны ввести:
новтогеек.ком/*
микрософт.ком/*
Символ * — это подстановочный знак, который может соответствовать чему угодно, поэтому символы / * говорят вашей поисковой системе искать все на обоих этих веб-сайтах.
С этим ящиком можно делать и более сложные действия — мы вернемся к этому чуть позже.
После нажатия кнопки «Далее» вы можете указать стиль результатов поиска и протестировать созданную вами поисковую систему.
Как только вы будете довольны своей поисковой системой, нажмите кнопку «Далее» внизу страницы, и вы попадете на страницу, содержащую код встраивания для вашей поисковой системы.
Вы, вероятно, не веб-разработчик, поэтому не обращайте внимания на эту страницу. Вместо этого нажмите логотип Системы пользовательского поиска Google вверху страницы.
Чтобы перейти на страницу своей поисковой системы, щелкните ее название в списке созданных вами поисковых систем.
Вы можете добавить эту страницу в закладки для быстрого доступа к вашей поисковой системе. Вы также можете поделиться своей поисковой системой с кем угодно, отправив им полный URL-адрес, который отображается в вашей адресной строке.
Уловки URL
При создании системы пользовательского поиска необязательно указывать весь веб-сайт.
Например, указанная выше система пользовательского поиска выполняет поиск во всех областях microsoft.com. Если мы выполним пример поиска, мы можем увидеть, что полезная информация поступает из
виндовс.микрософт.ком а также суппорт.микрософт.ком , но результаты ансверс.микрософт.ком (Форум поддержки Microsoft) не очень полезны.Чтобы исключить answers.microsoft.com и включить другие поддомены, мы могли бы использовать следующий список URL-адресов при создании поисковой системы:
новтогеек.ком/*
виндовс.микрософт.ком/*
суппорт.микрософт.ком/*
Обратите внимание, что нельзя исключить конкретный субдомен — мы можем включить только те, которые хотим найти. Этот список будет искать только два поддомена на microsoft.com.
Этот список будет искать только два поддомена на microsoft.com.
В этом списке можно определить несколько других типов URL-адресов:
- Одна страница
- Часть веб-сайта : Вы можете использовать символ * по-другому. Например, URL суппорт.микрософт.ком/кб/* будет искать только статьи базы знаний Microsoft. Использование URL эксампле.ком/*ворд* будет искать все страницы на example.com, на которых есть слово в своих URL.
Вы можете продолжить тонкую настройку поисковой системы, пока не будете довольны результатами, нажав кнопку вернуться к шагу 1 ссылку, изменив URL-адреса, а затем выполните еще один тестовый поиск.
Когда вы закончите, вы можете даже добавьте свою систему пользовательского поиска в строку поиска своего браузера .
Собственный поисковик можно создать бесплатно | Останні новини IT
Компания «Поисковые технологии» недавно представила Рунету уникальный сервис Flexum.ru, позволяющий любому пользователю создать свой собственный поиск по интернет-сайтам.
Теперь каждому новому участнику бесплатно предоставляется 5 гигабайт дискового пространства – этого достаточно, чтобы создать собственную полноценную поисковую систему по нескольким десяткам сайтов.
Каждый автор поиска может вручную отбирать сайты для индексации, поэтому результаты поисковой выдачи не содержат «спама» и прочего мусора, которым сильно грешат обычные поисковые системы.
Кроме того, Flexum.ru рассчитан на совместную работу нескольких авторов – благодаря системе распределения прав созданием поисковой системы можно заниматься коллективно.
Также в распоряжении пользователей традиционные элементы современного сервиса: блоги, средства общения с коллегами, система публикации собственных статей и многое другое.
Flexum.ru активно развивается – в проекте уже зарегистрировано более 3700 авторов, которые создали более 2000 собственных поисковых систем по фильмам, книгам, блогам и другим многочисленным тематикам.
Благодаря тому, что теперь пользователи Flexum.ru имеют в своём распоряжении целых 5 гигабайт дискового пространства, создание качественных тематических поисковых систем стало простым занятием.
На сегодняшний день Flexum.ru не имеет аналогов, разработанных на рынке СНГ. Основным конкурентом российского продукта можно считать Google Co-op, предлагающий схожее решение.
Компания-разработчик Flexum.ru – ЗАО “Поисковые технологии” – основана в 2004 году компанией “Ашманов и Партнеры” и инвестиционным холдингом “Финам” с целью создания качественно новых средств структурированного поиска информации в Сети.
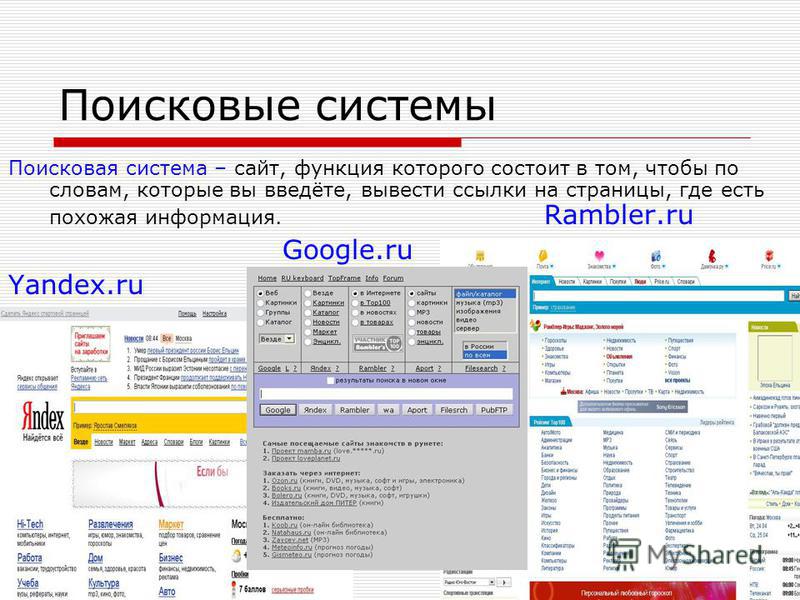
Многообразие поисковых систем. Воспользоваться чужой или создать свою?
По большому счету поисковые системы – это веб-сайты, предоставляющие возможность поиска информации в Интернете. При этом их можно разделить на несколько категорий в зависимости от предназначения и способов поиска.
с помощью программ-роботов постоянно исследуют сеть, просматривая все сайты, которые им удается найти, и помещая информацию о них в свои базы данных. Для этого не требуется практически никакого человеческого вмешательства, так как вся работа происходит автоматически. Достоинствами поисковых машин является то, что они могут содержать информацию практически обо всех сайтах. Это позволяет пользователям находить сайты практически по любым запросам. Однако такие системы не очень хорошо ориентируются в структуре индексируемых сайтов, и результаты их поиска далеко не идеальны.
Поисковые машины
Поисковые машины с помощью программ-роботов постоянно исследуют сеть, просматривая все сайты, которые им удается найти, и помещая информацию о них в свои базы данных. Для этого не требуется практически никакого человеческого вмешательства, так как вся работа происходит автоматически. Достоинствами поисковых машин является то, что они могут содержать информацию практически обо всех сайтах. Это позволяет пользователям находить сайты практически по любым запросам. Однако такие системы не очень хорошо ориентируются в структуре индексируемых сайтов, и результаты их поиска далеко не идеальны.
Помимо знакомых всем Google и Яndex, на данный момент с лучшей стороны себя зарекомендовали AltaVista (www.altavista.com), Rambler (www.rambler.ru), Апорт (www.aport.ru), Gogo (http://gogo.ru) и Webalta (www.webalta.ru).
Каталоги и тематические каталоги
Представляют собой четко организованную структуру сайтов, систематизированных по тематике. Добавление адресов в такие каталоги осуществляется авторами сайтов, так называемыми гидами, которые «блуждают» по сети и добавляют найденные новинки в нужные разделы каталога. С помощью каталогов можно достаточно просто и быстро найти сайты по интересующей тематике. Часто поиск возможен лишь по ключевым словам. Недостатком каталогов является то, что они содержат информацию лишь о части сети, поэтому зачастую можно вообще не найти того, что нужно.
С помощью каталогов можно достаточно просто и быстро найти сайты по интересующей тематике. Часто поиск возможен лишь по ключевым словам. Недостатком каталогов является то, что они содержат информацию лишь о части сети, поэтому зачастую можно вообще не найти того, что нужно.
Наиболее полными, популярными и развивающимися каталогами сейчас являются Каталог Яndex’а (http://yaca.yandex.ru/), List.ru (http://list.mail.ru/), RamblerTop100 (http://top100.rambler.ru/), Каталог Апорт (http://catalog.aport.ru/).
Тематические каталоги – разновидность обычных, однако они предназначены для конкретной целевой аудитории. Примером может служить каталог ресурсов по юридическим вопросам (http://law.web-ring.ru).
К сожалению, такие ресурсы зачастую плохо поддерживаются.
Специализированные поисковые машины и каталоги
В последнее время стала актуальной задача узконаправленного поиска. Он выполняется с помощью специализированных машин и каталогов, предназначенных для отбора различного рода специализированной информации. Существует, например, поиск по форумам и блогам (http://blogs.yandex.ru, www.google.ru/blogsearch), по новостным ресурсам (www.novoteka.ru), по словарям (www.boloto.info, http://slovari.yandex.ru), поиск изображений (http://images.google.ru, http://images.yandex.ru), поиск музыкальных файлов (http://music.yandex.ru), видео (http://middio.com), поиск по FTP-серверам (www.filesearch.ru/) и очень много других. Есть даже детские поисковики, но, к сожалению, они представлены только зарубежными сайтами – например, www.factmonster.com или http://kids.quintura.com.
Существует, например, поиск по форумам и блогам (http://blogs.yandex.ru, www.google.ru/blogsearch), по новостным ресурсам (www.novoteka.ru), по словарям (www.boloto.info, http://slovari.yandex.ru), поиск изображений (http://images.google.ru, http://images.yandex.ru), поиск музыкальных файлов (http://music.yandex.ru), видео (http://middio.com), поиск по FTP-серверам (www.filesearch.ru/) и очень много других. Есть даже детские поисковики, но, к сожалению, они представлены только зарубежными сайтами – например, www.factmonster.com или http://kids.quintura.com.
У подобных сервисов более качественные, релевантные результаты поиска, и они отнимают меньше времени на поиск. Минус только один, но зато весьма существенный – сравнительно малый объем баз данных проиндексированных страниц.
Метапоисковые машины
Позволяют производить параллельный поиск в ряде поисковых систем. Обычно они предоставляют дополнительные возможности (например, проверка ссылок, перевод и расширение запросов, перевод запросов на язык используемых поисковых систем). Хорошим примером метапоисковых машины являются поисковики Punto (http://punto.ru/), Nigma (http://nigma.ru/) и Ramdex (www.ramdex.ru/).
Хорошим примером метапоисковых машины являются поисковики Punto (http://punto.ru/), Nigma (http://nigma.ru/) и Ramdex (www.ramdex.ru/).
Социальные поисковые системы
Под социальным поиском понимается технология, предполагающая, что на выдачу результатов могут влиять сами люди. По каждому поисковому запросу здесь отображается только информация, отобранная вручную (об этом хорошо написано Надеждой БАЛОВСЯК на стр. 4-5)
Критерии качества
Разработчики поисковых систем постоянно работают над улучшением качества выдачи результатов поисковиков и над удобством механизмов визуализации этих результатов. Качество работы поисковой машины определяется целым набором критериев.
1. Релевантность
Под релевантностью по отношению к результатам работы поисковой понимается степень соответствия запроса и выдачи, а также уместность результата. Вообще говоря, это достаточно субъективное понятие – то, что уместно для одного пользователя, может быть неуместно для другого.
