Выписка егрюл без подписи без эцп
Всякому юридическому лицу раньше или позже понадобится выписка из ЕГРЮЛ. Значительно упрощает процедуру онлайн заказ документа. Как получить выписку из ЕГРЮЛ через Интернет?
Информация из Единого реестра юридических лиц востребована при различных операциях.
Умея пользоваться сервисами на официальном сайте ФНС, можно легко и быстро получить желаемые данные. Как можно заказать выписку из ЕГРЮЛ онлайн?
Содержание
- 1
Базовые аспекты ↑
- 1.1 Что это такое
- 1.2 Зачем нужна выписка
- 1.3 Законодательная база
- 2
Порядок получения электронной выписки из ЕГРЮЛ ↑
- 2.1 Возникновение необходимости в документе
- 2.2 Необходимые данные
- 2.3
Как это с усиленной электронной подписью
- 2.3.1 Источник
Базовые аспекты ↑
Что являет собой такое понятие как ЕГРЮЛ? Это Единый Государственный Реестр Юридических Лиц.
Главным предназначением реестра является систематизирование сведений обо всех юридических лицах, реализовывающих свою деятельность на территории РФ.
На стадии регистрации нового юридического лица данные о нем незамедлительно заносятся в общий реестр. В случае каких-то изменений в деятельности в запись ЕГРЮЛ вносятся коррективы.
Таким образом, можно всегда проверить, зарегистрирован ли субъект в качестве юрлица и насколько правомерна его деятельность.
До недавнего времени выписки из ЕГРЮЛ предоставлялись лишь на бумажных носителях. Нужно было обратиться в ФНС лично и подать заявку.
Получить готовый документ можно было только через несколько дней. Сейчас получить такую выписку стало значительно проще.
Воспользовавшись специальным сервисом на сайте ФНС, можно приобрести нужные данные из ЕГРЮЛ уже спустя несколько минут.
Сервис дает возможность любому заинтересованному лицу получить сведения из ЕГРЮЛ о конкретном юридическом лице.
При надобности можно получить выписку из ЕГРЮЛ с электронной подписью. Подобный документ обладает такой же юридической силой, что и бумажная версия, заверенная печатью.
Что это такое
Выпиской из ЕГРЮЛ именуется официальный документ, который выдает Федеральная налоговая служба.
В нем содержатся все важные данные информационного и юридического характера о зарегистрированном юридическом лице.
Различается несколько разновидностей выписок:
- электронная, или информационная;
- официальная;
- расширенная;
- обычная.
Получить обычную электронную выписку может любой человек, имеющий доступ в Интернет. Документ предоставляется в виде электронной ссылки.
Выписку можно скачать и распечатать. Но использовать подобную выписку в качестве юридического документа не получится, поскольку она не заверена подписью ФНС. Плюсом является оперативность и легкость получения.
Официальная и расширенная выписки могут получаться только самим предпринимателем, государственными и внебюджетными, судебными и правоохранительными органами.
В этом случае документ выдается на бумажном носителе с наличием штампов, подписей и уникального регистрационного номера.
Для получения расширенной выписки из ЕГРЮЛ необходимо наличие в заявке таких данных как:
- данные паспорта заявителя;
- наименование инспекции, куда подается запрос;
- ИНН налогоплательщика;
- ОГРН компании, о которой требуется получить сведения.
Выписка расширенного типа содержит всю информацию о юридическом лице и источниках его доходов. Обычная выписка доступна к получению любым гражданином.
В таком документе отсутствует персональная информация предпринимателя. Указываются лишь общие сведения и характер деятельности. Изначально электронная выписка носила чисто информационный характер.
Но после того как появилась возможность заверения документа электронной подписью, многое изменилось. Теперь юридическое лицо может заказать официальную и расширенную выписку онлайн.
Скачанная по полученной в ответ на запрос ссылке выписка это юридический документ. Роль официальной печати принадлежит ЭЦП, электронной цифровой подписи.
Зачем нужна выписка
Выписка из ЕГРЮЛ может понадобиться в самых разнообразных обстоятельствах, например:
- для подтверждения факта существования юрлица;
- в случае судебных тяжб;
- для создания расчетного счета в банковском учреждении;
- при участии в тендерах или аукционах;
- для проверки контрагента;
- в процессе ликвидации или реорганизации компании;
- для лицензирования определенных видов деятельности;
- при нотариальном заверении документов, касающихся деятельности предприятия.
Данные случаи наиболее частые причины необходимости выписки. В частном порядке документ может быть востребован и в иных обстоятельствах.
Законодательная база
ЕГРЮЛ был образован в 2002 году. С этого момента кардинально изменилась вся система регистрации для юридических лиц в РФ.
1 июля 2002 года начал действовать Федеральный закон «О государственной регистрации юридических лиц».
Данный правовой акт регламентирует правовые отношения, возникающие в процессе регистрации и последующей деятельности юридических лиц, а также порядок ведения ЕГРЮЛ.
Порядок государственной регистрации юридических лиц и внесения сведений о них в Единый реестр осуществляется в соответствии с ФЗ № 129 от 8.08.2001 «О государственной регистрации юридических лиц и предпринимателей».
Порядок получения выписки из ЕГРЮЛ и сроки устанавливаются согласно «Правилам ведения ЕГРЮЛ и предоставления содержащихся в нем сведений».
