Поиск по html коду: Поиск связанных между собой сайтов по коду Google Analytics
Содержание
Поиск связанных между собой сайтов по коду Google Analytics
Допустим, вы нашли в сети анонимный веб-сайт и хотите узнать, кто его создал. Воспользовавшись уникальным кодом, вы можете найти связь между этим ресурсом и другими сайтами и даже узнать, кто является их собственником. С правильными инструментами найти интересующую вас информацию будет очень легко.
Поиск сайтов по коду
При помощи популярного сервиса Google Analytics веб-разработчики собирают данные о посещаемости (такие как страна, тип браузера и оперативной системы) по пользователям разных доменов. Для этого в html-код каждой страницы добавляется уникальный идентификационный номер (код) – именно благодаря ему можно проследить связь между различными сайтами. По такому же принципу работают Google AdSense, Amazon и AddThis.
Существует несколько ресурсов, позволяющих выполнить обратный поиск этого уникального кода и найти связанные сайты. Лично мне больше всего нравится работать с http://sameid.
net (производит поиск не только по коду Analytics и AdSense, но и по коду Amazon, Clickbank и Addthis) и с http://www.spyonweb.com. SpyOnWeb совершенно бесплатный, а вот на SameID без оплаты предоставляются только пять запросов в день.
Результаты поиска кода Analytics на сайте SameID
Более продвинутым пользователям могу посоветовать ресурс NerdyData https://search.nerdydata.com/, который ищет совпадения по любому введенному фрагменту кода. В платной версии есть очень удобная функция сохранения результатов поиска. Но иногда этот сайт отображает один и тот же результат несколько раз, и из-за этого на поиск уходит много времени.
В NerdyData можно ввести любой код и просмотреть результаты поиска.
Meanpath.com – аналогичный по функциональности сайт для поиска кодов, в бесплатной версии выводится не более 100 результатов.
Советую использовать сразу несколько инструментов, потому что они иногда предоставляют разные результаты. В ходе эксперимента я выяснил, что SpyOnWeb выдает меньше результатов, чем SameID, а в Meanpath было два результата, которых не нашли ни SpyOnWeb, ни SameID.
Еще коды Analytics или AdSense можно ввести в поиск в Google – только не забудьте заключить их в кавычки (например, “UA-12345678”). Таким образом вы получите результаты обратного поиска из других инструментов. Кроме того, если адрес или код Analytics сайта недавно был изменен, через Google вам, возможно, удастся найти сохраненные в кэш результаты из сервисов по типу SameID и все-таки выйти на связанный сайт. Чтобы просмотреть сохраненную копию, нажмите на зеленую направленную вниз стрелку рядом с результатом:
Сверка с кодом страницы
Результаты, выданные средствами поиска по коду, необходимо проверить. Делается это просто – при просмотре кода домашней страницы веб-сайта.
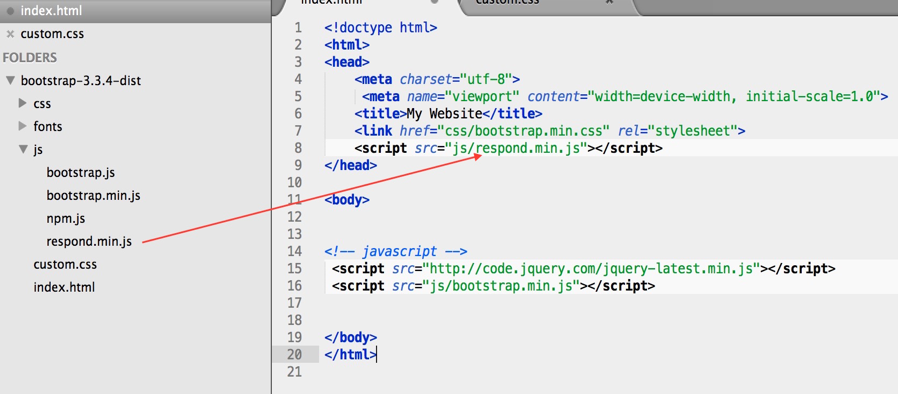
Для этого в браузерах Firefox, Chrome, Internet Explorer и Opera нажмите правой кнопкой мыши на любое место на странице и в появившемся контекстном меню выберите View Source или Source (Просмотр кода страницы / Исходный код / Просмотр HTML-кода).
В браузере Safari для этого нужно открыть меню Page (Страница) в правом верхнем углу окна и выбрать аналогичную команду.
После этого появится окно с исходным кодом – в нем мы будем искать код Analytics. Для этого выберите Edit (Изменить / Редактировать) > Find (Найти) или воспользуйтесь комбинацией клавиш CTRL + F для Windows (аналогичная комбинация для Mac: ⌘ + F). Введите в строку поиска следующие теги:
AdSense: Pub- или ca-pub
Analytics: UA-
Amazon: &tag=
AddThis: #pubid / pubid
Поиск кода Google Analytics в исходном коде страницы
Поиск связанных сайтов через сервисы WHOIS
Из данных о том, на кого зарегистрирован домен, мы можем извлечь ценную информацию о лицах, связанных с интересующим нас сайтом. Эти данные включают имена, адреса электронной почты, почтовые адреса, номера телефонов. Конечно, не исключено, что они уже устарели, но для нас это не принципиально – мы просто ищем связь между сайтами.
Существует множество сервисов WHOIS, рекомендую вам всегда проверять найденную информацию по нескольким сервисам. Мне нравится https://who.is/, который отображает как историю регистрации сайта, так и текущие данные. Это оказывается особенно полезным в том случае, если сайт недавно был переведен на анонимную регистрацию.
Сайт Domaintools, где представлены адрес электронной почты и название организации, зарегистрировавшей домен, – при помощи этих данных можно найти связь с другими сайтами.
Есть еще http://whois.domaintools.com, где, помимо прочего, указаны тип и версия серверного программного обеспечения, используемого на сайте, и примерное количество размещенных на нем изображений. Whoisology выдает не только архивные результаты, но и домены, зарегистрированные по определенным адресам электронной почты.
Отображение всех доменов, зарегистрированных по одному и тому же адресу электронной почты, на сайте Whoisology.
Некоторые сервисы WHOIS не распознают кириллические URL-адреса. Для преобразования адреса воспользуйтесь этим инструментом: Verisign IDN Conversion Tool.
Использование метаданных
Основная масса изображений и документов, загруженных в сеть, содержит метаданные – информацию, записанную при создании или редактировании файла. Один из журналистов Bellingcat Мелисса Хэнхем уже написала о том, как использовать метаданные при геолокации. Нас же интересует, как метаданные помогут нам найти связанные сайты.
В социальных сетях, таких как Facebook и Twitter, метаданные удаляются автоматически, но на большинстве других ресурсов такого нет. Метаданные часто сохраняются на небольших веб-сайтах и в блогах. Два, на мой взгляд, наиболее удобных инструмента для просмотра метаданных – http://fotoforensics.com/ (только для фотографий) и Jeffrey’s EXIF Viewer (также анализирует документы, в том числе PDF, Word и OpenOffice.)