Математические приемы, обеспечивающие наиболее релевантную выдачу, строятся в основном на подсчете «веса» документа по отношению к запросу и сортировке выдачи на основе этого «веса». Кроме того, необходимо постоянно развивать механизмы, отсеивающие из индекса всевозможный «информационный шум»: ссылочный спам, сайты-дорвеи (страницы, содержащие автоматически генерируемый контент, состоящий из бессмысленного набора ключевых слов, которые перенаправляют посетителя на некоторый целевой сайт), и различные сайты, использующие нечестные приемы раскрутки.
2. Полнота базы
В данном случае это количество проиндексированных поисковиком Интернет-страниц. Каждую секунду в сети создаются сотни тысяч документов, выкладываются файлы, создаются записи в блогах, пишутся комментарии. Очень важно, чтобы все это как можно быстрее прошло через поисковую машину и было доступно для обработки. Ведь качественная информация – это, в первую очередь, актуальный материал.
3. Учет морфологии и языка
Современный поисковик должен понимать запросы пользователя в том виде, в каком они задаются, а также индексировать страницы с учетом морфологических особенностей языка. Создать алгоритм работы, который абсолютно точно понимает, что хотел найти пользователь, и выдает ему только нужные ссылки, пока еще не удавалось никому. По сути, эта проблема стоит на одной чаше весов с проблемой создания искусственного интеллекта. Поэтому решать ее будут еще очень и очень долго.
Создать алгоритм работы, который абсолютно точно понимает, что хотел найти пользователь, и выдает ему только нужные ссылки, пока еще не удавалось никому. По сути, эта проблема стоит на одной чаше весов с проблемой создания искусственного интеллекта. Поэтому решать ее будут еще очень и очень долго.
4. Удобство визуализации результатов
Существует множество поисковиков, которые дают «альтернативный поисковый интерфейс» и нелинейное представление данных. Такие поисковики называются визуальными.
Чаще всего данные в таких поисковиках имеют свою особую иерархию. Нередко появляются некоторые ассоциативные понятия, синонимы запросов, которые, в свою очередь, раскрывают свои ассоциативные ряды, создают цепочки понятий, смыслов и так далее. Естественно, что такие поисковые системы подразумевают под собой некоторые зачатки семантических отношений между ссылками. Здесь работают более сложные математические модели, которые просчитывают родство и схожесть запросов и позволяют угадать, что же пользователь хотел найти в Интернете.
Чтобы понять, о чем же все-таки идет речь, достаточно просто посмотреть на работу следующих поисковиков.
KartOO (http://www.kartoo.com). Очень приятная глазу метапоисковая система. Она пытается в общих чертах изобразить связи между объектами – результатами поиска и рисует своеобразную карту этих отношений.
Kwmap (http://www.kwmap.net). Достаточно простая схема визуализации данных: пересечение двух плоскостей результатов поиска в одной точке, которой символизируется наш запрос. Одна плоскость включает в себя понятия, содержащие ключевое слово, другая – лишь схожие понятия, не включающие в себя слово запроса.
Vizzy (http://www.vizzy.ru). Интересная российская задумка – поисковик на флэш-анимации. Использован поисковый движок от Google, но это только в плюс.
Персональный поиск
На самом деле, поисковиков в сети так много, что для их поиска в пору создавать специальную поисковую систему. Кстати, вы сами можете сделать ее – сейчас в Интернете существуют сервисы, позволяющие создать собственный поисковик, который будет индексировать только те сайты, которые вы ему укажете.
Вот, например, Google CSE (Custom Search Engines, www.google.ru/coop/cse) дает довольно широкие возможности даже при минимальном владении инструментами разработки. Если к этому приложить немного программистских навыков и капельку дизайна, то может получиться вполне качественный поисковик.
Из русскоязычных сервисов можно выделить портал Flexum (www.flexum.ru/). Примеров поисковиков, созданных на основе этого сайта, уже довольно много, и они доступны для всеобщего пользования: например, поисковик «Всё про айкидо» (http://aikido.flexum.ru/). Подобную поисковую систему вы можете организовать буквально за 5 минут.
Андрей ПОЧУЕВ, инженер ОАО «Уралпромпроект», Златоуст
Используйте Python, чтобы создать свою поисковую систему видео
Уважаемые фанаты, это большим для своих собственных видео документов для своих десятков сотен G, или я видел движущуюся пленку, я буду помнить, что у меня есть жесткие диски, я хочу снова включить, но я тоже нашел это. Может Опыт трагического опыта.
Может Опыт трагического опыта.
Не волнуйтесь, я буду сопровождать вас сегодня, построить простой и эффективный инструмент поиска видео. С тех пор моя мама не должна беспокоиться, я не могу найти фильм, который я люблю смотреть!
Сначала приходите быстро и быстро:
Инструменты разработки: Pycharm, Opencv, Phash Library, MySQL и некоторые основные методы обработки потоков видео. Через эту статью вы научите ваш собственный инструмент поиска.
Основной процесс реализации:
Построить библиотеку видео отпечатков пальцев
Возвращает аналогичные видео результаты
Рассчитать хэш Расстояние
Абстрактное хеш-ценность
Введите видео запроса
Подготовительные знания:
Процесс расчета фашника и удара хэмминга выглядит следующим образом:
(1) Уменьшите размер: уменьшить размер размера 8 * 8, со всего 64 пикселей. Роль этого шага состоит в том, чтобы удалить детали изображения, только для сохранения базовой информации, такой как структуры / света и другие, отказаться от различий изображений от разных размеров / пропорциональных;
(2) Упрощенный цвет: изображение будет уменьшено, и обратиться к 64 градации, то есть все точки пикселей имеют только 64 цветов;
(3) Рассчитать среднее значение: рассчитать среднее значение серого всех 64 пикселей;
(4) Сравнение оттенков серого: сравнивает серого каждого пикселя, больше или равно среднему значению 1, меньше, чем среднее значение 0;
(5) Рассчитайте значение хеша: сравнение предыдущего шага объединяется, целое число 64-битного, которое является отпечаткам этого изображения. Порядок комбинации не важен, до тех пор, пока все изображения используются в том же порядке;
Порядок комбинации не важен, до тех пор, пока все изображения используются в том же порядке;
(6) После получения отпечатков пальцев вы можете сравнить разные изображения и посмотреть, сколько битов в 64 бита разные. Теоретически, это эквивалентно «расстоянию HAMMING» (в теории информации, расстояние газа между двумя равными строками равных длин является количеством различных символов двух строковых соответствующих позиций).
Готов ли маленький партнер? Просто официально открыть наше путешествие: чувствительность Hash Value — как создать свою первую систему поисковой системы видео с Python.
Один. Построить библиотеку видео отпечатков пальцев:
(1) видео перехват
Получите текущую частоту кадров FPS (т. Е. Количество кадров в секунду), предполагая, что видеокадр перехвачен каждые 5 секунд, преобразован в видеокадру номер 5 * FPS Frame, перехватывающий видеоизображение.
Для следующего видео: предположим, что видео составляет 20 секунд, частота кадров составляет 24, в соответствии с интервалом каждые 5 секунд (24 * 5 = 120 кадров), то вы можете получить следующие четыре видеореанаты:
Давайте посмотрим на образец видео, которую мы подготовили:
Прочитайте видео, перехватите его статические кадры каждые 10, извлеките каждый кадр и поместите все значения хэша в извлеченное значение HASH, и хранить значение HASH HASH в базу данных MySQL.
При воспринимаемом алгоритме Phash Hash Value Phash Image отпечаток пальца каждого изображения рассчитывается, и все видео выполняется, и видеокадр перехвачен в соответствии с тем же временным интервалом, отпечаток пальца получен и, наконец, сохраняет.
На данный момент установлена библиотека отпечатков пальцев данного видео. Текущая база данных содержит 3 поля, а именно: ID, Videoid, Phash
два. Подобное видео запрос
На предыдущем шаге мы создали библиотеку отпечатков пальцев для данного видео, а именно: серию хеш-значений в разные временные точки. Далее, используйте то же самое, введите видео, извлеките значение HASH, а затем запрос в встроенной библиотеке видеофильмы видео, чтобы определить, есть ли подобное видео.
В сравнении видео сходство общего способа измерения сходства состоит в том, чтобы рассчитать расстояние между двумя особенностями, а общие методы являются: европейское расстояние, расстояние в косинус, расстояние гамма. Здесь мы используем метод расчета расстояния Hamming для сравнения сходства между двумя видео.
Здесь мы используем метод расчета расстояния Hamming для сравнения сходства между двумя видео.
Сначала прочитайте видео и извлеките значение Phash видео.Далее, запросив все видео в базе данных и рассчитывая расстояние газета в базе данных видео-хеша в базе данных, соответственно, и сортирует муфту, извлекать топ-20 подобных результатов видео, следующим образом:
Я наконец запрашивал так много видео, какое видео, которое мы хотим найти? Здесь нам нужно определить пороговое значение, фильтруйте расстояние от сходства видео через этот порог, только видео, которое соответствует требованиям, будет отфильтроваться напрямую, а видео, которое не соответствует требованиям, отфильтровывается.
Здесь мы сначала определяем видео менее 10 в качестве того же видео, определение расстояния от 10 до 20 — это похожее видео, давайте посмотрим на результаты.
Установив пороговое значение, видео, которое соответствует требованиям, фильтруют.
среди них:
Первое поле: ID
Второе поле: Видеоид видеоид
Третье поле: расстояние гамма между видео
Четвертое поле: сходство текстовое описание
три. подводить итоги:
В этой статье мы исследуем, как создать поисковую систему видео с головы до хвоста. Первый шаг состоит в том, чтобы выбрать дескриптор изображения — мы используем чувствительность HASH CASH в качестве характеристического дескриптора видеокадров, извлекая каждый видеокадрный отпечаток пальцев, тем самым устанавливая нашу библиотеку видео отпечатков пальцев. На этой основе «Сходство» между двумя изображениями определяется расстоянием Hamming. Рассчитать расстояние, скрининг, в конечном итоге полученную видео информацию, которая соответствует нашим ожидаемым требованиям. Соедините вышеуказанные шаги вместе, создайте аналогичную поисковую систему видео.
Ahrefs создает свой поисковик и уже инвестировал в него $40 млн.
Зачем это компании19 Августа, 2021, 13:01
4253
В марте 2019 года основатель компании Ahrefs Дмитрий Герасименко рассказал о работе над новым амбициозным проектом — поисковой системой, которая будет отдавать создателям контента 90% прибыли. Его главная цель — сделать рынок, 92% которого принадлежит гиганту Google, справедливым. Уже в этом году компания обещает собрать рабочую версию поисковика и начать закрытое тестирование.
Журналист AIN.UA поговорила с Герасименко и узнала, почему Ahrefs решил создать свою поисковую систему, в чем суть ее бизнес-модели и как она планирует конкурировать с монополией Google.
Ahrefs — мини-поисковая система
Украинец Дмитрий Герасименко начал работать над будущим маркетинговым и SEO-сервисом Ahrefs в 2010 году. Сейчас в продуктовом портфеле компании — набор различных инструментов, которые в совокупности помогают десяткам тысяч клиентов по всему миру (Facebook, Netflix, Uber, украинские Rozetka, Macpaw, Reface среди них) получать больше трафика из поисковых систем. Годовой доход Ahrefs на июль 2021 года, по данным издания Tech in Asia, составил около $100 млн.
Дмитрий Герасименко. Фото — автора.Ahrefs быстро стал востребованным потому, что располагал уникальными данными, которые нужны SEO-специалистам, — ранее рассказывал AIN.UA Герасименко. Конкуренты обновляли свой индекс раз в месяц или реже, Ahrefs — каждые 15 минут. Теперь краулер компании — AhrefsBot индексирует интернет круглосуточно, и уже является вторым после GoogleBot по активности в интернете. В компании отмечают, что каждые 24 часа он индексирует 30 млн новых страниц.