Данные Правила ратифицированы Постановлением Правительства РФ № 438 от 19.06.2002.
Сервис, позволяющий получить выписку из ЕГРЮЛ в электронном формате, разработан в соответствии с ФЗ № 129 (ст.7, п.1).
Использование сервиса позволяет бесплатно получить необходимые сведения из ЕГРЮЛ об определенном юрлице. Официальная электронная выписка предоставляется в PDF формате и содержит усиленную квалифицированную электронную подпись, которая визуализируется при распечатке документа.
Согласно п.1, п.3 ст.6 ФЗ № 63 от 6.04.2011 «Об электронной подписи» электронная выписка с усиленной электронной подписью равнозначна документу, полученному в бумажном формате.
Процесс получения выписки немного претерпел изменения в 2019 году. Обусловило это вступление в силу Административного регламента 30 июня 2019 года.
Теперь при формировании запроса на получение данных из ЕГРЮЛ заявитель должен указать максимально полную информацию о себе. В некоторых случаях от заявителя потребуется предоставление паспортных данных.
Порядок получения электронной выписки из ЕГРЮЛ ↑
Возможность получения выписки из ЕГРЮЛ посредством Интернета предусмотрена Приказом ФНС РФ № ММВ-7-6/460@ от 22.09.2010 (в ред. от 8.12.2014).
Называется «О вводе в промышленную эксплуатацию программного обеспечения, реализующего предоставление сведений из ЕГРЮЛ в виде электронной или бумажной выписки на основании запроса, поступившего в электронном виде о юридическом лице».
В настоящее время возможны три варианта получения электронной выписки:
- через сервис налоговой службы, без регистрации;
- посредством личного кабинета налогоплательщика;
- при обращении к порталу Госуслуг.
Во всех случаях для получения официальной выписки требуется КЭП (квалифицированная электронная подпись) физического лица, которое представляет юридическое лицо без доверенности либо КЭП юридического лица.
Обычные информационные выписки без наличия электронной подписи не требуют от заявителя наличия личной электронной подписи.
Но в этом случае предоставлена будет лишь общая информация, без указания персональных данных юрлица. Целесообразнее всего заказать выписку на официальном сайте налоговой службы.
Инструкция по получению документа выглядит так:
Если поиск не дал результатов, возможно неправильно был введен код с картинки либо введена неправильная информация.
Возникновение необходимости в документе
Для чего может понадобиться предоставление выписки из ЕГРЮЛ в электронном виде? Прежде всего, в качестве доказательства собственной добросовестности и добропорядочности.
Электронный документ весьма удобно отправлять при электронной деловой переписке.
Кроме того можно использовать официальную электронную выписку практически во всех случаях, когда требуется предоставление данных из ЕГРЮЛ:
- при нотариальных сделках;
- в процессе оформления операций с недвижимостью;
- при оформлении различных разрешительных документов;
- для участия в тендерах, аукционах, конкурсах.
Потребность в выписке возникает и в случае, когда нужно проверить контрагента на благонадежность. В этом случае нет необходимости получать выписку с усиленной электронной подписью.
Информационного документа вполне достаточно, чтобы получить основные данные о потенциальном партнере.
Необходимые данные
Для получения выписки из Единого реестра требуется подача заявления. При онлайн заявке заявление заменяет специальная форма, в которую вносятся необходимые данные.
Для получения обычной выписки нужно указать:
- полное наименование организации;
- ИНН, КПП, ОГРН;
- точный юридический адрес.
При получении официальной выписки дополнительно нужно указать собственные данные заявителя.
В отличие от получения бумажной выписки не требуется указание «срочности» или нужного количества экземпляров.
Электронный документ в любом случае будет предоставлен оперативно, спустя минут пятнадцать. Скачать документ по полученной ссылке можно неограниченное число раз в течение нескольких дней.
Как это с усиленной электронной подписью
Электронная выписка обладает юридической силой только, если на ней имеется квалифицированная усиленная электронная подпись ФНС.
Данная подпись полностью заменяет собой печать налоговой службы. То есть документ с электронной подписью равнозначен бумажному варианту с печатью.
То есть документ с электронной подписью равнозначен бумажному варианту с печатью.
Обычная электронная выписка обладает лишь информационным характером. Она не заверена подписью.
Для получения выписки с усиленной электронной подписью необходимо:
- зарегистрироваться на сайте УФНС;
- зайти в личный кабинет;
- перейти в нужный раздел;
- ввести ОГРН юридического лица;
- через несколько минут скачать готовый документ.
Предоставленная ссылка действительна в течение пяти дней, можно скачивать документ нужное количество раз.
Следует отметить, что пароль к личному кабинету на сайте ФНС потребуется получить непосредственно в налоговой инспекции.
Получить выписку из ЕГРЮЛ онлайн вовсе не так сложно, как может показаться. Любой человек, хоть немного знакомый с компьютерными технологиями, может сделать это самостоятельно.
При этом отпадает необходимость долгого ожидания получения бумажной выписки из налогового органа. Электронную выписку можно получить буквально через несколько минут после подачи запроса.
Электронную выписку можно получить буквально через несколько минут после подачи запроса.