Метаданные документа в формате ODF на сайте Jeffrey’s EXIF Viewer.
Существует много разных видов метаданных, но нас в первую очередь интересуют EXIF, Maker Notes, ICC Profile, Photoshop и XMP.
Результаты анализа метаданных на FotoForensics.
В них содержится такая информация, как точная версия редактора изображений. Например, в поле XMP «Creator Tool» может стоять «Microsoft Windows Live Photo Gallery 15.
4.3555.308». В поле «XMP Toolkit» часто отображаются похожие данные, например «Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27». Главное – выбрать поля, где указана конкретная и подробная информация. При анализе фотографии иногда отображается модель фотоаппарата, на который она была сделана (например, «KODAK DX4330 DIGITAL CAMERA»).
Разумеется, одна и та же версия Photoshop или одинаковый фотоаппарат могут быть у миллионов разных людей, так что эту информацию следует использовать только при наличии других надежных доказательств, таких как код Google Analytics. Но в метаданных документа встречаются и более конкретные сведения, например имя автора.
Иногда в метаданных фотографии даже может быть указан уникальный серийный номер фотоаппарата. Проведите обратный поиск по такой информации при помощи инструментов http://www.stolencamerafinder.com/ и http://www.cameratrace.com/, чтобы найти другие снимки, сделанные этим же устройством.
Сохранение страниц
Часто бывает такое, что веб-контент неожиданно изменяется или исчезает – а вместе с ним и все важные для нас коды Analytics. К счастью, у нас есть возможность сохранять веб-страницы. Предпочтительно сохранять не только сайты, которые вы изучаете, но и результаты поиска из SameID и других сервисов.
Для быстрого и удобного сохранения воспользуйтесь Internet Archive Wayback Machine. После архивации содержание страницы нельзя изменить, так что вряд ли кто-то возьмется оспаривать ее подлинность.
Кроме того, Wayback Machine вставляет дату и время в код архивированной страницы, так что этому инструменту доверяют даже криминалисты.
Сервис WebCite похож на Wayback Machine, но здесь пользователю разрешается редактировать некоторые данные. Для просмотра кода архивной страницы вместо View Source вам придется использовать View Frame Source (This Frame в браузере Firefox). Но плюсы у этого сервиса тоже есть – он отправляет адреса архивированных страниц в ваш почтовый ящик. Существует также Archive.is, он очень удобен для сохранения профилей из социальных сетей.
Есть одна загвоздка – все эти инструменты позволяют архивировать вручную только отдельные страницы, но не весь сайт. Кроме того, они не будут работать, если ресурс защищен от поисковых роботов или автоматического копирования контента с целью его размещения на других сайтах. В этом случае лучше всего будет сохранить отдельные страницы на компьютер и/или сделать скриншот. Я пользуюсь бесплатным инструментом Web Page Saver с сайта Magnet Forensics, хотя в некоторых случаях подойдут также Windows Snipping Tool и DropBox.
Кроме того, имеет смысл вручную добавить страницу в индекс Google. Тогда она с больше вероятностью будет сохранена в кэш Google, где вы потом сможете ее найти.
Графическое отображение
Если вы изучаете большую группу сайтов, то в связях между ними легко запутаться. Для удобства организуйте их в диаграмму.
Бесплатное приложение yEd Graph Editor (для операционных систем Windows, OS X и Linux) – очень удобный инструмент для составления как простых, так и сложных графиков и диаграмм. Чтобы сделать диаграмму, просто перетащите иконки мышкой в нужное место и обозначьте связь между ними.
Для начала внесите все элементы, которые вам удалось найти: адреса сайтов, имена, названия организаций и уникальные коды. Если вы узнали что-то новое, не забудьте добавить эту информацию в диаграмму. В приложении yEd есть иконки, обозначающие компьютеры, файлы, людей и т. д., так что можете дать волю креативности.
Выбор диаграмм и графиков достаточно большой. В этом примере я воспользовался диаграммами Circular и BCC Isolated, отобразив в виде круга сайты, каждый из которых связан с расположенным в центре кодом Analytics.
Выводы
В этой статье мы рассмотрели открытые источники информации и инструменты, которые позволяют найти связь между сайтами, на первый взгляд не имеющими ничего общего. Мы также выяснили, что чтобы никто не сомневался в результатах нашего расследования, необходимо искать подтверждение в других источниках и всегда сохранять найденные страницы.
Исследование и редактирование HTML — Инструменты разработчика Firefox
Исследовать и редактировать HTML-код страницы можно в панели HTML.
Навигационная цепочка для HTML-кода
Она показывает полную иерархию элементов содержащей выбранный элемент ветви документа:
Нажатие и удержание левой кнопки мыши на одном из элементов навигационной панели вызывает меню, позволяющее выбрать какой-либо из соседних элементов. Кнопки со стрелками на левом и правом концах панели цепочки прокручивают цепочку, если она длиннее доступного пространства.
С версии Firefox 34, при наведении указателя мыши на элемент навигационной цепочки соответствующий элемент подсвечивается на странице.
Поле поиска
Щёлкните в поле поиска, чтобы его раскрыть, потом введите, что вы ищете. Вы увидите подсказку с результатами поиска.
Нажмите «Enter». Будет выбран первый элемент этого типа на странице, а повторное нажатие «Enter» найдёт следующий.
Можно искать тег, или ввести любую другую строку селекторов CSS, так что можно найти элемент с ID myId, введя строку #myId.
Начиная с Firefox 40, можно искать по атрибутам class или id без учёта формата селекторов CSS, так что для поиска соответствующего элемента достаточно ввести просто myId.
Дерево HTML
Остальная часть панели показывает HTML-код страницы в виде дерева. Прямо слева от каждого узла есть стрелочка, нажатие на которую раскрывает узел. Если при нажатии на стрелочку удерживать кнопку Alt, раскрываются и узел, и все его потомки.
Наведение указателя мыши на узел в дереве подсвечивает соответствующий элемент на странице.
Узлы, скрытые с помощью display:none, показываются бледнее (как и совсем не отображаемые узлы, например <head>).
::before и ::after
Начиная с Firefox 35, можно исследовать псевдо-элементы, добавленные с помощью ::before и ::after:
Некоторые частые операции с узлом можно выполнять с помощью контекстного меню. Чтобы открыть это меню, щёлкните правой кнопкой по желаемому элементу:
Меню содержит следующие пункты:
Править как HTML
HTML-код элемента
Копировать внутренний HTML
Скопировать innerHTML элемента
Копировать внешний HTML
Скопировать outerHTML элемента
Копировать уникальный селектор
Скопировать CSS-селектор, выбирающий этот и только этот элемент.
Копировать URL данных изображения
Скопировать изображение в формате data:// URL, если выбранный элемент изображение.
Показать свойства DOM
Открыть split console и ввести туда команду «inspect($0)», чтобы исследовать текущий выбранный элемент.
Вставить внутренний HTML
Вставить содержимое буфера в узел в качестве его innerHTML (en-US).
Вставить внешний HTML
Вставить содержимое буфера в узел в качестве его outerHTML (en-US).