Теперь краулер компании — AhrefsBot индексирует интернет круглосуточно, и уже является вторым после GoogleBot по активности в интернете. В компании отмечают, что каждые 24 часа он индексирует 30 млн новых страниц.
С помощью краулера Ahrefs создает цифровую библиотеку информации о веб-страницах, в которой хранятся данные о действующих сайтах: о том, как они ссылаются друг на друга и по каким ключевым словам ранжируются в результатах поиска, а также о том, как эти и многие другие метрики меняются со временем.
Такой же принцип работы лежит в основе поисковых систем. По сути, индекс, который создал Ahrefs — это их миниатюрная версия, только для поиска ссылок. Исходя из этого, создание собственного поисковика выглядело логичным шагом.
Альтернатива меркантильной GoogleЕжегодно Google на своем поисковом сервисе зарабатывает $100 млрд, неизменно оставаясь лидером на рынке — компании принадлежит 92%. Предложить что-то — отличное от поисковика монополиста — сложно, ведь он бесплатный и всем нравится, — так рассуждал Дмитрий Герасименко, когда раздумывал о его альтернативной версии. Затем основатель Ahrefs обратил внимание на Wikipedia, которая ежегодно вынуждена собирать деньги неравнодушных к проекту себе на инфраструктуру. Тогда он увидел нишу, в которой мог бы конкурировать с меркантильной Google — profit sharing. Дешевле и лучше, чем бесплатный поиск, может быть только тот, который делится прибылью с креаторами, — уверен предприниматель.
Затем основатель Ahrefs обратил внимание на Wikipedia, которая ежегодно вынуждена собирать деньги неравнодушных к проекту себе на инфраструктуру. Тогда он увидел нишу, в которой мог бы конкурировать с меркантильной Google — profit sharing. Дешевле и лучше, чем бесплатный поиск, может быть только тот, который делится прибылью с креаторами, — уверен предприниматель.
Мы хотим компенсировать работу создателей контента более справедливо, позволив людям заниматься тем, что им нравится и жить с этого. Мы ожидаем, что первый миллион пользователей в обозримом после релиза времени подтвердит наши ожидания.
Публично свою идею построить «справедливый» поисковик Герасименко анонсировал в 2019 году, тогда же начал собирать команду. Через год работы пандемия внесла свои коррективы в амбициозные планы Ahrefs, и компания сосредоточилась на основном продукте, а также выпустила Ahrefs Webmaster Tools для тех собственников бизнеса и маркетологов, у которых пока нет бюджета на профессиональные SEO инструменты, но есть потребность продавать через сайт.
К разработке команда смогла вернуться в начале этого года. Сейчас идет работа над мобильной версией поисковика для Android, дизайном, брендингом, а также активное продвижение идеи profit sharing. В ближайших планах у Ahrefs — серия silent launches, которая позволит собрать рабочую версию продукта и подготовиться к закрытому тестированию. На сегодня Ahrefs совокупно инвестировала в проект поисковой системы уже около $40 млн.
Бизнес-модель и монетизацияОсновными конкурентными преимуществами поисковика от Ahrefs перед системой Google будет модель profit sharing, при которой 90% прибыли будут выплачиваться всем креаторам, а также приватность персональных данных пользователей.
Бизнес-модель нашего поисковика создана поощрять ценный контент. Модель распределения прибыли 90/10 вознаграждает экспертов, независимых журналистов и увлеченных людей за их работу и подталкивает к генерированию высококачественного контента, из которого будет состоять любая страница результатов поиска, — объясняет Герасименко.

Соответственно, заработок поисковой системы Ahrefs составит 10%. Прибыль компания будет получать с рекламы и подписки на ее отсутствие. Предприниматель отмечает, что реклама будет релевантна поисковым запросам пользователя. Зарабатывать на сборе и продаже персональных данных третьим лицам поисковик не будет — в Ahrefs не используют сторонние поисковые индексы и файлы cookie.
В компании искренне верят в то, что бизнес-модель будущего поисковика произведет настоящую революцию: «В тот момент, когда креаторы осознают, что они могут получать реальные платежи от альтернативной поисковой системы, потому что их контент хорош и помогает другим людям — на рынке поисковиков начнется настоящий шторм.»
И небезосновательно. До анонса проекта Ahrefs, с компанией связались экс-топы Google. Они хотели изучить возможность использования данных сервиса в процессе разработки поисковика Neeva — он платный, в нем нет рекламы, а в основе его модели лежит profit sharing в соотношении 20/80.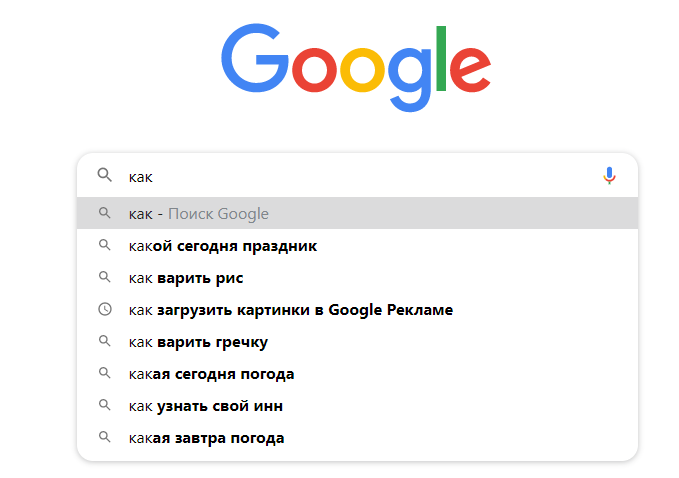 В Ahrefs будущим конкурентам отказали и убедились в правильности выбранного пути.
В Ahrefs будущим конкурентам отказали и убедились в правильности выбранного пути.
Читайте также:
Как создать собственную собственную поисковую систему Google 📀
Вы когда-нибудь хотели создать пользовательскую поисковую систему Google, которая ищет только определенные сайты? Вы можете легко сделать это с помощью инструмента Google Custom Search Engine. Вы можете добавить в закладки свою поисковую систему и поделиться ею с другими людьми.
Вы можете добавить в закладки свою поисковую систему и поделиться ею с другими людьми.
Этот трюк работает аналогично оператору сайта Google: оператор, но вам не придется вводить оператор каждый раз при поиске. Это особенно полезно, если вы хотите выполнить поиск по большому числу сайтов одновременно.
Создание системы пользовательского поиска
Чтобы начать работу, перейдите на страницу Google Custom Search Engine и нажмите кнопку «Создать пользовательскую поисковую систему». Для этого вам понадобится аккаунт Google — поисковая система будет сохранена в вашей учетной записи Google.
Введите имя и описание для своей поисковой системы — это может быть что угодно.
Сайты для поиска поле действительно важно. Здесь вы укажете список веб-сайтов, которые вы хотите найти. Например, если вы хотите выполнить поиск как howtogeek.com, так и microsoft.com, вы должны ввести:
howtogeek.com/*
microsoft.com/*
Символ * — это подстановочный знак, который может соответствовать чему угодно, поэтому символы / * указывают поисковой системе, чтобы искать все на обоих этих сайтах.
Есть более продвинутые вещи, которые вы можете сделать с этим полем — мы немного вернемся к этому.
После нажатия «Далее» вы можете указать стиль для своих результатов поиска и протестировать созданную вами поисковую систему.
После того, как вы довольны своей поисковой системой, нажмите кнопку «Далее» внизу страницы, и вы попадете на страницу с кодом вставки для своей поисковой системы.
Вы, вероятно, не веб-разработчик, поэтому вы захотите проигнорировать эту страницу. Вместо этого нажмите логотип Google Custom Search в верхней части страницы.
Чтобы перейти на страницу своей поисковой системы, щелкните ее имя в списке созданных вами поисковых систем.
Вы можете добавить эту страницу в закладки, чтобы получить доступ к своей поисковой системе. Вы также можете поделиться своей поисковой системой с кем-либо, отправив им полный URL-адрес, который отображается в адресной строке.
Уловки URL
Вам не нужно указывать весь веб-сайт при создании пользовательской поисковой системы.
Например, пользовательский поисковый движок выше ищет все области microsoft.com. Если мы проведем пример поиска, мы увидим, что есть полезная информация, поступающая из windows.microsoft.com а также support.microsoft.com, но результаты answers.microsoft.com (Форум поддержки Microsoft) не очень полезны.
Чтобы исключить answer.microsoft.com и включить другие поддомены, мы могли бы использовать следующий список URL-адресов при создании поисковой системы:
howtogeek.com/* windows.microsoft.com/* support.microsoft.com/*
Обратите внимание: нет возможности исключить конкретный подобъект — мы можем включать только те, которые мы хотим найти. Этот список будет искать только два поддомена на microsoft.com.
В этом списке можно указать несколько других типов URL-адресов:
- Одна страница: Вы можете определить только одну конкретную страницу, введя ее URL-адрес, например example.
 com/page.html, Это будет включать только одну веб-страницу в поисковой системе.
com/page.html, Это будет включать только одну веб-страницу в поисковой системе. - Часть веб-сайта: Вы можете использовать символ * другими способами. Например, URL support.microsoft.com/kb/* будут искать только статьи Microsoft Knowledge Base. Использование URL-адреса example.com/*word* будет искать все страницы на example.com, которые имеют слово в своих URL-адресах.
 com/page.html, Это будет включать только одну веб-страницу в поисковой системе.
com/page.html, Это будет включать только одну веб-страницу в поисковой системе.Вы можете продолжить тонкую настройку поисковой системы, пока не будете довольны результатами, нажав вернуться к шагу 1 ссылку, изменение URL-адресов, а затем выполнение другого тестового поиска.
Как только вы закончите, вы даже можете добавить свою систему поиска в панель поиска своего браузера.
Tweet
Share
Link
Plus
Send
Send
Pin
Создание программируемой поисковой системы | Разработчики Google
Существует два способа создания программируемой поисковой системы:
Самый простой способ начать работу с программируемой поисковой системой — создать базовую поисковую систему с помощью панели управления. Затем вы можете загрузить XML-файлы движка и изменить их, чтобы добавить дополнительные настройки.
Поскольку вы экспериментируете и выясняете некоторые основные понятия, потратьте всего пару минут на создание своей первой поисковой системы.Сделайте это простым, чтобы вы могли следить за тем, что происходит, когда вы начинаете тестировать его. Вы всегда можете изменить его позже.
Затем вы можете загрузить XML-файлы движка и изменить их, чтобы добавить дополнительные настройки.
Поскольку вы экспериментируете и выясняете некоторые основные понятия, потратьте всего пару минут на создание своей первой поисковой системы.Сделайте это простым, чтобы вы могли следить за тем, что происходит, когда вы начинаете тестировать его. Вы всегда можете изменить его позже.
Определение программируемой поисковой системы в панели управления
Для создания программируемой поисковой системы:
- Войдите в панель управления, используя свою учетную запись Google (получите учетную запись, если у вас ее нет).
- В разделе сайтов для поиска добавьте страницы, которые вы хотите включить в свою поисковую систему. Вы можете включать любые сайты, которые хотите, а не только те, которые принадлежат вам.Вы можете включить URL-адреса всего сайта или URL-адреса отдельных страниц. Вы также можете использовать шаблоны URL.
- Имя вашей поисковой системы будет автоматически сгенерировано на основе выбранных вами URL-адресов. Вы можете изменить это имя в любое время.
- Выберите язык вашей поисковой системы. Это определяет язык кнопок и других элементов дизайна вашей поисковой системы, но не влияет на фактические результаты поиска.
- Щелкните Создать .