Источник
- http://buhonline24.ru/vypiska/egrjul/vypiska-iz-egrjul-onlajn.html
Как запросить бумажную выписку из ЕГРЮЛ/ЕГРИП через интернет
Многие пользователи системы «СбиС++ Электронная отчетность» знакомы с предоставляемым в программе сервисом получения выписки из ЕГРЮЛ/ЕГРИП. Быстро и оперативно можно запросить электронную выписку из данных реестра по любому ЮЛ/ИП, тем самым проверив своего контрагента или данные по своему предприятию. Однако очень часто требуется получить такую выписку из ЕГРЮЛ по своей компании в бумажном виде. Например ее требует один из ваших контрагентов, как правило крупное или государственное предприятие. Далее вы узнаете как можно ее получить с наименьшими затратами времени — без лишних поездок и стоянии в очередях. Такой сервис (правда пока только по собственному ЮЛ или ИП) можно получить на сайте Федеральной Налоговой Службы www.nalog.ru. Найдите в соответствующем разделе ссылку на «Получение выписки из ЕГРЮЛ/ЕГРИП через интернет» (рис.1) Рис.1 Выписка может быть предоставлена следующими способами: в «электронном виде» — по сети Интернет; на бумажном носителе – «лично заявителю» при его обращении в налоговый орган либо «почтовым отправлением». Поскольку нас интересует второй вариант, то остановимся на нем подробнее. Выписка на бумажном носителе(сшитая, пронумерованная и подписанная уполномоченным должностным лицом) предоставляется налоговым органом, в котором находится регистрационное дело юридического лица или индивидуального предпринимателя, сведения о котором запрошены. При этом вы используете электронную цифровую подпись выданную вам доверенным удостоверяющим центром (из списка ФНС) для работы с системой сдачи бухгалтерской отчетности. Вы можете предварительно проверить, можете ли вы со своего компьютера сформировать заявку, для этого надо перейти в соответствующий пункт (рис. Рис.2 Если проверка завершилась положительно, то можете переходить к пункту «Перейти в режим «Получение выписки». Заполняете карточку запроса соответствующими данными (ОГРН, способ получения) и следуете дальнейшим указаниям. Выписку по запросу руководитель или уполномоченное лицо получает при обращении в соответствующий налоговый орган в срок, сообщенный при регистрации заявки. При обращении в ИФНС следует сообщить номер заявки, направленной через Интернет. Информацию о ходе выполнения заявки можно получать в режиме «Просмотр состояния обработки ранее поданных заявок». Если в указанный срок выписка не была забрана или при формировании запроса был выбран способ получения «почтой», то выписка направляется почтовым отправлением на адрес юридического лица либо на адрес индивидуального предпринимателя, сведения о которых содержатся соответственно в ЕГРЮЛ или ЕГРИП. Если у проверка готовности вашего компьютера выявила проблемы, то необходимо провести соответствующую настройку. 1. Работа сервиса возможна только через Интернет обозреватель — Microsoft Internet Explorer. Если он не установлен у вас на компьютере, то нужно установить его. Скачать дистрибутив Internet Explorer можно с сайта компании Microsoft. 2. Требование «Возможно защищенное соединение с сервером с использованием алгоритмов ГОСТ 28147-89 и ГОСТ Р 34.10-2001» по сути дела означает, что у вас должна быть установлена система CryptoPro (КриптоПро) и корневой сертификат УЦ ГНИВЦ ФНС РФ. Сертификат доступен на сайте ГНИВЦ ФНС РФ. Как правило, у пользователей СбиС++ с этим пунктом проблем не возникает. 3. Если не установлен сертификат ключа подписи, выданный удостоверяющим центром, аккредитованным в сети доверенных УЦ ФНС России. Вам необходимо через КриптоПро установить свой ключ. Открытую часть своего ключа (ЭЦП) вы можете экспортировать, зайдя в СбиС++ в карточку налогоплательщика (рис.3) Рис.3 Открываем Пуск — Насторойки — Панель управления.
Рис.4 На закладке Сервис используем Установить личный сертификат и следуем Мастеру установки личного сертификата (рис.5 и 6) Рис.5 Рис.6 Если вы все сделали правильно, то сертификат будет виден в Internet Explorer (рис. 7) Рис.7 Проведя эти подготовительные мероприятия вы уже сможете продолжить формирование запроса выписки через сайт ФНС. Удачной работы! |

 2) и нажать кнопку «Начать проверку».
2) и нажать кнопку «Начать проверку». Ниже приведены возможные стандартные процедуры подготовки компьютера.