Вставить/Перед
Вставить содержимое буфера в документ прямо перед этим узлом.
Вставить/После
Вставить содержимое буфера в документ прямо после этого узла.
Вставить/Как первого потомка
Вставить содержимое буфера в документ в качестве первого дочернего элемента этого узла.
Вставить/Как последнего потомка
Вставить содержимое буфера в документ в качестве последнего дочернего элемента этого узла.
Прокрутить в вид
Прокручивает веб-страницу, чтобы был виден выбранный узел.
Удалить узел
Удалить элемент
Открыть ссылку в новой вкладке
(только в меню, открытом для ссылки, например атрибута href) Открывает в новой вкладке то, на что ссылка.
Открыть файл в Отладчике
(только в меню, открытом для ссылки на код JS) Открывает в отладчике файл, на который ссылка.
Открыть файл в Редакторе стилей
(только в меню, открытом для ссылки на CSS) Открывает код, на который ссылка, в Редакторе стилей.
Копировать адрес ссылки
(только в меню для URL) Скопировать URL.
:hover
Установить CSS-псевдокласс :hover
:active
Установить CSS-псевдокласс :active
:focus
Установить CSS-псевдокласс :focus
Вы можете редактировать HTML — теги, атрибуты и содержимое — прямо в панели HTML: сделайте двойной щелчок по тексту, который вы хотите изменить, измените его, нажмите Enter, — и изменения сразу же будут применены.
Чтобы редактировать outerHTML (en-US) элемента, откройте контекстное меню элемента и выберите «Править как HTML». Вы увидите в панели HTML поле для редактирования текста:
Вы можете добавлять здесь любой HTML: изменять тег элемента, редактировать существующие элементы, добавлять новые. Как только вы кликнете вне поля редактирования, изменения будут применены к странице.
Копирование и вставка
Перетаскивание
Новое в Firefox 39.
С версии Firefox 39 можно редактировать HTML перетаскиванием узлов в дереве HTML. Просто нажмите и удерживайте кнопку мыши на каком-нибудь элементе, и перетащите его вверх или вниз по дереву. Когда вы отпустите кнопку, элемент будет вставлен в соответствующем месте:
Онлайн просмотр html кода
– Автор:
Игорь (Администратор)
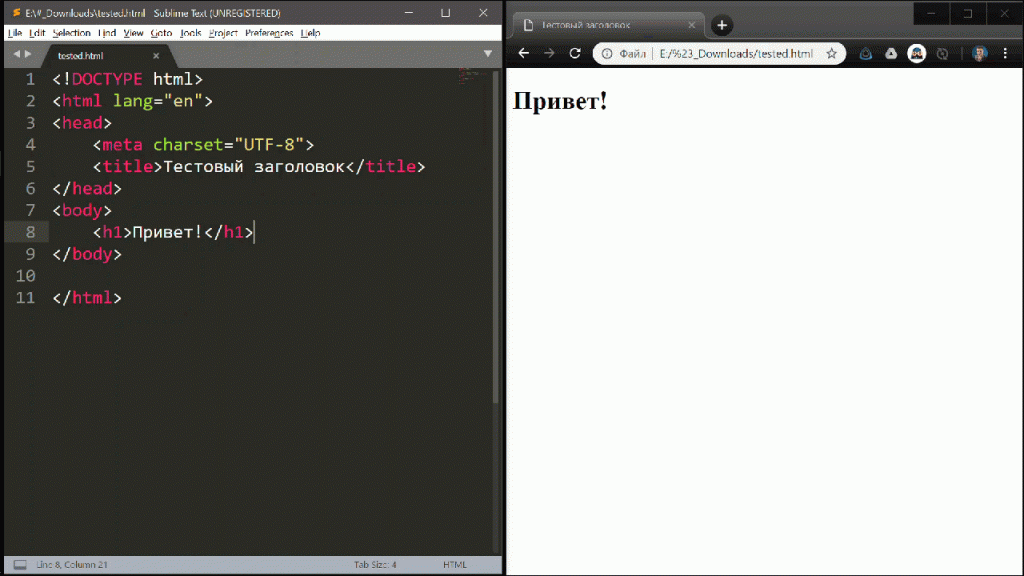
Иногда, может возникать необходимость быстро посмотреть, как будет выглядеть html код. И решений существует масса. Кто-то использует различные редакторы, позволяющие вставлять html. Кто-то использует возможность браузеров динамически изменять содержимое любой открытой страницы. Несмотря на относительную простоту, обычно, у таких подходов есть один существенный минус. Это необходимость совершать множество лишних действий. Открыть страницу. Перейти на вкладку или открыть редактор браузера. Подождать пока появится окно или загрузится вкладка. Найти нужную кнопку или найти подходящий элемент для вставки. И только после этого вставить html код. Но, есть решение гораздо проще, это данный инструмент под названием «Онлайн просмотр html кода». Все, что вам необходимо сделать, это вставить html в поле ввода текста, после чего автоматически будет сформировано его визуальное представление.
Поле для ввода html текста:
Переформировать
Кроме того, у решений с использованием визуальных редакторов и редакторов браузеров есть еще один недостаток, о котором пользователи далеко не всегда задумываются. Это применение дополнительных стилей. В случае с wysiwyg редакторами, обычно, все теги html предварительно корректируются самим редактором, так что вполне возможно, что некоторые стили попросту пропадут. Так же необходимо учитывать, что некоторые wysiwyg редакторы накладывают свои стили поверх основных. В случае с редакторами браузеров, проблема заключается в CSS стилях, которые используются на открытой странице. Они могут переопределять стили вставляемого html-кода. В любом случае, какой бы из этих методов вы не использовали, всегда будет существовать риск, что просмотренный вами html текст будет совершенно по другому отображаться в том месте, где вы его в последствии используете.
Данный же Онлайн просмотр html кода не имеет такой проблемы, так как создает отдельный iframe, внутрь которого помещается html текст так, как он был вставлен в поле для ввода.
Теперь, у вас всегда будет под рукой удобный инструмент для просмотра html кода.
☕ Хотите выразить благодарность автору? Поделитесь с друзьями!
Онлайн конвертер HTML в BBCode и обратно
Online MD5 Калькулятор
Добавить комментарий / отзыв
как найти ошибки в HTML и CSS
Как проверить CSS и HTML-код на валидность и зачем это нужно.
Разберем, насколько критическими для работы сайта и его продвижения могут быть ошибки в HTML-коде, и зачем нужны общие стандарты верстки.
Что такое валидность кода
После разработки дизайна программисты верстают страницы сайта — приводят их к единой структуре в формате HTML. Задача верстальщика — сделать так, чтобы страницы отображались корректно у всех пользователей на любых устройствах и браузерах. Такая верстка называется кроссплатформенной и кроссбраузерной — это обязательное требование при разработке любых сайтов.
Для этого есть специальные стандарты: если им следовать, страницу будут корректно распознавать все браузеры и гаджеты. Такой стандарт разработал Консорциумом всемирной паутины — W3C (The World Wide Web Consortium). HTML-код, который ему соответствует, называют валидным.