 Вы также можете использовать шаблоны URL.
Вы также можете использовать шаблоны URL.Ваша базовая поисковая система готова к использованию! Чтобы просмотреть дополнительные параметры конфигурации, перейдите в Панель управления.Панель управления также имеет окно предварительного просмотра, которое позволяет вам тестировать и настраивать результаты поиска.
Чтобы узнать больше о параметрах, доступных в панели управления, посетите Справочный центр программируемой поисковой системы. Чтобы добавить дополнительные параметры (например, фильтрацию или порядок результатов) и дополнительно настроить поисковую систему с помощью файлов конфигурации XML, см. Руководство разработчика.
Руководство разработчика.
Использование двигателя
После того, как вы определили свою поисковую систему, к ней можно получить доступ двумя способами:
- Домашняя страница программируемой поисковой системы, размещенная в Google — вы можете найти общедоступный URL-адрес для вашего домашняя страница двигателя на вкладке Setup > раздел Public URL панели управления и поделитесь им со своими пользователями.
- Окно поиска на вашем веб-сайте. Если вы встроите окно поиска в свою веб-страницу, ваш пользователи могут выполнять поиск с вашего веб-сайта.
Далее…
Перейти к реализации окна поиска.
Создание программируемой поисковой системы с файлами конфигурации | Разработчики Google
На этой странице представлены основные концепции файлов конфигурации программируемой поисковой системы.
- Обзор
- Что находится в программируемой поисковой системе
- Как компоненты работают вместе
- Создание поисковой системы
- Редактирование файлов программируемой поисковой системы
- Выбор правильного формата
Обзор
Если панель управления не обеспечивает необходимого уровня настройки, рассмотрите возможность использования формата Programmable Search XML или TSV, который обеспечивает больший контроль, гибкость и доступ к более мощным функциям.
Чтобы использовать JSON API пользовательского поиска, начните с создания базовой поисковой системы с помощью панели управления программируемой поисковой системы. После того, как вы создали свою поисковую систему, вы можете загрузить свои аннотации и XML-файлы контекста с вкладки Advanced панели управления.
Основы XML
Extensible Markup Language или XML — это язык разметки общего назначения. Это текст с тегами, который вы можете прочитать. Например, XML-формат программируемого поиска включает следующие теги: и .
Как и в случае с любым файлом XML, спецификации вашей программируемой поисковой системы должны соответствовать синтаксису XML ( ) и быть правильно сформированными. XML имеет следующие правила:
- XML требует, чтобы перед вашими тегами верхнего уровня стояло объявление XML (
 0"?>
0"?> - Все ваши элементы должны иметь открывающий тег (
- Все ваши теги должны быть правильно вложены. У вас не может быть XML-кода вида:
арахисовое масло арахисовое масло - XML чувствителен к регистру, поэтому внимательно следите за использованием заглавных букв и написанием тегов в инструкциях.
- Все значения атрибутов должны быть заключены в двойные кавычки (
- Все атрибуты должны быть определены в открывающем теге (

Вы можете писать заметки для себя, используя теги комментариев ( ), и Программируемая поисковая система не будет анализировать эту строку текста как код XML. Помимо написания напоминаний или описания, вы можете использовать комментарии, чтобы временно вывести из строя некоторый XML-код (возможно, потому, что вы хотите поэкспериментировать с определенными эффектами или хотите устранить неполадки).Однако эти комментарии не сохраняются в файлах, загружаемых из Панели управления. Если вы хотите сохранить комментарии, вам следует сохранить копию XML-файлов с комментариями даже после их загрузки в панель управления.
Для создания и редактирования XML-файлов можно использовать простой текстовый редактор. Просто сохраните текстовый файл с расширением .xml (например, cse_badminton.xml ).
Основы ТСВ
XML-формат программируемого поиска несложно использовать, но если вам неудобно его использовать, вы можете использовать формат программируемой поисковой системы TSV (значения, разделенные табуляцией). Как следует из названия, файл TSV представляет собой обычный текстовый файл, который включает строки полей (строк символов), которые отделены друг от друга одиночными позициями табуляции. Вы можете использовать простой текстовый редактор или редактор электронных таблиц для создания и редактирования файлов TSV. Просто сохраните текстовый файл с расширением
Как следует из названия, файл TSV представляет собой обычный текстовый файл, который включает строки полей (строк символов), которые отделены друг от друга одиночными позициями табуляции. Вы можете использовать простой текстовый редактор или редактор электронных таблиц для создания и редактирования файлов TSV. Просто сохраните текстовый файл с расширением .tsv (например, cse_bicycles.tsv ).
Наверх
Что находится в программируемой поисковой системе
Программируемая поисковая система состоит из двух основных компонентов, каждый из которых управляется файлом XML:
Мы не рекомендуем создавать любой из этих файлов с нуля.Вместо этого загрузите их с вкладки Advanced панели управления. Когда вы загружаете аннотации из Панели управления, вы получаете единый файл аннотаций, который объединяет все аннотации из разных поисковых систем в вашей учетной записи.
В дополнение к этим основным компонентам поисковая система также может иметь следующие вспомогательные файлы:
- Рекламные акции : XML-файл рекламных акций содержит ряд настраиваемых результатов, которые вызываются предварительно определенным набором условий запроса.Когда пользователь вводит поисковый запрос, который точно соответствует одному из условий вашего запроса, продвижение появляется в верхней части страницы. Вы можете использовать рекламные акции, чтобы напрямую отвечать на запросы ваших пользователей, направлять их к важной информации или направлять их на веб-страницы, которые не находятся в верхней части страницы результатов, но являются особенно актуальными. В Панели управления промоакции определяются на вкладке Акции . Больше информации об акциях.
- Синонимы : XML-файл синонимов расширяет запросы ваших пользователей, включая варианты поискового запроса.Например, если ваш пользователь ищет «обезьяна», поисковая система также ищет «обезьяна» и «обезьяна». В Панели управления синонимы определяются на вкладке Synonyms . Подробнее о синонимах.
 В Панели управления синонимы определяются на вкладке Synonyms . Подробнее о синонимах.
В Панели управления синонимы определяются на вкладке Synonyms . Подробнее о синонимах.Как компоненты работают вместе
XML-файл контекста не указывает используемый файл аннотаций, а XML-файл аннотаций не ссылается на файл контекста. Программируемая поисковая система использует меток для связывания контекста и аннотаций.XML-файл контекста включает метки, идентифицирующие поисковую систему, и каждая аннотация, указанная в XML-файле аннотаций, помечена одной или несколькими метками, идентифицирующими поисковую систему (ы), к которой она принадлежит. Если вы измените имя метки в контексте файл, вы должны изменить все аннотации, которые были помечены этой меткой.
Хотя вы можете загружать несколько файлов аннотаций, при их загрузке через панель управления Программируемая поисковая система объединяет все ваши файлы аннотаций в один файл аннотаций.Наличие единого файла аннотаций для нескольких поисковых систем (с их собственными отдельными файлами контекста) упрощает вашу работу и устраняет дублирование. Он позволяет перечислять сайты только один раз, но при этом иметь возможность настраивать один и тот же сайт для различных поисковых систем. Например, одна поисковая система может ограничить поиск некоторыми сайтами, другая может удалить эти сайты, а третья может продвигать эти сайты.
Он позволяет перечислять сайты только один раз, но при этом иметь возможность настраивать один и тот же сайт для различных поисковых систем. Например, одна поисковая система может ограничить поиск некоторыми сайтами, другая может удалить эти сайты, а третья может продвигать эти сайты.
контекст.xml
Вот пример файла context.xml, содержащего метки, идентифицирующие поисковую систему, к которой он применяется:
<Фоновые метки>
аннотаций.XML
Вот пример файла аннотаций, показывающий, как каждый сайт (аннотация) связан с ярлыком:
<Аннотация about="code.google.com/*" score="1"> <Ярлык name="_cse_hwbuiarvsbo"/>
Наверх
Создание расширенных программируемых поисковых систем
Создание расширенных движков включает следующие шаги:
- Определите формат, соответствующий вашим потребностям.
- Определите характеристики вашей поисковой системы.
- Сообщить программируемой поисковой системе, на каких сайтах искать.
- Сообщите программируемой поисковой системе, как ранжировать результаты поиска.

Редактирование файлов программируемой поисковой системы
Для работы с файлом XML загрузите спецификацию XML с вкладки Advanced панели управления. Не запускайте файл с нуля. Сделайте следующее:
- Загрузите файл контекста или файл аннотаций с вкладки Advanced панели управления.Нажмите кнопку Скачать в соответствующем разделе.
Вы можете загрузить файлы на жесткий диск или просмотреть их в другом окне браузера или на вкладке.
- Используйте браузер для сохранения файла XML или скопируйте текст XML с веб-страницы и вставьте его в свой любимый текстовый редактор.
Используйте текстовый редактор, который может обрабатывать окончания строк в стиле UNIX (WordPad, Emacs и TextMate работают, NotePad — нет). Неважно, как вы назовете файл, если вы сохраните его с расширением файла
.xml(например,cx_global.xml) - Сделайте резервную копию загруженного файла на случай, если ваша отредактированная версия не будет работать должным образом, и вам придется вернуться к предыдущей версии.
Если вы не сделаете копию и отредактированная вами версия не будет работать должным образом, вам потребуется отладить файл или заново создать поисковую систему. Не смешно.
- Отредактируйте файл XML и сохраните его. Убедитесь, что ваш текстовый редактор сохраняет файл как текстовый документ Unicode, а не какой-либо другой формат файла.
- Загрузите файл в соответствующий раздел на вкладке Advanced .
 Неважно, как вы назовете файл, если вы сохраните его с расширением файла
Неважно, как вы назовете файл, если вы сохраните его с расширением файла Выбор правильного формата
Прежде чем приступить к созданию программируемой поисковой системы, определите, какой формат лучше всего соответствует вашим потребностям. Вы не хотите выбирать формат, который является более мощным и сложным, чем то, что вам нужно, и вы не хотите использовать тот, который вы быстро перерастете.
Вы не хотите выбирать формат, который является более мощным и сложным, чем то, что вам нужно, и вы не хотите использовать тот, который вы быстро перерастете.
Используйте следующую таблицу, чтобы выбрать подходящий формат.
| Для создания | Использовать | Потому что | Ограничения | Дополнительная информация |
|---|---|---|---|---|
| Одна или несколько поисковых систем с небольшим количеством сайтов | Панель управления | Вы можете быстро создать свою программируемую поисковую систему, заполнив текстовые поля вместо создания файлов с помощью текстового редактора и загрузки файлов. | Панель управления в основном полезна для ознакомления с программируемой поисковой системой и создания поисковых систем с несколькими сайтами. Если вы действительно хотите настроить свою поисковую систему или добавить большое количество сайтов, вы можете найти следующие ограничения:
| Начало работы |
| Сложные поисковые системы, использующие множество сайтов, каналы или созданные программным путем | Контекстный файл и файлы аннотаций | Файлы Programmable Search Engine дают вам более высокий уровень контроля над вашими поисковыми системами и значительно упрощают задачи по определению сайтов и управлению ими. Несмотря на то, что вы планируете создать свою поисковую систему с использованием файлов контекста и аннотаций, все же рекомендуется ознакомиться с панелью управления. Вкладка Preview позволяет мгновенно просматривать результаты ваших экспериментов. | Чем больше вы настраиваете свою поисковую систему, тем сложнее она становится. Вы должны изучить программируемые элементы поиска и атрибуты, которые несложно подобрать, но они требуют от вас некоторого времени. Вам придется прочитать остальную часть руководства разработчика, которое, к сожалению, не самый интересный материал для чтения. | Контекст: определение спецификаций и аннотаций поисковой системы: выбор сайтов |


Наверх
Как создать программное обеспечение поисковой системы для вашего бизнеса?