Ниже приведены возможные стандартные процедуры подготовки компьютера.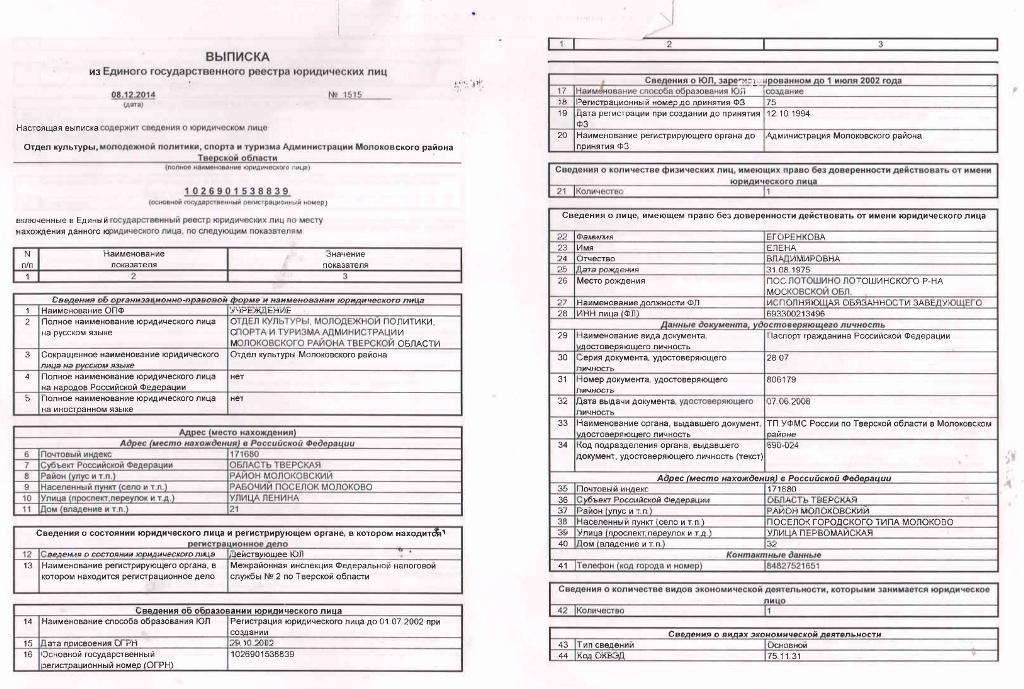 Запускаем программу КриптоПро CSP (рис.4)
Запускаем программу КриптоПро CSP (рис.4)Изучение веб-скрейпинга: как извлечь данные из Интернета | by Dan Suciu
Веб-скрапинг — это метод извлечения огромных объемов данных с веб-сайтов и их сохранения в локальном файле на вашем устройстве или в базе данных в форме электронной таблицы.
Доступ к данным многих веб-сайтов возможен только через веб-браузер. Они не позволяют вам хранить копию этой информации для личного использования. Единственный другой вариант — вручную скопировать и вставить результаты, что является трудоемкой задачей, на выполнение которой могут уйти часы или даже дни.
Единственный другой вариант — вручную скопировать и вставить результаты, что является трудоемкой задачей, на выполнение которой могут уйти часы или даже дни.
Очистка веб-страниц — это метод автоматизации этой операции, при котором вместо ручной загрузки данных с веб-сайтов программа очистки веб-страниц может сделать это за долю времени.
В зависимости от ваших требований программное обеспечение для просмотра веб-страниц может автоматически загружать и извлекать данные с различных страниц веб-сайта. Вы можете удобно скопировать имеющиеся на сайте данные в файл на своем компьютере одним щелчком мыши.
· Так в чем смысл?
· Как веб-скраперы собирают данные из Интернета?
∘ Выполнение HTTP-запроса к серверу
∘ Извлечение и анализ кода
∘ Локальное сохранение
· Как веб-парсеры
∘ Выберите контент
∘ Проверьте веб-страницу
∘ Выясните, что вы хотите извлечь
∘ Напишите код и запустите его
∘ Сохраните данные
· Автоматизация может сделать вам комплимент
Интернет является крупнейшим в мире архивом информации и данных в истории человечества. Люди могут извлечь наибольшую выгоду из этих данных, но для нас просто слишком много информации, которую мы не можем собрать и обработать, не умирая от старости. В результате парсинг сайта становится все более важным. Нам нужны компьютеры для чтения данных, чтобы мы могли использовать их в нескольких отраслях, где несколько вариантов использования веб-скрапинга:
Люди могут извлечь наибольшую выгоду из этих данных, но для нас просто слишком много информации, которую мы не можем собрать и обработать, не умирая от старости. В результате парсинг сайта становится все более важным. Нам нужны компьютеры для чтения данных, чтобы мы могли использовать их в нескольких отраслях, где несколько вариантов использования веб-скрапинга:
- мониторинг цен
- анализ конкурентов
- анализ социальных сетей
- отслеживание новостей
- принятие решений в сфере недвижимости
Пренебрежение ценностью веб-скрапинга означает отрицание силы, которой обладает Интернет.
Итак, теперь мы знаем, что такое парсинг сайтов и почему его используют различные организации. Но как все это работает? Хотя точный процесс зависит от используемой программы или методов, все веб-роботы проходят следующие действия:
Отправка HTTP-запроса на сервер
Когда вы используете свой компьютер для доступа к веб-сайту, вы отправляете так называемый HTTP-запрос на хост веб-сайта. Если запрос будет принят, они отправят HTTP-ответ с содержимым конкретной страницы, которую вы хотите посетить. В некотором смысле этот контент уже хранится на вашем компьютере, отключение интернета не приведет к исчезновению страницы (если только вы не перезагрузите ее).
Если запрос будет принят, они отправят HTTP-ответ с содержимым конкретной страницы, которую вы хотите посетить. В некотором смысле этот контент уже хранится на вашем компьютере, отключение интернета не приведет к исчезновению страницы (если только вы не перезагрузите ее).
Парсеры также проходят этот этап. Разница в том, что как только они получат свой ответ, вместо того, чтобы просто просмотреть его, они планируют сделать копию.