Валидность также касается файлов стилей — CSS. Если в CSS есть ошибки, визуальное отображение элементов может нарушиться.
Разработчикам рекомендуется следовать критериям этих стандартов при верстке — это поможет избежать ошибок в коде, которые могут навредить сайту.
Чем ошибки в HTML грозят сайту
Типичные ошибки кода — незакрытые или дублированные элементы, неправильные атрибуты или их отсутствие, отсутствие кодировки UTF-8 или указания типа документа.
Какие проблемы могут возникнуть из-за ошибок в HTML-коде
страницы загружаются медленно;
сайт некорректно отображается на разных устройствах или в браузерах;
посетители видят не весь контент;
программист не замечает скрытую рекламу и вредоносный код.
Как валидность кода влияет на SEO
Валидность не является фактором ранжирования в Яндекс или Google, так что напрямую она не влияет на позиции сайта в выдаче поисковых систем. Но она влияет на мобилопригодность сайта и на то, как поисковые боты воспринимают разметку, а от этого косвенно могут пострадать позиции или трафик.
Почитать по теме: Главное о микроразметке: подборка знаний для веб-мастеров
Представитель Google Джон Мюллер говорил о валидности кода:
«Мы упомянули использование правильного HTML. Является ли фактором ранжирования валидность HTML стандарту W3C?
Это не прямой фактор ранжирования. Если ваш сайт использует HTML с ошибками, это не значит, что мы удалим его из индекса — я думаю, что тогда у нас будут пустые результаты поиска.
Но есть несколько важных аспектов:
— Если у сайта действительно битый HTML, тогда нам будет очень сложно его отсканировать и проиндексировать. — Иногда действительно трудно подобрать структурированную разметку, если HTML полностью нарушен, поэтому используйте валидатор разметки. — Другой аспект касается мобильных устройств и поддержки кроссбраузерности: если вы сломали HTML, то сайт иногда очень трудно рендерить на новых устройствах».
Итак, критические ошибки в HTML мешают
сканированию сайта поисковыми ботами;
определению структурированной разметки на странице;
рендерингу на мобильных устройствах и кроссбраузерности.
Даже если вы уверены в своем коде, лучше его проверить — ошибки могут возникать из-за установки тем, сторонних плагинов и других элементов, и быть незаметными. Не все программисты ориентируются на стандарт W3C, так что среди готовых решений могут быть продукты с ошибками, особенно среди бесплатных.
Как проверить код на валидность
Не нужно вычитывать код и считать символы — для этого есть сервисы и инструменты проверки валидности HTML онлайн.
Что они проверяют:
Синтаксис Синтаксические ошибки: пропущенные символы, ошибки в написании тегов.
Вложенность тэгов Незакрытые и неправильно закрытые теги. По правилам теги закрываются также, как их открыли, но в обратном порядке. Частая ошибка — нарушенная вложенность
.
DTD (Document Type Definition) Соответствие кода указанному DTD, правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов — то, чего нет в DTD, но есть в коде.
Обычно сервисы делят результаты на ошибки и предупреждения. Ошибки — опечатки в коде, пропущенные или лишние символы, которые скорее всего создадут проблемы. Предупреждения — бессмысленная разметка, лишние символы, какие-то другие ошибки, которые скорее всего не навредят сайту, но идут вразрез с принятым стандартом.
Валидаторы не всегда правы — некоторые ошибки не мешают браузерам воспринимать код корректно, зато, к примеру, минификация сокращает длину кода, удаляя лишние пробелы, которые не влияют на его отображение.
Почитать по теме: Уменьшить вес сайта с помощью gzip, brotli, минификации и других способов
Поэтому анализируйте предложения сервисов по исправлениям и ориентируйтесь на здравый смысл.
Перед исправлением ошибок не забудьте сделать резервное копирование. Если вы исправите код, но что-то пойдет не так и он перестанет отображаться, как должен, вы сможете откатить все назад.
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Есть довольно много валидаторов, выберите тот, в котором вам удобнее работать. Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
Валидатор от W3C
Англоязычный сервис, онлайн проверяет соответствие HTML стандартам: можно проверить код по URL, залить файл или вставить код в окошко.
Инструмент покажет список ошибок и предупреждений с пояснениями — описанием ошибки и ее типом, а также укажет номер строки, в которой нужно что-то исправить. Цветом отмечены типы предупреждений и строчки с кодом.
Фрагмент примера проверки
Валидатор CSS от W3C
Инструмент от W3C для проверки CSS, есть русский язык. Работает по такому же принципу, анализирует стили на предмет ошибок и предупреждений. Первым идет блок ошибок, предупреждения собраны ниже отдельно.
Проверка CSS
Проверить HTML можно с помощью браузерных плагинов, к примеру, Web-developer или HTML Validation Bookmarklet для Google Chrome, HTML Validator для Firefox и Google Chrome, Validator или W3C Markup Validation Service для Opera, или другого решения из списка инструментов.
Исправления ошибок и валидации HTML и CSS может быть недостаточно: всегда есть другие возможности испортить отображение сайта. Если что-то не работает, как надо, проведите полноценный аудит, чтобы найти ошибки.
С другой стороны, не зацикливайтесь на поиске недочетов в HTML — если код работает, а контент отображается корректно, лучше направить ресурсы на что-то другое — оптимизацию и ускорение загрузки, например.
Расширенный поиск
Закупка является совместной
Отображать только закупки, извещения которых размещены обособленными подразделениями заказчика
Закупка за счет средств бюджета Союзного государства
Закупка товара, работы, услуги по государственному оборонному заказу в соответствии с ФЗ № 275-ФЗ от 29 декабря 2012 г
Медицинские изделия
Отобразить только закупки, по которым заключен контракт жизненного цикла
Выводить только закупки, созданные представителями Заказчиков
Возможность размещения своего HTML-кода присутствует только на тарифе «Про». Этот функционал предназначен для тех, кто профессионально разбирается в вебе, нуждается в расширенных возможностях и точно знает, что с ними будет делать.
Внимание!
Работа с этим виджетом требует знаний HTML, CSS и JavaScript. Написание кода с ошибками может привести к некорректной работе и отображению сайта.
Разместить свой HTML-код можно:
В конструкторе — перетащите виджет «Html-код» на сайт и кликните по нему для редактирования содержимого:
Примечание:
Этот блок нужно использовать в том случае, если вы размещаете какой-то внешний виджет на сайт или любые другие HTML-элементы, например таблицу или любой другой блок с содержимым.
В head или в конец body — используйте виджет «Свой код» в панели управления uKit:
В настройках можно выбрать место расположения кода и страницы, на которых он будет размещен:
Примечание:
В <head> размещаются мета-теги, подключаемые внешние библиотеки (скрипты) и прочее. В конец <body> обычно размещаются скрипты, которые должны срабатывать после полной загрузки страницы.
Важно:
Чтобы изменения вступили в силу, необходимо опубликовать сайт.