Шаг 4. Определение структуры индекса
При создании программного обеспечения поисковой системы необходимо определить структуру индекса.Несмотря на то, что это своего рода база данных, важно помнить, что это не основное хранилище данных и не реляционная база данных. Структура индекса должна быть организована так, чтобы это было удобно для поиска. Хранящиеся там данные также должны быть единственными, необходимыми для поиска.
Шаг 5. Настройка обновления данных
Важно отправлять обновленную информацию из базы данных в поисковую систему. Некоторые движки получают эту информацию непосредственно из базы данных, тогда как в других случаях вам нужно добавить специальный код, который выполняет эту задачу.Поисковая система более эффективна, когда обновления редки. Так что, если запросов десятки в минуту, лучше настроить обновление индекса раз в несколько минут. Это позволит отправлять многочисленные обновления вместе.
Разработчики, работающие с Elastic и использующие Python, могут использовать службу Github и Celery для планирования обновления индекса.
Шаг 6. Начните делать запросы
На этом этапе ваша поисковая система работает хорошо и может не требовать дополнительной работы. Поэтому можно начинать делать запросы.
Можно использовать разные алгоритмы ранжирования, применяющие данные о частоте слова в текстах и движок знает, что в запросе «кардиологические услуги» главное слово, например, кардиология. Вы можете использовать различные алгоритмы ранжирования, применяющие данные о частоте слов в текстах. Так, во фразе «кардиологические услуги» движок может выделить слово «кардиология» как основное. Следовательно, результаты, соответствующие обоим словам, идут первыми. Затем будут те, которые соответствуют «кардиологии», и другие, которые соответствуют «услугам».
Вы можете использовать различные алгоритмы ранжирования, применяющие данные о частоте слов в текстах. Так, во фразе «кардиологические услуги» движок может выделить слово «кардиология» как основное. Следовательно, результаты, соответствующие обоим словам, идут первыми. Затем будут те, которые соответствуют «кардиологии», и другие, которые соответствуют «услугам».
При работе с Elastic мы предпочитаем Elastic DSL. На это есть несколько причин:
- Умеет строить индекс автоматически, что очень удобно на этапе прототипирования.
- Его API на основе http удобен для пользователя и позволяет программировать на любом языке программирования.
- Доступно множество инструментов, таких как Kibana и Logstash.
- Amazon предлагает Elastic как услугу, упрощающую запуск и администрирование поисковой системы.
На этом первый этап создания дизайна поисковой системы заканчивается и начинается второй.
Второй этап
Этот этап связан с другими процессами, которые помогают сделать вашу поисковую систему более эффективной.
Шаг 7. Назначить ответственного за сбор данных
В первую очередь необходимо нанять специалиста, специализирующегося на базах данных. Несмотря на то, что настройка поиска является технической задачей, технический специалист может не понять, какие данные нужны пользователям и зачем.Это когда специалист по данным приходит на помощь.
Шаг 8. Просмотр истории поиска пользователя
Важно выяснить, подходят ли результаты вашей поисковой системы для определенных запросов. Это можно сделать, проверив историю поиска пользователя, выбрав первую десятку запросов по популярности и предоставив эксперту проверить их релевантность.
Шаг 9. Сформулируйте, какие документы ожидаются в результате
Далее необходимо сформулировать, какие документы потребуются в результате.Это когда вам нужно подумать о том, как вы, как человек, будете обрабатывать такие запросы. Например, вы работаете над научными статьями и в результате можете получить следующее:
- Совпадения в названии статьи важнее, чем совпадения в тексте.
- Совпадения в тексте более важны, чем совпадения в ссылках.
- Совпадения имени автора более важны, чем совпадения в тексте и в списке цитат.
- Имя и фамилию нужно искать вместе, а не по отдельности.
- Слово «вакцина» обычно пишется с ошибкой как «вакцина», и этот запрос также необходимо обработать.

Шаг 10. Выяснение источника проблем
Последний шаг — выяснить, почему возникают проблемы, если они есть. Полезным может оказаться чтение информации о том, как устроен поисковый движок и методы его устранения. Иногда вам может потребоваться изменить основные принципы, чтобы найти проблему. Однако рано или поздно проблемы, требующие режима отладки и детального анализа, появятся.
В зависимости от правил вашей поисковой системы вам могут понадобиться различные способы исправления запроса, которые всегда будут интерактивными. Итак, определите проблемы, разберитесь с ними и постарайтесь получить удовольствие от процесса.
Если вы работаете с Elastic, есть несколько советов, которые помогут вам создать поисковую систему для вашего бизнеса:
- Прочтите обо всех анализаторах. Обычно используются только два или три из них, но вам нужно знать об остальных.
- Понять, как работают составные запросы, особенно запрос Bool.Дополнительную информацию об этом можно найти здесь.
 Обычно используются только два или три из них, но вам нужно знать об остальных.
Обычно используются только два или три из них, но вам нужно знать об остальных.Используйте соответствующие веса и усилители. Есть замечательная книга «Relevant Search With Applications for Solr and Elasticsearch» Дуга Тернбулла и Джона Берримана, которая может оказаться полезной.
Создание поисковой системы с нуля
В предыдущем сообщении из этой серии мы рассказали о нашем путешествии по созданию независимой альтернативной поисковой системы. Если вы еще не читали ее, мы настоятельно рекомендуем сначала ознакомиться с ней!
Ни для кого не секрет, что поиск Google — один из самых прибыльных бизнесов на планете.Учитывая, что ежеквартальные доходы Alphabet Inc. превышают 40 миллиардов долларов [1] и большая часть этого дохода обусловлена доходами от рекламы в поисковых свойствах Google, может быть немного удивительно видеть отсутствие конкуренции с Google в этой области [ 2] . Мы в Cliqz считаем, что это частично связано с проблемой веб-поиска , загружающей : входные барьеры в этой области настолько велики, что самые большие и самые успешные компании в мире, имеющие ресурсы для решения этой проблемы, уклоняются от нее.В этом посте предпринята попытка подробно описать проблему начальной загрузки и объяснить подход Cliqz к ее преодолению. Но давайте сначала начнем с определения проблемы поиска.
Мы в Cliqz считаем, что это частично связано с проблемой веб-поиска , загружающей : входные барьеры в этой области настолько велики, что самые большие и самые успешные компании в мире, имеющие ресурсы для решения этой проблемы, уклоняются от нее.В этом посте предпринята попытка подробно описать проблему начальной загрузки и объяснить подход Cliqz к ее преодолению. Но давайте сначала начнем с определения проблемы поиска.
Ожидание от современной поисковой системы состоит в том, чтобы быть в состоянии ответить на любой вопрос пользователя с помощью наиболее релевантных документов, которые существуют по теме в Интернете. Ожидается, что поисковая система будет невероятно быстрой, но пока мы можем игнорировать это. С риском чрезмерного упрощения мы можем определить задачу веб-поиска как вычисление соответствия содержания каждого документа-кандидата в отношении вопроса пользователя ( запрос ), вычисление текущей популярности документа и объединение этих оценок. с некоторой эвристикой.
Оценка соответствия содержимого показывает, насколько хорошо данный документ соответствует заданному запросу. Это может быть так просто, как точное совпадение ключевых слов, где счет пропорционален количеству запросов слов, присутствующих в документе:
3 query| Query | Avengers |
| document | avengers endgame imdb |
Если бы мы могли оценить все наши документы таким образом, отфильтровать те, которые содержат все слова запроса, и отсортировать их на основе некоторой меры популярности , у нас была бы функционирующая, хотя и игрушечная , поисковый движок.Давайте посмотрим на проблемы, связанные с созданием системы, способной обрабатывать 90 385 только 90 386 сценариев точного соответствия ключевых слов в веб-масштабе, что составляет минимум 90 014 требований современной поисковой системы.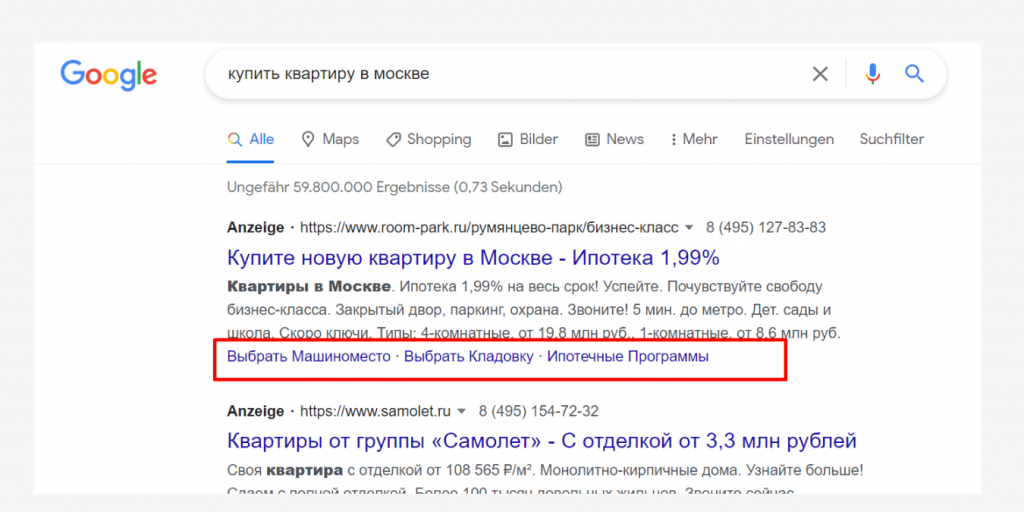
Согласно исследованию, опубликованному на worldwebsize.com, консервативная оценка числа документов, проиндексированных Google, составляет около 60 миллиардов.
1. Затраты на инфраструктуру, связанные с обслуживанием массивного, постоянно обновляемого инвертированного индекса в масштабе.
Если рассматривать только текстовое содержание этих документов, это представляет собой как минимум петабайт данных. Линейное сканирование этих документов технически невозможно, поэтому хорошо известное решение этой проблемы — построить инвертированный индекс . Крупные поставщики облачных услуг, такие как Amazon, Google или Microsoft, могут предоставить нам инфраструктуру, необходимую для обслуживания этой системы, но ее эксплуатация по-прежнему будет стоить миллионы евро каждый год. И помните, это только для того, чтобы начать работу .
2. Инженерные расходы, связанные с сканированием и очисткой Интернета в масштабе.
Искатель [3] Инфраструктура , необходимая для поддержания этих данных в актуальном состоянии при обнаружении новых документов в Интернете, является еще одним серьезным препятствием. Сканер должен быть вежливым (некоторая форма ограничения скорости на уровне домена), быть географически распределенным, обрабатывать многоязычные данные и агрессивно избегать ссылочных ферм и ловушек пауков [4] .Огромная часть доступной для сканирования сети [5] — это спам и дублированный контент; очистка этих данных — еще одна большая инженерная работа.
Сканер должен быть вежливым (некоторая форма ограничения скорости на уровне домена), быть географически распределенным, обрабатывать многоязычные данные и агрессивно избегать ссылочных ферм и ловушек пауков [4] .Огромная часть доступной для сканирования сети [5] — это спам и дублированный контент; очистка этих данных — еще одна большая инженерная работа.
Кроме того, значительная часть сети отрезана от вас, если ваш краулер не известный . У Google есть огромное конкурентное преимущество в этом отношении, многие владельцы сайтов разрешают только GoogleBot (и, возможно, BingBot ), что делает чрезвычайно утомительным процесс попадания неизвестного поискового робота в белый список на этих сайтах.Нам пришлось бы обрабатывать их в каждом конкретном случае, зная, что привлечение внимания сайтов не гарантируется.