Извлечение и анализ кода
Этот шаг может сильно измениться в зависимости от того, что вы хотите, чтобы парсер делал. Как только бот получит доступ к данным HTML, он готов извлечь все. Конечно, возможно, вы этого не хотите. Например, страница может быть очень большой, и вам нужна только небольшая часть ее данных.
В таком случае следует добавить некоторые условия, за что скребком хвататься. Самый простой пример — захват заголовков путем выбора только текста внутри тегов 
Однако небольшой совет: если вы планируете использовать контент на странице более одного раза, проще просто извлечь весь код, сохранить его локально и найти любую конкретную информацию, которая вам нужна. Таким образом, вы делаете меньше запросов, поэтому это более экономично для вас и меньше напрягает сайт.
Локальное сохранение
После того, как мы упорядочим данные, они будут сохранены в локальном файле. Информация часто сохраняется в структурированном формате, таком как csv или xls. Кроме того, такие форматы, как JSON или XML, полезны, если вы планируете использовать другие программы для обработки данных.
На первый взгляд веб-скрапинг может показаться простым, но у него есть свои особенности, особенно когда вам приходится использовать прокси-серверы или рендеринг Javascript. Тем не менее, это лучше, чем сбор данных вручную в течение всего дня, каждый день.
Если вы решите создать свой собственный парсер, процесс извлечения данных будет состоять из нескольких шагов. Обратите внимание, что готовые продукты могут выполнять некоторые из этих шагов без вашего участия, но общая процедура выглядит следующим образом:
Обратите внимание, что готовые продукты могут выполнять некоторые из этих шагов без вашего участия, но общая процедура выглядит следующим образом:
Выберите контент
В качестве первого шага очень важно определить конкретную проблему, которую вы решаете. для решения с помощью парсинга веб-страниц. Например, вы хотите купить винтажный Citroen DS и не хотите прожигать дыру в своем кошельке. Используйте веб-скрапинг, и вы сможете:
- Просматривайте веб-сайты о старинных автомобилях, получая информацию о том, какие детали искать, где покупать и даже есть ли предпочтительное время года для сделки;
- Легко проверить несколько источников, найти лучшие цены и условия автомобиля;
- Установить уведомление в случае снижения цены в интернет-магазинах.
Теперь, когда у вас есть хорошее представление о том, что вы хотите сделать и как вы хотите решить эту проблему, вам нужно найти источник данных, то есть веб-сайт, на котором хранятся ваши данные.
Найдите авторитетный источник со всей необходимой вам конкретной информацией и вперед! На самом деле, найдите несколько, просто чтобы убедиться, что информация, которую вы получаете, является подлинной.
Проверить веб-страницу
Чтобы получить представление о том, как бот видит веб-страницу, вам следует взглянуть на ее HTML-код. Для этого вам просто нужно щелкнуть правой кнопкой мыши где-нибудь на странице и выбрать «Проверить элемент». Поскольку вас может заинтересовать конкретный фрагмент информации, этот шаг имеет решающее значение для понимания того, как данные вложены на странице, какие теги и классы вам нужно искать.
Щелкните правой кнопкой мыши в любом месте страницы и выберите «Проверить элемент» или «Просмотреть исходный код страницы», чтобы проверить его. Чтобы увидеть, где находится конкретный объект на странице, например текст или изображение, щелкните его правой кнопкой мыши и выберите «Проверить элемент».
Выясните, что вы хотите извлечь
Если вы ищете обзоры автомобилей, вам нужно выяснить, где они хранятся во внешнем коде. При наведении курсора на фрагмент кода браузер автоматически выделяет соответствующие данные в обычном пользовательском интерфейсе. Итак, если вы не уверены, что делает фрагмент кода, это выделение может помочь вам понять это.
При наведении курсора на фрагмент кода браузер автоматически выделяет соответствующие данные в обычном пользовательском интерфейсе. Итак, если вы не уверены, что делает фрагмент кода, это выделение может помочь вам понять это.
Найдите в интерфейсе содержимое, которое хотите очистить, затем найдите соответствующий код. Данные, которые мы ищем, вложены в выделенный тег
Каждый сайт имеет свою архитектуру и стиль. В меньшей степени это верно для разных страниц одного и того же веб-сайта. Итак, этот шаг 100% необходим для новых сайтов, но может понадобиться и для разных страниц на одном сайте.
Напишите код и запустите его
После того, как вы найдете правильные теги, вам нужно указать их в коде. Это говорит боту, где искать информацию и что извлекать.
После того, как вы написали код, он говорит сам за себя, вам нужно будет его запустить. Это не должно занимать больше пары секунд.
Сохранение данных
Последний шаг включает в себя загрузку и сохранение данных. Наиболее распространенным форматом для просмотра человеком является CSV. Его также можно отправить дальше по программному конвейеру другим программам для обработки. В этом случае вы можете использовать формат JSON, если пункт назначения не поддерживает формат CSV.
Так или иначе, парсер сделал свое дело и вы вольны хранить данные на своей машине, в облаке или сразу работать над ними, в результате чего получается что-то новое.
Вот и все. Вот как разворачивается веб-скрапинг.
Все, что вам нужно сделать сейчас, это начать изучать программное обеспечение для веб-скрейпинга, если у вас нет времени или интереса работать над собственным парсером.