Работа с jQuery-скриптами
В случае, если вы хотите использовать jQuery-скрипты на вашем сайте, то это необходимо делать особым образом, поскольку библиотека jQuery подключается в uKit нестандартным способом. Все jQuery-скрипты должны размещаться в панели управления вашего сайта в разделе «Свой код». При этом код обязательно должен размещаться «В конец <body>». Все ваши скрипты должны оборачиваться библиотекой require.js следующим образом:
<script> require([‘jquery’], function ($) { Ваш код, написанный на jQuery }) </script>
Помогла ли вам статья?
Статья оказалась полезной для 136 человек
Как просмотреть HTML код страницы на iPhone или iPad
Если вы так или иначе имеете отношение к веб-разработке (по учебе, работе или просто из личного интереса), вам рано или поздно потребуется посмотреть исходный код сайта на вашем смартфоне или планшете Apple. Но как это сделать?
♥ ПО ТЕМЕ: 20 функций камеры iPhone, которые должен знать каждый владелец смартфона Apple.
Как посмотреть исходный код интернет-страницы на Айфоне или Айпаде
Для начала нам потребуется соответствующее приложение. В App Store таких программ достаточно много, и большинство из них предлагают удобные инструменты вроде подсветки синтаксиса.
Хороший вариант для работы с HTML – приложение HTML Viewer Q. Программа распространяется бесплатно и предлагает весь необходимый функционал. Скачать приложение можно из App Store.
После того, как программа будет загружена и установлена на ваш iPhone или iPad, сделайте следующее:
1. Откройте приложение HTML Viewer Q на вашем устройстве.
2. Нажмите на кнопку Link в правом верхнем углу.
3. Введите полный URL-адрес страницы, для которой вы хотите посмотреть код, и нажмите кнопку Go.
4. После того, как страница загрузится, нажмите на кнопку Код в верхнем левом углу экрана.
Готово – перед вами только что открылся HTML-код указанной страницы.
Несколько слов о полезных возможностях программы:
Если текст кода кажется вам слишком мелким, в HTML Viewer Q есть возможность увеличить его до комфортного размера. Доступные варианты – 9, 12, 16 и т.д.
Встроенный поиск позволяет находить информацию. Всё, что нужно сделать – указать в поисковой строке ключевое слово или синтаксис.
HTML Viewer Q также позволяет скопировать HTML-код со страницы для вставки в любую другую программу.
Смотрите также:
[Как сделать] — HTML-код поисковой системы для веб-сайта
Создание собственной поисковой системы с помощью HTML, CSS, JS может показаться довольно простым и легким для небольших веб-сайтов с несколькими сотнями страниц. Но если количество страниц очень велико, порядка нескольких тысяч или миллионов страниц, таких как электронная коммерция. Управлять службой поиска и запускать ее абсолютно сложно, так как для ее создания требуется множество специальных навыков. несколько сложных программных компонентов, таких как.
Вставка HTML-кода поисковой системы с использованием HTML CSS JavaScript
Создание собственной поисковой системы с помощью HTML, CSS, JS может показаться довольно простым и легким для небольших веб-сайтов с несколькими сотнями страниц, но количество страниц очень велико в от нескольких тысяч до миллионов страниц, таких как электронная коммерция.Управлять службой поиска и запускать ее абсолютно сложно, так как для ее создания требуется множество специальных навыков. несколько сложных программных компонентов, таких как.
Краулер: сканирует веб-сайт
Индексатор: считывает проанализированные данные и создает инвертированный индекс (похожий на тот, который вы найдете в конце книги), ускоряющий поисковые системы для получения результатов. В противном случае поисковой системе придется просмотреть все документы один за другим. Это сокращает время обработки.
Анализатор: обрабатывает данные сканера, сохраняет метаданные.
Ранжирование результатов поиска: Для каждого поискового запроса поисковая система извлекает множество документов/результатов. Этот ранкер упорядочивает эти результаты на основе некоторого балла. Google использует алгоритм, известный как алгоритм рейтинга страниц. Вы также можете придумать собственный алгоритм подсчета очков.
Поиск Пользовательский интерфейс: Большинство пользователей выполняют поиск в браузерах или мобильных приложениях через интерфейс поисковой системы. Обычно это создается с использованием JavaScript.
В этой статье я хотел бы предложить вам услуги, которые предоставляют поиск как услугу, и вы можете просто подключить и играть и получить поиск по веб-сайту менее чем за 5 минут.
Шаги для получения поисковой системы Использование ExpertRec Search as Service
Перейдите на https://cse.expertrec.com?platform=cse и зарегистрируйтесь, используя свой идентификатор Gmail.
Введите URL-адрес, для которого необходимо создать поиск. Система автоматически построит поиск и создаст код, который необходимо добавить на ваш сайт.
Введите URL-адрес карты сайта, если он есть. Это необязательно. Это позволит сканеру более эффективно находить все страницы на вашем веб-сайте, но вы можете пропустить их.
Далее вы получите HTML-код поисковой системы для добавления на все страницы вашего сайта.
Вы можете использовать существующее окно поиска на своем сайте или добавить совершенно новое.
Существует демо-версия, которую вы можете проверить перед добавлением поиска на свой сайт.
После того, как этот код будет добавлен на веб-сайт, в него будет интегрирована функция поиска, как показано ниже:
Вы можете управлять настройками поиска — внешний вид, предложения, изображения, выделение , ранжирование в поиске, фильтрация и т. д.
Добавить HTML-код поисковой системы с помощью пользовательского поиска Google
Что такое пользовательский поиск Google?
Это способ использования индекса Google для поиска на определенном веб-сайте, группе веб-сайтов или во всей сети. Google имеет много слоев индекса. Пользовательский поиск Google будет использовать только основной индекс (только страницы с самым высоким рейтингом, с учетом многих квот). Вспомогательные индексы, такие как новости, индексы в реальном времени, карты и остальная часть Интернета, сюда не включены. Кроме того, многие приукрашивания, которые вы видите в обычных результатах, здесь не включены.Например. вы не получите запуск калькулятора, если будете искать арифметическое выражение в пользовательском поиске Google. Объявления будут запускаться как средство получения дохода для Google. Ниже приведена реклама Google в первые дни существования GCS.
Добавление системы пользовательского поиска Google обеспечит автоматический подход к предоставлению функций поиска для веб-сайта.
Действия по созданию HTML-кода поисковой системы с помощью системы пользовательского поиска Google
Введите URL-адрес своего веб-сайта и нажмите «Создать»
Замените код окна поиска кодом пользовательского окна поиска Google. На этом шаге вы вам может понадобиться помощь вашего разработчика. Вам нужно поместить приведенный выше код встраивания туда, где вы хотите, чтобы окно поиска отображалось.
Вот и все! вы добавили пользовательский поиск Google на свой веб-сайт.
Недостатки использования Google Custom Search
Нет контроля над тем, что и когда индексировать — Google решает, какие из ваших страниц сканировать и когда.Вы не можете заставить сканеры Google сканировать ваш сайт по запросу. Принимая во внимание, что с помощью службы поиска, такой как expertrec, вы можете сканировать в режиме реального времени, как только публикуете новые страницы.