3. Вам нужны пользователи, чтобы привлечь больше пользователей (Catch-22)
Даже если предположить, что нам удастся проиндексировать и обслуживать эти страницы, измерение и улучшение релевантности поиска является сложной задачей. Ручная оценка результатов поиска может помочь нам начать работу, но нам нужны реальные пользователи, чтобы измерять изменения релевантности поиска, чтобы быть конкурентоспособными.
Ручная оценка результатов поиска может помочь нам начать работу, но нам нужны реальные пользователи, чтобы измерять изменения релевантности поиска, чтобы быть конкурентоспособными.
4.Поиск нужных страниц среди всего шума в сети.
Самая большая проблема в поиске, удаление шума . Сеть настолько обширна, что на любой вопрос можно найти ответ. Способность отбрасывать шум в процессе и отличает бесполезную поисковую систему от отличной. Мы обсудили эту тему с некоторой строгостью в нашем предыдущем посте, предоставив обоснование того, почему использование журналов запросов — это более разумный способ избавиться от шума в Интернете. Мы также подробно писали о том, как ответственно собирать эти журналы с помощью Human Web.Не стесняйтесь проверять эти посты для получения дополнительной информации.
Пары запрос/URL, обычно называемые журналами запросов, часто используются поисковыми системами для оптимизации их ранжирования, а поисковая оптимизация — для оптимизации входящего трафика. Вот образец из набора данных журналов запросов AOL [6] .
Вот образец из набора данных журналов запросов AOL [6] .
| Запрос | нажал URL |
|---|
Мы можем использовать эти журналы запросов для построения модели страницы за пределами ее содержимого, которые мы называем моделями страниц . Пример ниже взят из усеченной версии модели страницы, которая у нас есть на данный момент для одной конкретной статьи CNN о запуске Tesla Cybertruck. Оценки, связанные с запросом, рассчитываются как функция его 90 385 частоты 90 386 (т.е. недавно созданные журналы запросов являются лучшим показателем релевантности).
Оценки, связанные с запросом, рассчитываются как функция его 90 385 частоты 90 386 (т.е. недавно созданные журналы запросов являются лучшим показателем релевантности).
{
"запросы": [
[
"тесла кибертрак",
0,5111737168808949
],
[
"грузовик Тесла",
0,4108341455983614
],
[
"новая машина тесла",
0,0227844730764
],
...
...
...
[
"забрать теслу",
0,020538972510725183
],
[
"новый грузовик тесла",
0,019462471432017632
],
[
"кибер грузовик Тесла цена",
0,006587470155023614
],
[
"сколько стоит кибергрузовик",
0.003764268660013494
],
...
...
...
[
"открытие кибергрузовика",
0,0016181605575564585
],
[
"новый Tesla Cybertruck",
0,0016181605575564585
],
[
"представление кибергрузовика",
0,0016181605575564585
]
]
}
У нас есть сотни запросов на странице, но даже этот небольшой пример должен дать вам интуитивное представление о том, как модель страницы помогает нам обобщать и понимать содержимое страницы. Даже без фактического текста страницы модель страницы предполагает, что статья посвящена новому автомобилю Tesla под названием Cybertruck ; в нем подробно описывается событие открытия и содержится потенциальная информация о ценах.
Даже без фактического текста страницы модель страницы предполагает, что статья посвящена новому автомобилю Tesla под названием Cybertruck ; в нем подробно описывается событие открытия и содержится потенциальная информация о ценах.
Чем больше уникальных запросов мы сможем собрать для страницы, тем лучше будет наша модель страницы. Наше использование Human Web также позволяет нам собирать анонимную статистику на странице, часть которой показана ниже. Эта структура показывает популярность страницы в разных странах в данный момент времени, что используется как сигнал популярности. Мы видим, что он очень популярен в Великобритании, меньше в Австралии и т. д.
"counters": { "ар": 0,003380009657170449, "в": 0.016
8285852245, «а.е.»: 0,11492032834379527, "быть": 0,02704007725736359, ... ... ... "бр": 0,012071463061323033, "сп": 0,0014485755673587638, "ч": 0,008691453404152583, "де": 0,06422018348623854, "дк": 0,028971511347175277, "фр": 0,025108643167551906, .
 ..
...
...
"гб": 0,3355866731047803,
"это": 0,00772573635924674,
"джп": 0,005311443746982134,
"ru": 0.0159343312409464,
"се": 0,0294543698696282,
"ua": 0.012071463061323033
...
}
..
...
...
"гб": 0,3355866731047803,
"это": 0,00772573635924674,
"джп": 0,005311443746982134,
"ru": 0.0159343312409464,
"се": 0,0294543698696282,
"ua": 0.012071463061323033
...
}
Теперь, когда мы поняли, как генерируются модели страниц, мы можем начать пошаговый процесс поиска.Мы можем разбить этот процесс на несколько этапов, как описано ниже.
Версия TL;DR
Это общий обзор, если вы хотите узнать, чем отличается поиск Cliqz.
- Наша модель веб-страницы основана только на запросах . Эти запросы могут быть либо наблюдаемыми в логах запросов, либо могут быть синтетическими , т.е. мы их генерируем. Другими словами, на этапе отзыва мы не пытаемся сопоставить слова запроса непосредственно с содержимым страницы.Это решающий дифференцирующий фактор — это причина того, что мы можем создать поисковую систему с гораздо меньшими ресурсами по сравнению с нашими конкурентами.
- Учитывая запрос, мы сначала ищем похожих запросов, используя множество методов сопоставления на основе ключевых слов и векторов слов.
- Мы выбираем наиболее похожие запросы и получаем связанных с ними страниц.
- На этом этапе мы начинаем рассматривать содержание страницы.Мы используем его для извлечения признаков при ранжировании, фильтрации и создании динамических фрагментов.

1. Этап исправления запроса
Когда пользователь вводит запрос в наше окно поиска, мы сначала выполняем некоторые возможные исправления. Это включает в себя не только некоторую нормализацию, но и расширения и исправления заклинаний, если это необходимо. Этим занимается служба, которая называется , предлагаю — скоро у нас будет пост с подробным описанием ее внутренней работы.Пока можно предположить, что сервис предоставляет нам список возможных альтернатив пользовательскому запросу.
2.
 Этапы отзыва и уточнения
Этапы отзыва и уточненияТеперь мы можем приступить к созданию ядра поисковой системы. Наш индекс содержит миллиардов страниц; задача поиска состоит в том, чтобы найти N , обычно около 50, наиболее релевантных страниц для данного запроса. Мы можем разделить эту проблему на 2 части: этапы отзыва и этапы точности .
Этап отзыва включает в себя сужение миллиардов страниц до гораздо меньшего набора, скажем, пятисот страниц-кандидатов , при попытке включить в этот набор как можно больше релевантных страниц. На этапе точности выполняются более интенсивные проверки этих страниц-кандидатов, чтобы отфильтровать первые N страниц и принять решение об окончательном порядке.
2.1 Этап отзыва
Обычный метод, используемый для выполнения эффективного поиска при поиске, заключается в построении инвертированного индекса.Вместо того, чтобы строить слова на странице как ключей , мы используем в качестве ключей энграммы запросов на модели страницы. Это позволяет нам построить гораздо меньший и менее зашумленный индекс.
Это позволяет нам построить гораздо меньший и менее зашумленный индекс.
Мы можем выполнять различные типы сопоставления по этому индексу:
- Точное совпадение на основе слов : Мы ищем точный пользовательский запрос в нашем индексе и извлекаем связанные страницы.
- Частичное совпадение на основе слов : мы разбиваем пользовательский запрос на энграмм и извлекаем связанные страницы для каждой из них.
- Частичное совпадение на основе синонимов и основ : Мы определяем слов в пользовательском запросе и извлекаем связанные страницы для каждой из его энграмм. Мы также можем заменить слова в запросе их синонимами и повторить операцию. Должно быть ясно, что этот подход, если не использовать его с осторожностью, может быстро привести к взрыву страниц-кандидатов.
Этот подход отлично работает во многих случаях, например. когда мы хотим сопоставить номера моделей, имена, коды, редких слов . В основном, когда токен запроса является обязательным, что невозможно узнать заранее. Но это также может привести к большому количеству шума, как показано ниже, потому что нам не хватает семантического понимания запроса.
В основном, когда токен запроса является обязательным, что невозможно узнать заранее. Но это также может привести к большому количеству шума, как показано ниже, потому что нам не хватает семантического понимания запроса.
| Запрос | Солдат Fortune Game | PS2 Game Soldier Fortune | Документ 2 | Солдат Fortune Games |
| Документ 3 (Shall) | Fortune Games | |||
| Документ 4 (Shall) 5 | Soldier Games |
Дополнительный подход к вспомогательному вспомогательному составлению этих запросов в векторное пространство и совпадение это многомерное пространство.Каждый запрос представляется вектором размерности K , в нашем случае 200, и мы находим ближайших соседей к пользовательскому запросу в этом векторном пространстве.
Преимущество этого подхода в том, что он может семантически совпадать. Но это также может привести к шуму с агрессивным семантическим сопоставлением, как показано ниже. Этот метод также может быть ненадежным, если запрос содержит редкие слова, такие как номера моделей или названия, поскольку их соседи в векторном пространстве могут быть случайными.
| запрос | солдат фортуны игры |
| документ 1 | наемник андроид |
| документ 2 | соф игры |
| документ 3 | солдат удачи playstation |
| документ 4 (шум) | защита богатства игра |
Мы обучаем эти векторы запросовОни обучены на миллиардах < хороших запросов , плохих запросов > пар, собранных из наших данных, и используют Byte-Pair-Encoding реализацию SentencePiece [7] для решения проблемы с пропущенными словами в нашем словаре. .
.
Затем мы строим индекс с миллиардами этих векторов запросов, используя Granne [8] , наше собственное решение для сопоставления векторов с эффективным использованием памяти. Скоро в этом блоге у нас будет пост о внутренностях Granne, обязательно обратите на него внимание, если тема представляет интерес.
Мы также генерируем синтетических запросов из заголовков , описаний , слов в URL-адресе и фактического содержания страницы. Они по определению более шумные, чем журналы запросов, захваченные HumanWeb. Но они необходимы; в противном случае новые страницы с новым содержимым нельзя было бы получить.
Какую модель мы предпочитаем? Потребность в семантике сильно зависит от контекста запроса, который, к сожалению, трудно узнать априори .Рассмотрим следующий пример:
| Сценарий 1 | какой рост у людей в Стокгольме? | какой рост у людей в швеции? |
| Сценарий 2 | ресторанов в Стокгольме | ресторанов в Швеции |
Семантическое сопоставление в Scenario 1 полезно для получения хороших результатов, но сопоставление Scenario 2 может дать нерелевантные результаты. Как ключевые, так и векторные модели имеют свои сильные и слабые стороны. Объединение их в ансамбль вместе с несколькими вариациями этих моделей дает нам гораздо лучшие результаты, чем любая конкретная модель в отдельности. Как и следовало ожидать, не существует серебряной пули модели или алгоритма , которые делают свое дело.
Как ключевые, так и векторные модели имеют свои сильные и слабые стороны. Объединение их в ансамбль вместе с несколькими вариациями этих моделей дает нам гораздо лучшие результаты, чем любая конкретная модель в отдельности. Как и следовало ожидать, не существует серебряной пули модели или алгоритма , которые делают свое дело.
Этап отзыва объединяет результаты ключевых слов и векторных индексов. Затем он оценивает их с помощью некоторых базовых эвристик, чтобы сузить наш набор страниц-кандидатов.Учитывая строгие требования к задержке, этап отзыва спроектирован так, чтобы быть как можно более быстрым, обеспечивая при этом приемлемое количество отзывов.