Для начала, есть несколько инструментов, которые вы можете использовать. Если вы хотите выполнять парсинг массово, можно найти более мощные инструменты парсинга, поэтому приведенный выше список идеально подходит для выбора аккуратного API._ot_19.10.10_(str1).jpg)
Как извлечь данные с веб-сайта? Полное руководство по извлечению данных с любого веб-сайта
Интернет становится невероятным источником данных. Все больше и больше данных доступны в Интернете, из пользовательского контента в социальных сетях и форумах, веб-сайтов электронной коммерции, веб-сайтов недвижимости или СМИ… Многие предприятия построены на этих веб-данных или сильно зависят от них.
Ручное извлечение данных с веб-сайта и копирование/вставка их в электронную таблицу — процесс, подверженный ошибкам и занимающий много времени. Если вам нужно очистить миллионы страниц, это невозможно сделать вручную, поэтому вам следует автоматизировать это.
В этой статье мы увидим , как получить данные с веб-сайта с помощью множества различных решений. Лучший способ получить данные из Интернета зависит от следующего:
- Вы специалист?
- У вас есть штатные разработчики?
- С какого типа веб-сайтов вам нужно извлекать данные?
- Каков ваш бюджет?
См. диаграмму в высоком разрешении здесь
диаграмму в высоком разрешении здесь
От создания собственного конвейера веб-скрейпинга до фреймворков для веб-скрейпинга и инструментов для веб-скрейпинга — непростая задача понять, с чего начать.
Прежде чем углубиться в извлечение данных из Интернета, давайте рассмотрим различные варианты использования парсинга веб-страниц.
Каковы различные варианты использования веб-скрапинга?
Вот несколько интересных примеров использования веб-скрапинга:
- Онлайн-мониторинг цен : Многие розничные продавцы отслеживают рынок онлайн, чтобы динамически изменять свои цены. Они следят за ассортиментом своих конкурентов, изменениями цен, продажами, новыми продуктами…
- Недвижимость : Многим стартапам в сфере недвижимости нужны данные из списков недвижимости. Это также золотая жила для исследования рынка.
- Агрегация новостей : Новостные веб-сайты тщательно удаляются для анализа настроений, поскольку альтернативные данные для финансов / хедж-фондов.
 ..
.. - Социальные сети : Многие компании извлекают данные из социальных сетей для поиска сигналов. Маркетинговые агентства влиятельных лиц получают информацию от влиятельных лиц, наблюдая за ростом их подписчиков и другими показателями.
- Агрегирование обзоров : Многие стартапы занимаются агрегированием обзоров и управлением брендом. Они извлекают отзывы с множества различных веб-сайтов о ресторанах, отелях, врачах и компаниях.
- Лидогенерация : Когда у вас есть список веб-сайтов, которые являются вашими целевыми клиентами, может быть интересно собрать их контактную информацию (адрес электронной почты, номер телефона…) для ваших информационных кампаний.
- Результаты поисковой системы : Мониторинг страницы результатов поисковой системы имеет важное значение для индустрии SEO для мониторинга рейтинга. Другие отрасли, такие как интернет-магазины, также отслеживают поисковую систему электронной коммерции, такую как Google Shopping, или даже рынок, такой как Amazon, отслеживают и улучшают свои рейтинги.
 ..
..
По нашему опыту работы с ScrapingBee, это основные варианты использования, которые мы чаще всего встречали у наших клиентов. Конечно, есть и много других.
В этой части мы рассмотрим различные способы извлечения данных программным путем (используя код). Если вы технологическая компания или у вас есть собственные разработчики, это, как правило, путь.
Для крупных операций веб-скрейпинга написание собственного кода веб-скрейпинга обычно является наиболее экономичным и гибким вариантом. Доступно множество различных технологий и фреймворков, и это то, что мы собираемся рассмотреть в этой части.
Собственный веб-конвейер
В качестве примера предположим, что вы являетесь службой мониторинга цен, извлекающей данные из множества различных веб-сайтов электронной коммерции.
Ваш стек веб-скрейпинга, вероятно, будет включать следующее:
- Прокси
- Безголовые браузеры
- Правила извлечения (селекторы XPath и CSS)
- Планирование работы
- Хранение
- Мониторинг
Прокси-серверы являются центральным элементом любой операции парсинга веб-страниц. Многие веб-сайты отображают разные данные в зависимости от страны IP-адреса. Например, интернет-магазин будет отображать цены в евро для жителей Европейского Союза. На американском веб-сайте будет отображаться цена в долларах для жителей США. В зависимости от того, где расположены ваши серверы и от целевого веб-сайта, с которого вы хотите извлечь данные, вам могут понадобиться прокси в другой стране.
Многие веб-сайты отображают разные данные в зависимости от страны IP-адреса. Например, интернет-магазин будет отображать цены в евро для жителей Европейского Союза. На американском веб-сайте будет отображаться цена в долларах для жителей США. В зависимости от того, где расположены ваши серверы и от целевого веб-сайта, с которого вы хотите извлечь данные, вам могут понадобиться прокси в другой стране.