Нет контроля над результатами поиска — Существуют определенные поисковые запросы, по которым Google может не дать вам ожидаемых результатов поиска, и вы ничего не можете с этим поделать, если хотите, чтобы один результат поиска был наверху. С expertrec это так же просто, как перетаскивание одного результата поиска над другим с помощью нашей панели управления.
Нет поддержки — Вы полностью предоставлены сами себе при реализации пользовательского поиска Google. Вы не можете ожидать, что инженер службы поддержки Google поможет вам настроить вашу поисковую систему или запустить ее. Существуют довольно хорошие ресурсы документации, которые помогут вам реализовать пользовательский поиск Google. То же самое не относится к Google Adwords, где есть группа поддержки, которая поможет вам в настройке ваших рекламных кампаний.
Минимальные параметры настройки пользовательского интерфейса — Панель управления пользовательским поиском Google предлагает очень ограниченные возможности настройки пользовательского интерфейса по сравнению с другими поставщиками поиска, такими как expertrec.Это означает, что вы застряли со скучным пользовательским интерфейсом поисковой системы.
Может быть закрыт или изменен в любое время- Будь то Orkut, поиск по сайту Google, Google известен тем, что безжалостно закрывает проекты, которые не приносят им денег. Это означает, что вы ищете альтернативы, и для некоторых людей это может быть болезненным поиском.
Algolia Search
Algolia — это API поиска и обнаружения сайтов для веб-сайтов и мобильных приложений. Они помогают создавать мощные, актуальные и масштабируемые возможности обнаружения для своих пользователей.Более 6000 компаний используют Algolia для управления 50 миллиардами поисковых запросов в месяц. Вы также можете использовать algolia для выполнения поиска по сайту.
Функции поиска Algolia
Беспрецедентная скорость поиска: Результаты отображаются сразу же, как только пользователь вводит текст, а страница результатов мгновенного поиска обновляется продуктами и категориями в режиме реального времени. Мгновенные результаты означают, что поиск удобен даже на мобильных устройствах.
Релевантность и синонимы: Параметры ранжирования позволяют расставлять приоритеты в результатах, которые направляют клиентов к вашим самым продаваемым и самым популярным продуктам.Расширенная устойчивость к опечаткам и сопоставление синонимов гарантируют, что вы всегда приводите пользователей именно к тому, что они ищут.
Надежность: SLA 99,99 %: мы позаботимся о том, чтобы ваш поиск работал в любое время. Предоставьте одинаковую расширенную производительность поиска Magneto всем своим пользователям, независимо от того, в какой части мира они находятся, путем репликации ваших данных в любом из 52 центров обработки данных в нашей распределенной поисковой сети.
Фильтры и фасеты: Пользовательские фильтры и фасеты обновляются по мере того, как пользователи выполняют поиск, превращая панель поиска в удобный инструмент поиска по мере ввода текста.
Расширенная аналитика: Простые сведения о том, что ищут ваши клиенты и какие поисковые запросы они используют, — на одной центральной панели.
Резюме
Итак, теперь у вас есть четкое представление о том, как вставлять HTML-код поисковой системы на веб-сайт. Кроме того, вы бы поняли, чем expertrec лучше пользовательского поиска Google. HTML-код поисковой системы активирует окно поиска на вашем сайте. Результаты поиска будут ограничены вашим сайтом.
Это самый быстрый способ создать поисковую систему, и вы можете опробовать все возможности этой поисковой системы в течение 14-дневного бесплатного пробного периода.
Вставьте HTML-код поисковой системы ExpertRec на свой веб-сайт
Как читать исходный код веб-сайта
Под всеми изображениями, текстом и призывами к действию на вашем веб-сайте находится исходный код веб-страницы.
Google и другие поисковые системы «читают» этот код, чтобы определить, где ваши веб-страницы должны отображаться в их индексах для данного поискового запроса.
Это краткое руководство, которое покажет вам, как читать исходный код вашего собственного веб-сайта, чтобы убедиться, что он оптимизирован для SEO. Я также рассмотрю несколько других ситуаций, когда знание того, как просматривать и анализировать нужные части исходного кода, может помочь в других маркетинговых усилиях.
Как просмотреть исходный код
Первым шагом в проверке исходного кода вашего веб-сайта является просмотр фактического кода. Каждый веб-браузер позволяет вам сделать это легко. Ниже приведены команды клавиатуры для просмотра исходного кода вашей веб-страницы для ПК и Mac.
ПК
Firefox: CTRL + U (Это означает, что нажмите и удерживайте клавишу CTRL на клавиатуре. Удерживая клавишу CTRL, нажмите клавишу «u».) Кроме того, вы можете перейти в меню «Firefox» и затем нажмите «Веб-разработчик», а затем «Исходный код страницы».
Edge/ Internet Explorer : CTRL + U. Или щелкните правой кнопкой мыши и выберите «Просмотр исходного кода».
Chrome : CTRL + U. Или вы можете нажать на странную клавишу с тремя горизонтальными линиями в правом верхнем углу.Затем нажмите «Инструменты» и выберите «Просмотр исходного кода».
Opera : CTRL + U. Вы также можете щелкнуть правой кнопкой мыши веб-страницу и выбрать «Просмотр исходного кода страницы».
Mac
Safari: Комбинация клавиш — Option+Command+U. Вы также можете щелкнуть правой кнопкой мыши веб-страницу и выбрать «Показать исходный код страницы».
Firefox : Вы можете щелкнуть правой кнопкой мыши и выбрать «Источник страницы» или перейти в меню «Инструменты», выбрать «Веб-разработчик» и нажать «Источник страницы».Сочетание клавиш — Command + U.
Chrome: Перейдите к «Просмотр», нажмите «Разработчик», а затем «Просмотреть исходный код». Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Комбинация клавиш — Option+Command+U.
Если вы знаете, как просматривать исходный код, вам нужно знать, как искать в нем что-то. Обычно те же функции поиска, которые вы используете для обычного просмотра веб-страниц, применимы к поиску в вашем исходном коде. Такие команды, как CTRL + F (для поиска), помогут вам быстро просмотреть исходный код на наличие важных элементов SEO.
Теги заголовка исходного кода
Тег title — святой Грааль SEO на странице. Это самое важное в вашем исходном коде. Если вы хотите что-то вынести из этой статьи, обратите внимание на это:
.
Вы знаете, какие результаты выдает Google, когда вы что-то ищете?
Все эти результаты получены из тегов заголовков веб-страниц, на которые они указывают. Если у вас нет тегов title в исходном коде, вы не сможете появиться в Google (или в любой другой поисковой системе, если уж на то пошло).Хотите верьте, хотите нет, но я действительно видел веб-сайты без тегов заголовков!
Теперь давайте быстро поищем в Google термин «Руководства по маркетингу»:
Вы можете видеть, что первый результат относится к разделу блога KISSmetrics, посвященному маркетинговым руководствам. Если мы нажмем на этот первый результат и просмотрим исходный код страницы, мы увидим тег title:
.