2.2 Стадия точности
Верхние страницы из стадии отзыва переходят на стадию точности. Теперь, когда мы имеем дело с меньшим набором страниц, мы можем подвергнуть их дополнительной проверке. Хотя в более ранних версиях поиска Cliqz для этого использовался эвристический подход, теперь мы используем градиентные деревья решений [9] , обученные сотням эвристических и машинных функций. Они извлекаются из самого запроса, содержимого страницы и функций, предоставляемых Human Web. Деревья обучаются на результатах поиска, оцененных вручную нашей командой качества поиска.
Они извлекаются из самого запроса, содержимого страницы и функций, предоставляемых Human Web. Деревья обучаются на результатах поиска, оцененных вручную нашей командой качества поиска.
3. Этап фильтрации
Страницы, прошедшие этап точности, теперь подвергаются дополнительным проверкам, которые мы называем фильтрами . Вот некоторые из них:
- Фильтр дедупликации : Этот фильтр улучшает разнообразие результатов, удаляя страницы с дублированным или похожим содержимым.
- Языковой фильтр : Этот фильтр удаляет страницы, которые не соответствуют языку пользователя или нашему списку допустимых языков.
- Фильтр для взрослых : Этот фильтр используется для контроля видимости страниц с содержанием для взрослых.
- Фильтр платформы : Этот фильтр заменяет ссылки соответствующими платформе, например. мобильные пользователи увидят мобильную версию веб-страницы, если она доступна.
- Фильтр кода состояния : Этот фильтр удаляет устаревшие страницы, т.е.е. ссылки, которые мы больше не можем разрешить.

4. Этап создания фрагмента
После того, как набор результатов будет завершен, мы улучшаем ссылки, чтобы предоставить хорошо отформатированные и чувствительные к запросам фрагменты . Мы также извлекаем любые релевантные структурированные данные, которые может содержать страница, чтобы обогатить ее фрагмент.
Окончательный набор результатов возвращается пользователю через наш шлюз API к различным внешним клиентам.
Поддержка нескольких изменяемых индексов
В разделе отзыва для ясности представлена очень простая версия индекса.Но на самом деле у нас есть несколько версий индекса, работающих в разных конфигурациях с использованием разных технологий. Мы используем Keyvi [10] , Granne, RocksDB и Cassandra в производстве для хранения различных частей нашего индекса с учетом их изменчивости, задержки и ограничений сжатия.
Общий размер нашего индекса в настоящее время составляет около 50 ТБ . Если вы смогли найти сервер с требуемым дисковым пространством и достаточным количеством оперативной памяти, то можно запустить наш поиск на localhost , полностью отключенном от Интернета.Не может быть больше 90 385 независимых 90 386, чем это.
Качество поиска
Измерение качества поиска играет неотъемлемую часть того, как мы тестируем и строим наш поиск. Помимо автоматической проверки результатов на соответствие нашим конкурентам, у нас также есть специальная команда, которая вручную оценивает наши результаты. За годы работы мы собрали рейтинги миллионов результатов. Эти рейтинги используются не только для тестирования системы, но и для обучения алгоритмов ранжирования, о которых мы упоминали ранее.
Fetcher
Журналы запросов, которые мы собираем из Human Web, к сожалению, недостаточны для построения качественного поиска. Фактическое содержание страницы необходимо не только для лучшего ранжирования, но и для обеспечения более богатого пользовательского опыта. Обогащение результата заголовков , сниппетов , геолокаций и изображений помогает пользователю принять взвешенное решение о посещении страницы.
Обогащение результата заголовков , сниппетов , геолокаций и изображений помогает пользователю принять взвешенное решение о посещении страницы.
Может показаться, что для этой цели достаточно Common Crawl, но он имеет плохое покрытие за пределами США, а частота его обновлений нереалистична для использования в поисковой системе.
Хотя мы не сканируем Интернет в традиционном смысле, мы поддерживаем распределенную инфраструктуру выборки, распределенную по нескольким странам. Помимо выборки страниц в нашем индексе через определенные промежутки времени, он предназначен для соблюдения ограничений вежливости и robots.txt , а также для работы с черными списками и недружественными для сканеров веб-сайтами.
У нас все еще есть проблемы с включением нашего сборщика cliqzbot в белый список некоторых очень популярных доменов, таких как Facebook, Instagram, LinkedIn, GitHub и Bloomberg. Если вы можете чем-то помочь , свяжитесь с нами по адресу beta[at]cliqz[dot]com. Вы значительно улучшите наш поиск!
Вы значительно улучшите наш поиск!
Технический стек
- Мы поддерживаем гибридное развертывание сервисов, реализованных в основном на Python, Rust, C++ и Golang.
- Keyvi — наш основной индексный магазин. Мы создали его таким образом, чтобы он был компактным и быстрым, а также предоставлял различные возможности приблизительного сопоставления со структурой данных FST.
- Изменяемая часть наших индексов поддерживается на Cassandra и RocksDB.
- Мы создали Granne для удовлетворения наших потребностей в векторном сопоставлении. Это намного эффективнее памяти, чем другие решения, которые мы могли бы найти — вы можете прочитать больше об этом в завтрашней записи в блоге.
- Мы используем qpick [11] для соответствия нашим ключевым словам. Он создан для эффективного использования памяти и пространства, а также может масштабироваться до миллиардов запросов.
Granne и qpick имеют открытый исходный код под лицензиями MIT и GPL-2. 0 соответственно, проверьте их!
0 соответственно, проверьте их!
Трудно обобщить инфраструктурные проблемы при запуске поисковой системы в небольшом разделе этого поста.Вскоре у нас будут специальные записи в блогах с подробным описанием нашей инфраструктуры Kubernetes, которая обеспечивает все вышеперечисленное, так что ознакомьтесь с ними!
Хотя некоторые из наших ранних решений позволили нам значительно сократить усилия, необходимые для настройки поисковой системы веб-масштаба, теперь должно быть ясно, что есть еще много движущихся частей, которые должны работать в унисон, чтобы обеспечить окончательный результат. . Дьявол кроется в деталях каждого из этих шагов — такие темы, как определение языка , фильтрация контента для взрослых , обработка перенаправлений или встраивание многоязычных слов , являются сложными в веб-масштабе.Скоро у нас будут сообщения о большем количестве внутренних компонентов, но мы хотели бы услышать ваши мысли о нашем подходе. Не стесняйтесь делиться и обсуждать этот пост, мы постараемся ответить на ваши вопросы!
Не стесняйтесь делиться и обсуждать этот пост, мы постараемся ответить на ваши вопросы!
ссылки
ссылки
алфавит Q3 2019 выпуск доходов — отчет ↩︎
statista поисковая система рынка на рынке 2019 — ссылка ↩︎
веб-рейки — Wikipedia — ссылка ↩︎
Spamdexing — Wikipedia — ссылка ↩︎
Deep Web — Wikipedia — ссылка ↩︎
веб-поисковых запросов загрузки веб-сайта — ссылка ↩︎
Granne — GitHub — Link ↩︎
Градиентное усиление Wikipedia — ссылка ↩︎
keyvi — github — ссылка ↩︎
qpick — github — ссылка ↩︎
Поделиться этой статьей
Использование JavaScript для создания внутренней поисковой системы
Мы тратим все свое время на исследования и разработку технологий поиска будущего, потому что мы верим, что сегодня, когда весь контент распространяется по Интернету, мощная поисковая система никогда не была так важна.
Высококачественная внутренняя поисковая система создает и получает доступ к индексу информации, либо широко распространенной, либо сосредоточенной на определенной теме. Затем он использует многоуровневые алгоритмы для анализа введенных пользователем поисковых запросов, а также истории поиска пользователя и аналогичных поисковых запросов, введенных другими пользователями.
После просмотра всех этих данных внутренняя поисковая система упорядочивает и ранжирует контент из своего индекса и представляет рейтинговые данные пользователю на странице результатов, повышая удобство работы пользователей.
Существует несколько способов создания собственной внутренней поисковой системы различной степени сложности. Сегодня мы поговорим о JavaScript и о том, как с его помощью добавить внутреннюю поисковую систему на свой сайт.
Что такое сценарий внутреннего поиска? Сценарий внутреннего поиска — это просто набор кода JavaScript, который мы будем использовать для создания, проектирования и реализации внутренней поисковой системы.
Один из секретов, которым разработчики делятся по всему миру, заключается в том, что независимо от того, над каким проектом вы работаете или что вы хотите, чтобы ваш код делал, кто-то, вероятно, уже сделал это.
Языки кодирования, такие как JavaScript, чрезвычайно экспансивны. Хотя важно понимать код, который вы пишете, большая часть процесса заключается в поиске похожих сегментов, которые уже написал кто-то другой.
Нам нужен код для нашей внутренней поисковой системы в зависимости от того, как мы хотим настроить и оптимизировать нашу систему.
Как создать внутреннюю поисковую систему?Как мы уже упоминали, существует множество способов создать поисковую систему на вашем сайте.Пользователи в Интернете разработали несколько кодов JavaScript, которые либо подключаются к индексу Github, либо получают доступ к Google в качестве стороннего индекса, либо сканируют ваш конкретный сайт в поисках контента.
Существуют также сторонние опции вне фреймворков JavaScript, такие как Google Programmable Search и Yext Answers. Несмотря на то, что оба эти варианта удобны и эффективны, сегодня мы сосредоточимся на том, как вы можете создать собственную поисковую систему с помощью кода, а не внедрить систему от другой компании.
Несмотря на то, что оба эти варианта удобны и эффективны, сегодня мы сосредоточимся на том, как вы можете создать собственную поисковую систему с помощью кода, а не внедрить систему от другой компании.
Но то, как именно вы будете создавать внутреннюю поисковую систему, зависит от вас, вашего веб-сайта и ваших пользователей?
И что вы хотите, чтобы ваши пользователи получили от опыта?
Что вы хотите узнать от своей аудитории с помощью внутренней панели поиска?
Все эти вопросы следует задать себе при составлении плана создания и внедрения поисковой системы на вашей странице.
Зачем использовать JavaScript для написания функции поиска?Существует много разных языков для написания кода, но JavaScript популярен по нескольким причинам.
Будь то более короткая кривая обучения по сравнению с другими сценариями, такими как HTML и CSS, его широкодоступные ресурсы или удобный интерфейс, который он использует, разработчики всех уровней квалификации стекаются в JavaScript.
Вот несколько причин, по которым мы рекомендуем использовать JavaScript.
JavaScript широко используетсяСогласно недавнему исследованию, JavaScript является наиболее широко используемым языком программирования.Это означает, что существует много существующего кода, на который вы можете ссылаться, и множество материалов для изучения.
Легче забратьИнтерфейс и языковая основа JavaScript обычно считаются гораздо более доступными для новых пользователей, чем другие языки.
Не говоря уже о том, что он имеет простой для понимания пользовательский интерфейс для работы, и вам не нужно устанавливать какие-либо другие программы для его написания.
Поддерживается большинством браузеров JavaScript — это основной язык, используемый веб-браузерами, такими как Chrome, Firefox и Safari.Это означает, что ваш внутренний скрипт поисковой системы будет работать так, как вы предполагали, и не должен выдавать никаких сообщений об ошибках или необходимости выполнять процесс перевода независимо от того, что использует ваша аудитория.
Как мы уже упоминали, существует несколько способов использования JavaScript для создания и реализации внутренней поисковой системы на вашем веб-сайте, и мы собрали несколько вариантов для изучения.
Мы рекомендуем попробовать несколько, чтобы понять, что они делают по-другому.Это поможет вам определить, какой процесс лучше всего подходит для вашего сайта.
Факторы, определяющие лучший сценарий для вас:
- Много контента на вашем сайте или нет
- Какой тип управления дизайном вы хотите
- Какой уровень пользовательского анализа вы хотите
JavaScripts содержат множество кодов JavaScript и учебных пособий, что делает его отличным образовательным и творческим ресурсом.