Кроме того, необходимо иметь большой пул прокси-серверов, чтобы избежать блокировки сторонними веб-сайтами. Существует два типа прокси: IP-адреса центров обработки данных и резидентные прокси. Некоторые веб-сайты полностью блокируют IP-адреса центров обработки данных, в этом случае вам потребуется использовать домашний IP-адрес для доступа к данным. Кроме того, существует гибридный тип прокси, который сочетает в себе лучшее из двух миров: прокси-провайдеры
,, , , безголовые браузеры, , — еще один важный слой в современном веб-скрапинге. Появляется все больше и больше веб-сайтов, созданных с использованием блестящих интерфейсных фреймворков, таких как Vue. js, Angular.js, React.js. Эти платформы Javascript используют внутренний API для извлечения данных и рендеринга на стороне клиента для рисования DOM (объектной модели документа). Если бы вы использовали обычный клиент HTTP, который не отображает код Javascript, страница, которую вы получили бы, была бы почти пустой. Это одна из причин, почему безголовые браузеры так важны.
js, Angular.js, React.js. Эти платформы Javascript используют внутренний API для извлечения данных и рендеринга на стороне клиента для рисования DOM (объектной модели документа). Если бы вы использовали обычный клиент HTTP, который не отображает код Javascript, страница, которую вы получили бы, была бы почти пустой. Это одна из причин, почему безголовые браузеры так важны.
Другим преимуществом использования Headless Browser является то, что многие веб-сайты используют «запрос Javascript», чтобы определить, является ли HTTP-клиент ботом или реальным пользователем. Используя Headless Browser, вы, скорее всего, обойдете эти автоматические тесты и получите целевую HTML-страницу.
Тремя наиболее часто используемыми API для запуска безголовых браузеров являются Selenium, Puppeteer и Playright. Selenium — самый старый, он имеет библиотеки практически для всех языков программирования и поддерживает все основные браузеры.
Puppeteer поддерживает только NodeJS, он поддерживается командой Google и поддерживает Chrome (поддержка Firefox появится позже, на данный момент это экспериментально).
Playwright — новейший проигрыватель, поддерживается Microsoft и поддерживает все основные браузеры.
Правила извлечения — это логика, которую вы будете использовать для выбора элемента HTML и извлечения данных. Два самых простых способа выбора элементов HTML на странице — это селекторы XPath и селекторы CSS.
Как правило, это основная логика вашего веб-конвейера. Это то, на что ваши разработчики чаще всего тратят время. Веб-сайты часто обновляют свой HTML (особенно стартапы), поэтому вам часто придется обновлять эти селекторы XPath и CSS.
Планирование работы — еще одна важная часть. Вы можете отслеживать цены каждый день или каждую неделю. Другое преимущество использования системы планирования заданий заключается в том, что вы можете повторить неудачное задание. Обработка ошибок чрезвычайно важна при парсинге веб-страниц. Может произойти много ошибок, которые находятся вне вашего контроля. Обратите внимание на следующее:
- HTML-код на странице изменился, что нарушило ваши правила извлечения
- Целевой веб-сайт может быть недоступен.
- Также возможно, что ваш прокси-сервер работает медленно или не работает.
- Запрос может быть заблокирован.

Планирование заданий и обработка ошибок могут выполняться с помощью любой формы брокера сообщений и библиотек планирования заданий, таких как Sidekiq в Ruby или RQ в Python.
Хранилище : После извлечения данных с веб-сайта обычно требуется их где-нибудь сохранить. Собранные данные обычно хранятся в следующих распространенных форматах:
- JSON
- CSV
- XML
- В базу данных SQL или noSQL
Мониторинг Ваш конвейер парсинга веб-страниц очень важен. Как было сказано ранее, при извлечении данных из сети в больших масштабах может возникнуть много проблем. Вам нужно следить за тем, чтобы ваши парсеры не ломались, чтобы прокси работали исправно. Splunk — отличный инструмент для анализа журналов, настройки панели мониторинга и оповещений. Существуют также альтернативы с открытым исходным кодом, такие как Kibana и весь стек ELK.
Существуют также альтернативы с открытым исходным кодом, такие как Kibana и весь стек ELK.
Scrapy
Scrapy — это платформа для парсинга веб-страниц с открытым исходным кодом на Python. На наш взгляд, это отличная отправная точка для извлечения структурированных данных с веб-сайтов в любом масштабе. Он решает многие распространенные проблемы очень элегантным способом:
- Concurrency (очистка нескольких страниц одновременно)
- Автоматическое регулирование, чтобы не мешать сторонним веб-сайтам, с которых вы извлекаете данные
- Гибкий формат экспорта, CSV, JSON, XML и серверная часть для хранения (Amazon S3, FTP, облако Google…)
- Автоматическое сканирование
- Встроенный медиаконвейер для загрузки изображений и ресурсов
Если вы хотите глубже изучить Scrapy, мы написали подробное руководство по очистке веб-страниц с помощью Scrapy.
Скребковая пчела
ScrapingBee может помочь вам как с управлением прокси, так и с безголовыми браузерами. Это отличное решение, когда вы не хотите иметь дело ни с тем, ни с другим.
Это отличное решение, когда вы не хотите иметь дело ни с тем, ни с другим.