Тег заголовка обозначается открывающим тегом:
. Заканчивается закрывающим тегом:. Тег title обычно находится в верхней части исходного кода в разделе.
Вы видите, что содержание внутри тега title соответствует тому, что используется в заголовке первого результата Google.
Мало того, что теги заголовков необходимы для включения в результаты поиска Google, Google также идентифицирует важные ключевые слова в вашем заголовке, которые, по их мнению, имеют отношение к поисковым запросам пользователей.
Если вы хотите, чтобы определенная веб-страница ранжировалась по определенной теме, вам лучше убедиться, что слова, описывающие эту тему, находятся в теге заголовка.Чтобы узнать больше о важности ключевых слов и тегов заголовков в общей архитектуре сайта, ознакомьтесь с этой статьей.
И последнее, что нужно помнить: каждая веб-страница на вашем веб-сайте должна иметь уникальный тег заголовка. Никогда не дублируйте этот контент.
Если у вас небольшой веб-сайт, например, 10 или 20 страниц, достаточно легко проверить уникальность каждого тега заголовка. Однако, если у вас большой веб-сайт, вам понадобится помощь. Это простой четырехэтапный процесс:
Шаг №1: Откройте Ubersuggest, введите URL-адрес и нажмите «Поиск»
Шаг № 2: Нажмите «Аудит сайта» на левой боковой панели
Шаг № 3: Обзор основных проблем SEO
После перехода к обзору аудита сайта прокрутите вниз до четвертого раздела результатов (он последний на странице), чтобы просмотреть основные проблемы SEO.
Здесь вы найдете дублирующиеся теги заголовков или метаописания. Если здесь ничего не отображается, вы в безопасности. Если вы видите дубликаты, например, 30 страниц моего веб-сайта, копайте глубже.
Шаг № 4: Нажмите «Страницы с повторяющимися тегами



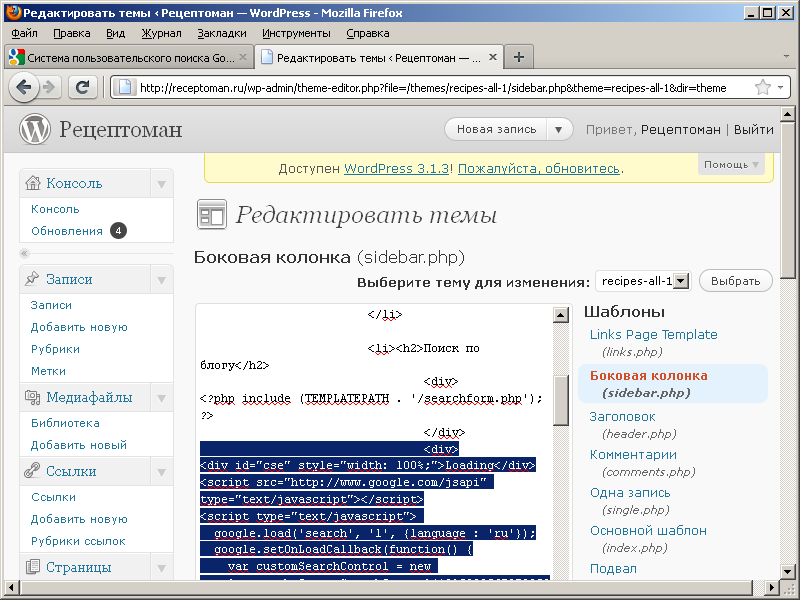
 Мне нравится https://who.is/, который отображает как историю регистрации сайта, так и текущие данные. Это оказывается особенно полезным в том случае, если сайт недавно был переведен на анонимную регистрацию.
Мне нравится https://who.is/, который отображает как историю регистрации сайта, так и текущие данные. Это оказывается особенно полезным в том случае, если сайт недавно был переведен на анонимную регистрацию. Один из журналистов Bellingcat Мелисса Хэнхем уже написала о том, как использовать метаданные при геолокации. Нас же интересует, как метаданные помогут нам найти связанные сайты.
Один из журналистов Bellingcat Мелисса Хэнхем уже написала о том, как использовать метаданные при геолокации. Нас же интересует, как метаданные помогут нам найти связанные сайты.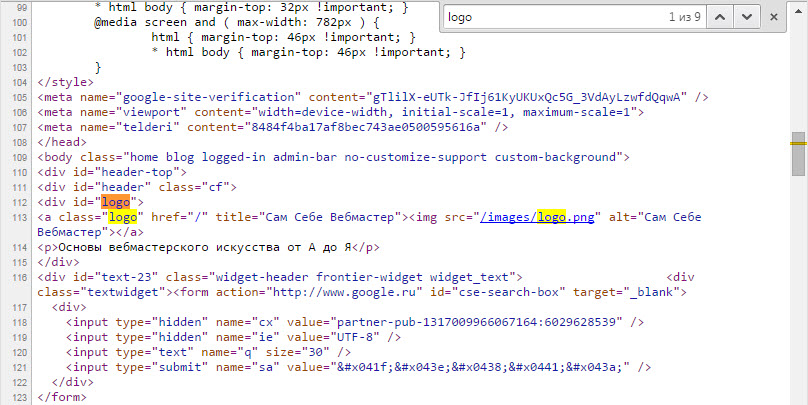
 К счастью, у нас есть возможность сохранять веб-страницы. Предпочтительно сохранять не только сайты, которые вы изучаете, но и результаты поиска из SameID и других сервисов.
К счастью, у нас есть возможность сохранять веб-страницы. Предпочтительно сохранять не только сайты, которые вы изучаете, но и результаты поиска из SameID и других сервисов.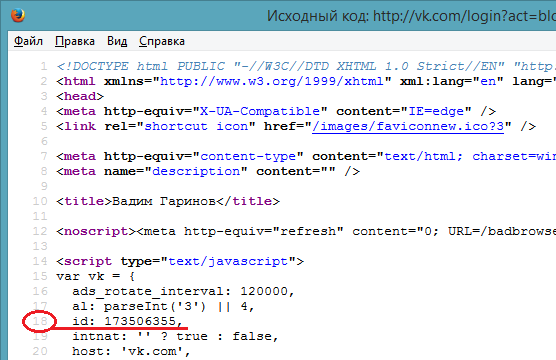 Кроме того, они не будут работать, если ресурс защищен от поисковых роботов или автоматического копирования контента с целью его размещения на других сайтах. В этом случае лучше всего будет сохранить отдельные страницы на компьютер и/или сделать скриншот. Я пользуюсь бесплатным инструментом Web Page Saver с сайта Magnet Forensics, хотя в некоторых случаях подойдут также Windows Snipping Tool и DropBox.
Кроме того, они не будут работать, если ресурс защищен от поисковых роботов или автоматического копирования контента с целью его размещения на других сайтах. В этом случае лучше всего будет сохранить отдельные страницы на компьютер и/или сделать скриншот. Я пользуюсь бесплатным инструментом Web Page Saver с сайта Magnet Forensics, хотя в некоторых случаях подойдут также Windows Snipping Tool и DropBox.