В настоящее время у них есть девять различных вариантов поисковой системы, что еще раз доказывает, что существует бесчисленное множество способов внедрить поисковую систему на вашу страницу.
Но важно отметить различия между ними. У них есть поисковые системы, которые просматривают Интернет через основные системы, но не конкретно через ваш контент, который может быть не тем, что вы ищете.
Однако в этом примере по-прежнему используются общие поисковые системы, такие как Google, Yahoo и MSN, но они фокусируются конкретно на вашем веб-сайте, что может быть более полезным для вас.
ГуглУ Google есть собственный инструмент для разработчиков, который они называют Программируемой поисковой системой.Это позволяет пользователям реализовать внутреннюю поисковую систему, которая фокусируется на их контенте, как и наборы JavaScript.
Однако основное отличие состоит в том, что с помощью этого инструмента вы по-прежнему используете Google, и вместо того, чтобы создавать свою внутреннюю поисковую систему, вы встраиваете их и направляете их внимание.
Вы все еще используете JavaScript для всего этого. Просто в этом процессе вы просто устанавливаете поисковую систему, а не создаете ее.
Подходит ли вам этот метод, зависит от того, чего вы хотите от опыта.
Полезные функцииМета-теги: Мета-теги — это теги данных, которые поисковые системы, внутренние или общие, используют для чтения и анализа вашего онлайн-контента. Важно убедиться, что все ваши страницы имеют правильно написанные мета-описания, мета-заголовки и ключевые слова, чтобы поисковые системы точно собирали ваши данные.
AutoComplete: эта функция помогает пользователям формировать свой поиск так, чтобы он больше соответствовал вашему контенту, повышая точность результатов поиска.
Устойчивость к опечаткам: у пользователей неизбежно будет одна или две опечатки, поэтому крайне важно иметь устойчивую к опечаткам поисковую систему. Если ваш пользователь должен повторно ввести свою строку просто потому, что ваш движок не может понять, что они просили из-за небольшой орфографической ошибки, они будут разочарованы и, возможно, покинут вашу страницу.
Удобство для мобильных устройств: Смартфоны быстро становятся самым популярным устройством для просмотра и покупок в Интернете.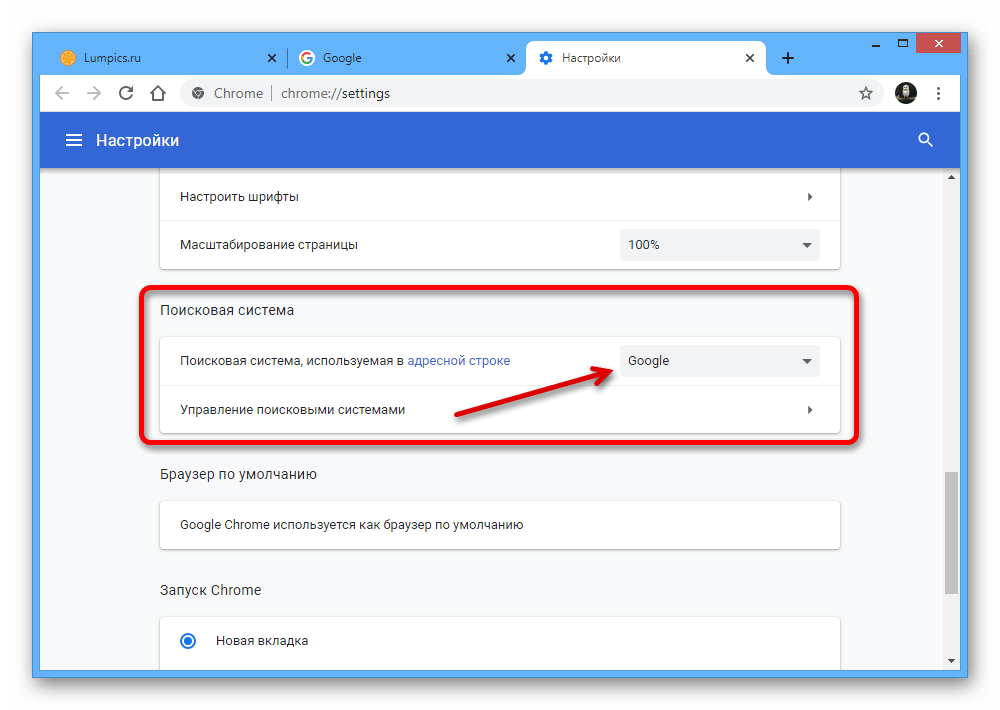 Поскольку 63% онлайн-покупателей совершают покупки с мобильных устройств, а более половины всех онлайн-продаж приходится на мобильные устройства, крайне важно, чтобы вся ваша страница и особенно ваша поисковая система выглядели чистыми и хорошо работали на мобильных устройствах.
Поскольку 63% онлайн-покупателей совершают покупки с мобильных устройств, а более половины всех онлайн-продаж приходится на мобильные устройства, крайне важно, чтобы вся ваша страница и особенно ваша поисковая система выглядели чистыми и хорошо работали на мобильных устройствах.
Создание собственной внутренней поисковой системы с помощью JavaScript может быть увлекательным проектом и способом лучше понять изнанку вашего веб-сайта. В зависимости от того, что вы хотите от поисковой системы, она может идеально соответствовать вашим потребностям. JS работает во многих системах управления контентом (CMS), таких как WordPress, и существует обходной путь для распространенных проблем, таких как динамическая отрисовка.
JavaScript — это мощный и относительно простой в освоении инструмент, который дает вам контроль над вашим веб-сайтом.С большим количеством существующего кода, такого как наборы скриптов, и массой образовательных ресурсов, JavaScript является отличным языком для создания внутренней поисковой системы, независимо от ваших текущих знаний кода.
Однако вы можете потратить много времени и усилий на создание функции поиска, отвечающей всем требованиям и предоставляющей передовой опыт и преимущества, которые вам нужны для удобства пользователей и бизнеса.
Сторонние поставщики могут помочь вам во всем, от лучшего понимания объектной модели документа (DOM) до оптимизации для сканеров поисковых систем.Даже для внутреннего поиска по сайту вам нужно знать, как боты поисковых систем обрабатывают JavaScript, техническое SEO и
.JavaScript SEO, рендеринг на стороне сервера (SSR) и рендеринг на стороне клиента, а также множество других задач, необходимых для вашего контента JavaScript для эффективного создания внутренней поисковой системы сайта с использованием ваших веб-страниц. Иногда просто не стоит создавать собственный поисковый индекс с нуля, когда вы можете сделать это одним нажатием кнопки с помощью сторонних веб-приложений.
Один из недостатков создания поисковой системы с помощью JavaScript заключается в том, что вы не получаете понимания, расширенного программного обеспечения поисковой системы или преимуществ, которые были бы у стороннего поставщика.
Узнайте больше на Yext.com
Каталожные номера:
- Языки программирования, сценариев и разметки
- Наборы JavaScript
- Программируемая поисковая система от Google
Как создать собственную систему пользовательского поиска — SourceCon
Вы когда-нибудь пользовались системой пользовательского поиска Google? Недавно я задал этот вопрос 100 рекрутерам, и ни один человек не поднял руку.
Реальность такова, что мы все использовали систему пользовательского поиска Google. В большинстве случаев при поиске на веб-сайте вы используете СПП Google, настроенную для поиска только на этом сайте или его части и возвращающую только нужную вам информацию. Хорошим примером СПП Google на крупном веб-сайте является окно поиска в верхней части сайта CNN.com
. Система пользовательского поиска Google, которая очень удобна для найма, — это Brupt.com, поисковая система, которая позволяет выполнять поиск в Интернете по определенным типам файлов (очень удобно для поиска списков участников в Excel или резюме в Word или PDF).
Создайте свой собственный
Как рекрутеры и поставщики, вы можете создать свою собственную систему пользовательского поиска Google, сосредоточив ее только на веб-сайтах, которые вы хотите найти. Вы также можете добавить «уточнения», которые представляют собой небольшие фрагменты логического кода, которые позволят вам сузить результаты на основе определенных критериев, таких как география, специальность или тип файла.
Пользовательский поиск Google, который я создал в прошлом, просматривал Linkedin, фильтруя результаты на основе основных географических регионов, на которых сосредоточились наши рекрутеры.Дополнительные уточнения коснулись кандидатов, утверждавших, что у них есть допуск. Другая CSE, которую мы создали, искала веб-сайты всех наших конкурентов и выявляла пресс-релизы и био-страницы на их веб-сайтах. Возможности безграничны!
Статья продолжается ниже
С чего начать
Перейдите сюда и нажмите «Создать систему пользовательского поиска».:max_bytes(150000):strip_icc()/how-to-change-your-default-search-engine-on-chrome-46862846-3a52d7ff29774f76b30c641a5a550006.jpg) Следуйте инструкциям, чтобы завершить поисковую систему. Это потребует промежуточных логических знаний и потребует некоторых экспериментов, чтобы сделать это правильно.
Следуйте инструкциям, чтобы завершить поисковую систему. Это потребует промежуточных логических знаний и потребует некоторых экспериментов, чтобы сделать это правильно.
Расскажите нам о любых интересных системах пользовательского поиска Google, которые вы создали, в разделе комментариев. Если какие-то из них общедоступны, пожалуйста, поделитесь ссылкой!
Как добавить пользовательские поисковые системы в Chrome
Адресная строка Chrome служит для быстрого поиска в Google, но вы не ограничены поиском в Google. На этой же панели вы можете искать любой сайт или приложение.
5 вещей, которые вы должны автоматизировать сегодня
Это удобно, если вы часто ищете в определенных приложениях, например, в Gmail, Google Диске или Twitter.Вы можете выполнять поиск на любом сайте, не открывая его, точно так же, как вам не нужно заходить на google.com для поиска в Google. Введите ключевое слово, нажмите Tab, и все готово.
Введите ключевое слово, нажмите Tab, и все готово.
Добавление этих систем пользовательского поиска не займет много времени, а время, которое они могут сэкономить, возрастет. Вот как начать.
Знаете ли вы, что Google может выполнять функции калькулятора и переводчика? Ознакомьтесь с нашим
Найдите любое приложение в строке поиска Chrome
Чтобы начать, откройте настройки Chrome, нажав на три точки в правом верхнем углу.
Нажмите Поисковая система , затем Управление поисковыми системами или перейдите непосредственно на chrome://settings/searchEngines .
Отсюда вы можете добавлять новые поисковые системы.
Это выглядит немного сложно…
…но не волнуйтесь: на самом деле это довольно просто.
Для Поисковик добавить название сайта; например,
Twitter.Для ключевого слова вы можете использовать все, что захотите.
По умолчанию Google обычно использует URL-адрес; например, twitter.com.
 По умолчанию Google обычно использует URL-адрес; например,
По умолчанию Google обычно использует URL-адрес; например, URL-адрес немного сложнее, но не так уж и плох. Перейдите на сайт, для которого вы создаете поисковую систему, затем найдите что-нибудь. Мне нравится использовать что-то, что легко обнаружить, например asdf .
Скопируйте URL-адрес из панели поиска, затем вернитесь на вкладку настроек Chrome и вставьте URL-адрес. Наконец, замените поисковый запрос asdf на %s . Вот так:
Нажмите Добавьте , и все готово.Вы добавили систему пользовательского поиска в Chrome. Теперь введите ключевое слово в адресной строке, чтобы увидеть текст . Нажмите Tab для поиска twitter.com .
Нажмите клавишу Tab , и вы сможете запустить поиск прямо в адресной строке. Вы также можете просто ввести ключевое слово и нажать пробел — это работает так же.
Теперь вы можете искать в Twitter, не открывая twitter dot com.