Существует множество проблем с запуском неактивных браузеров в рабочей среде. Легко запустить один экземпляр Selenium или Puppeteer на своем ноутбуке, но запуск десятков в продакшене — это совсем другое дело. Во-первых, вам нужны мощные серверы. Например, для безголового Chrome требуется не менее 1 ГБ оперативной памяти и одно ядро ЦП для бесперебойной работы.
Хотите запустить 50 экземпляров Chrome без управления параллельно? Это 50 ГБ оперативной памяти и 50 ядер процессора. Затем вам понадобится либо один гигантский сервер с «голым железом» стоимостью тысячи долларов в месяц, либо множество небольших серверов.
Кроме того, вам понадобится балансировщик нагрузки, мониторинг и, возможно, размещение всего этого в контейнерах докеров. Это большая работа, и это одна из проблем, которые мы решаем в ScrapingBee. Вместо того, чтобы делать все вышеперечисленное, вы можете использовать ScrapingBee с помощью простого вызова API.
Другое приятное место для ScrapingBee — управление прокси. Многие веб-сайты используют ограничения скорости IP на своих страницах. Допустим, веб-сайт допускает 10 запросов в день с одного IP-адреса. Если вам нужно выполнить 100 000 запросов за один день, вам потребуется 10 000 уникальных прокси. Это много. Как правило, прокси-провайдеры берут от одного до трех долларов за уникальный IP-адрес в месяц. Счет может взорваться очень быстро.
Со ScrapingBee вы получаете доступ к огромному пулу прокси за небольшую часть стоимости.
Извлечение данных из Интернета без кода / с низким кодом
В ScrapingBee мы любим код! Но что, если в вашей компании нет разработчиков? Есть еще решения! Некоторые решения не содержат кода, для других требуется небольшой код (API). Это особенно эффективно, если вам нужны данные для разового проекта, а не на постоянной основе.
Брокеры данных
Если вам нужен огромный объем данных из Интернета для определенного варианта использования, вы можете проверить, что набор данных еще не существует. Например, допустим, вам нужен список всех веб-сайтов в мире, использующих определенную технологию, например Shopify. Было бы огромной задачей просканировать всю сеть или каталог (если такой каталог существует), чтобы получить этот список.
Вы можете легко получить этот список, купив его у брокеров данных, таких как buildwith.com 9.0003
Например, допустим, вам нужен список всех веб-сайтов в мире, использующих определенную технологию, например Shopify. Было бы огромной задачей просканировать всю сеть или каталог (если такой каталог существует), чтобы получить этот список.
Вы можете легко получить этот список, купив его у брокеров данных, таких как buildwith.com 9.0003
API для конкретных веб-сайтов
Если вам нужно получить данные с определенного веб-сайта (в отличие от множества разных веб-сайтов), может существовать существующий API, который вы могли бы использовать. Например, у нас в ScrapingBee есть специальный API поиска Google. Преимущество использования API заключается в том, что вам не нужно заниматься обслуживанием, когда целевой веб-сайт обновляет свой HTML-код. Это означает отсутствие мониторинга с вашей стороны, никаких обновлений правил извлечения, и вам не нужно постоянно иметь дело с блокировкой прокси-серверов.
Кроме того, убедитесь, что целевой веб-сайт не предлагает общедоступный или частный API для доступа к данным, как правило, это экономически выгодно, и вы потратите меньше времени, чем пытаясь получить данные самостоятельно.
Расширение веб-браузера
Расширение веб-браузера может быть эффективным способом извлечения данных с веб-сайта. Лучше всего, когда вы хотите извлечь хорошо отформатированные данные, например, таблицу или список элементов на странице. Некоторые расширения, такие как DataMiner, предлагают готовые рецепты парсинга для популярных веб-сайтов, таких как Amazon, Ebay или Wallmart.
Инструменты веб-скрейпинга
Инструменты веб-скрейпинга, такие как ScreamingFrog или ScrapeBox, отлично подходят для извлечения данных из Интернета и, в частности, из Google. В зависимости от вашего варианта использования, такого как SEO, исследование ключевых слов или поиск неработающих ссылок, это может быть самым простым в использовании.
Другие программы, такие как ParseHub, также отлично подходят для людей, не имеющих навыков программирования. Это настольные приложения, которые упрощают извлечение данных из Интернета. Вы создаете инструкции в приложении, такие как выбор нужного элемента, прокрутка и т. д.
д.
Однако у этих программ есть ограничения, и кривая обучения крутая.
Поручите работу агентствам по парсингу или фрилансерам
Существует множество агентств по парсингу и фрилансеров, которые могут помочь вам с извлечением данных из Интернета. Аутсорсинг может быть полезен, когда ваша проблема не может быть решена с помощью решения без кода.
Фрилансеры — наиболее гибкое решение, поскольку они могут адаптировать свой код к любому веб-сайту. Выходной формат может быть каким угодно: CSV, JSON, выгрузка данных в базу данных SQL…
Самый простой способ найти фрилансеров — это зайти на Upwork.com или Toptal (https://www.toptal.com/)
Агентства веб-скрейпинга — еще одно отличное решение, особенно для крупномасштабного парсинга. . Если вам нужно разрабатывать и поддерживать парсеры для многих сайтов, вам, вероятно, понадобится команда, один фрилансер не справится со всем.
Заключительные мысли
Это был длинный пост в блоге, теперь вы должны хорошо знать различные способы извлечения данных из Интернета.