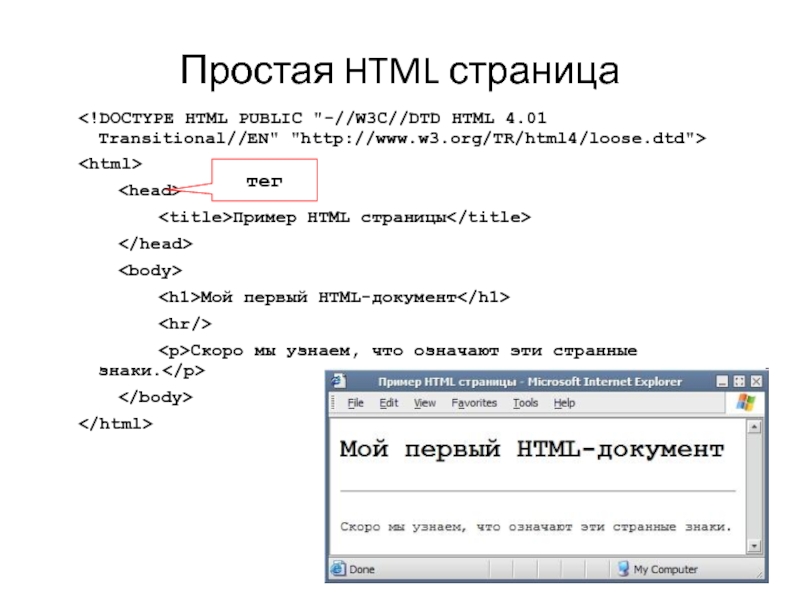

 И решений существует масса. Кто-то использует различные редакторы, позволяющие вставлять html. Кто-то использует возможность браузеров динамически изменять содержимое любой открытой страницы. Несмотря на относительную простоту, обычно, у таких подходов есть один существенный минус. Это необходимость совершать множество лишних действий. Открыть страницу. Перейти на вкладку или открыть редактор браузера. Подождать пока появится окно или загрузится вкладка. Найти нужную кнопку или найти подходящий элемент для вставки. И только после этого вставить html код. Но, есть решение гораздо проще, это данный инструмент под названием «Онлайн просмотр html кода». Все, что вам необходимо сделать, это вставить html в поле ввода текста, после чего автоматически будет сформировано его визуальное представление.
И решений существует масса. Кто-то использует различные редакторы, позволяющие вставлять html. Кто-то использует возможность браузеров динамически изменять содержимое любой открытой страницы. Несмотря на относительную простоту, обычно, у таких подходов есть один существенный минус. Это необходимость совершать множество лишних действий. Открыть страницу. Перейти на вкладку или открыть редактор браузера. Подождать пока появится окно или загрузится вкладка. Найти нужную кнопку или найти подходящий элемент для вставки. И только после этого вставить html код. Но, есть решение гораздо проще, это данный инструмент под названием «Онлайн просмотр html кода». Все, что вам необходимо сделать, это вставить html в поле ввода текста, после чего автоматически будет сформировано его визуальное представление. Это применение дополнительных стилей. В случае с wysiwyg редакторами, обычно, все теги html предварительно корректируются самим редактором, так что вполне возможно, что некоторые стили попросту пропадут. Так же необходимо учитывать, что некоторые wysiwyg редакторы накладывают свои стили поверх основных. В случае с редакторами браузеров, проблема заключается в CSS стилях, которые используются на открытой странице. Они могут переопределять стили вставляемого html-кода. В любом случае, какой бы из этих методов вы не использовали, всегда будет существовать риск, что просмотренный вами html текст будет совершенно по другому отображаться в том месте, где вы его в последствии используете.
Это применение дополнительных стилей. В случае с wysiwyg редакторами, обычно, все теги html предварительно корректируются самим редактором, так что вполне возможно, что некоторые стили попросту пропадут. Так же необходимо учитывать, что некоторые wysiwyg редакторы накладывают свои стили поверх основных. В случае с редакторами браузеров, проблема заключается в CSS стилях, которые используются на открытой странице. Они могут переопределять стили вставляемого html-кода. В любом случае, какой бы из этих методов вы не использовали, всегда будет существовать риск, что просмотренный вами html текст будет совершенно по другому отображаться в том месте, где вы его в последствии используете.




 Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
 youtube.com/embed/I88ZGqKpg7E» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/I88ZGqKpg7E» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> В конец <body> обычно размещаются скрипты, которые должны срабатывать после полной загрузки страницы.
В конец <body> обычно размещаются скрипты, которые должны срабатывать после полной загрузки страницы. Но как это сделать?
Но как это сделать?
 Управлять службой поиска и запускать ее абсолютно сложно, так как для ее создания требуется множество специальных навыков. несколько сложных программных компонентов, таких как.
Управлять службой поиска и запускать ее абсолютно сложно, так как для ее создания требуется множество специальных навыков. несколько сложных программных компонентов, таких как. Это сокращает время обработки.
Это сокращает время обработки.
 Google имеет много слоев индекса. Пользовательский поиск Google будет использовать только основной индекс (только страницы с самым высоким рейтингом, с учетом многих квот). Вспомогательные индексы, такие как новости, индексы в реальном времени, карты и остальная часть Интернета, сюда не включены. Кроме того, многие приукрашивания, которые вы видите в обычных результатах, здесь не включены.Например. вы не получите запуск калькулятора, если будете искать арифметическое выражение в пользовательском поиске Google. Объявления будут запускаться как средство получения дохода для Google. Ниже приведена реклама Google в первые дни существования GCS.
Google имеет много слоев индекса. Пользовательский поиск Google будет использовать только основной индекс (только страницы с самым высоким рейтингом, с учетом многих квот). Вспомогательные индексы, такие как новости, индексы в реальном времени, карты и остальная часть Интернета, сюда не включены. Кроме того, многие приукрашивания, которые вы видите в обычных результатах, здесь не включены.Например. вы не получите запуск калькулятора, если будете искать арифметическое выражение в пользовательском поиске Google. Объявления будут запускаться как средство получения дохода для Google. Ниже приведена реклама Google в первые дни существования GCS.
 Принимая во внимание, что с помощью службы поиска, такой как expertrec, вы можете сканировать в режиме реального времени, как только публикуете новые страницы.
Принимая во внимание, что с помощью службы поиска, такой как expertrec, вы можете сканировать в режиме реального времени, как только публикуете новые страницы.
 Вы также можете использовать algolia для выполнения поиска по сайту.
Вы также можете использовать algolia для выполнения поиска по сайту.

 Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Комбинация клавиш — Option+Command+U.
Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Комбинация клавиш — Option+Command+U. Если у вас нет тегов title в исходном коде, вы не сможете появиться в Google (или в любой другой поисковой системе, если уж на то пошло).Хотите верьте, хотите нет, но я действительно видел веб-сайты без тегов заголовков!
Если у вас нет тегов title в исходном коде, вы не сможете появиться в Google (или в любой другой поисковой системе, если уж на то пошло).Хотите верьте, хотите нет, но я действительно видел веб-сайты без тегов заголовков!