PDF с точки зрения программиста / Хабр
Я имею дело с PDF не только как пользователь, а, прежде всего, как разработчик софта, умеющего его читать и писать (возможно, вы сталкивались с продуктами компании ABBYY, работающими с PDF – ABBYY FineReader, ABBYY PDF Transformer). Я предполагаю, что вы прочитали статью
habrahabr.ru/company/abbyy/blog/105006и далее пишу только про некоторые особенности и ограничения PDF, которые больше интересны продвинутым пользователям. Никаких сложных технических деталей при этом не буду касаться, так что программистам, желающим научиться читать или писать PDF, лучше сразу перейти к чтению спецификацию версии 1.7 со страницы
www.adobe.com/devnet/pdf/pdf_reference_archive.html🙂
Назначение и особенности PDF
Изначально формат PDF задумывался компанией Adobe ещё в конце 80х годов прошлого века как «электронная твёрдая копия» странично-структурированных документов, которую можно просматривать и печатать в виде, идентичном оригинальному, на разных машинах и платформах, но который не предполагается редактировать.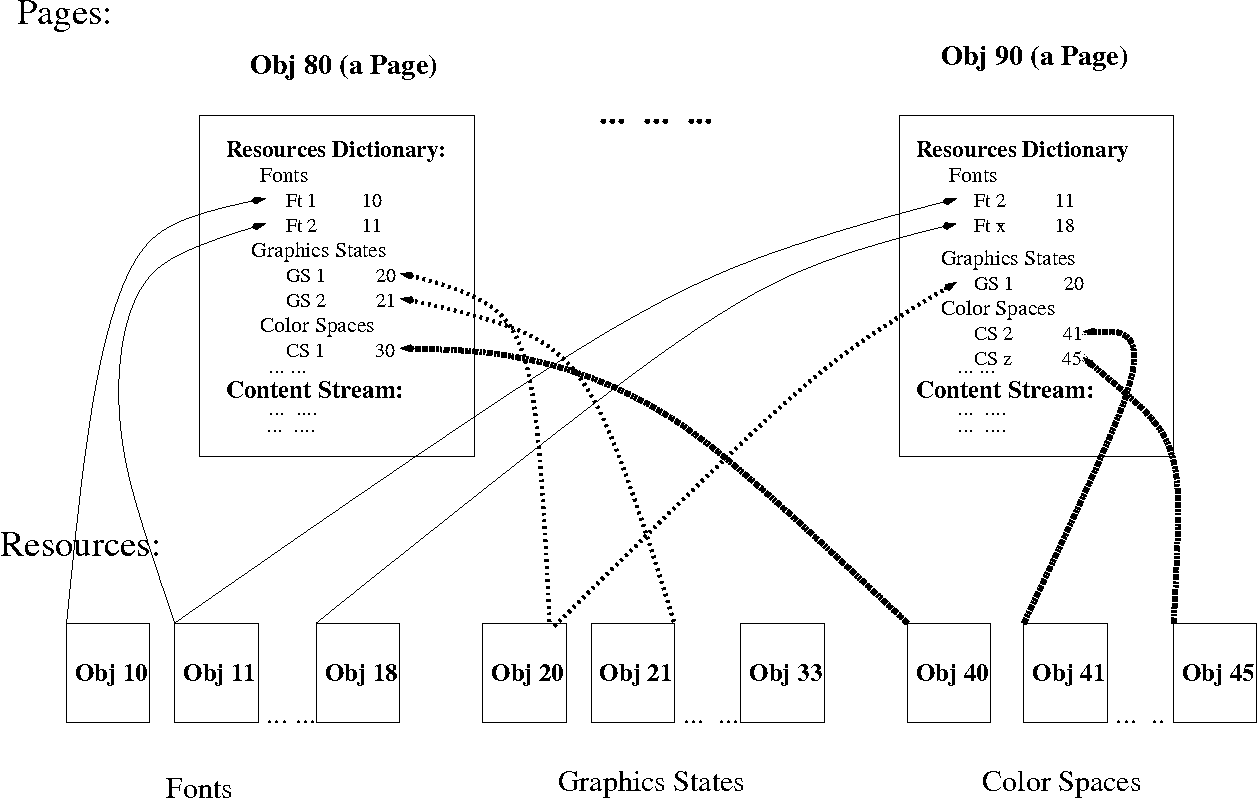 Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Так, форматы текстовых документов (DOC, RTF, DOCX и т.д.) в основном ориентированы не на просмотр, а на редактирование документов. Созданный разумным пользователем 🙂 документ логично реагирует на вставку/замену/удаление текста, картинок, таблиц в разных местах, изменение размеров и полей страниц, изменение форматирования фрагментов текста любого размера и тому подобные действия. Интернет страницы в формате HTML не слишком ориентированы на редактирование (хотя и допускают его), но при условии прямых рук автора нормально переносят отображение не только на экране монитора своего создателя, но и на устройствах с совершенно другими экранами и взаимодействием с пользователем.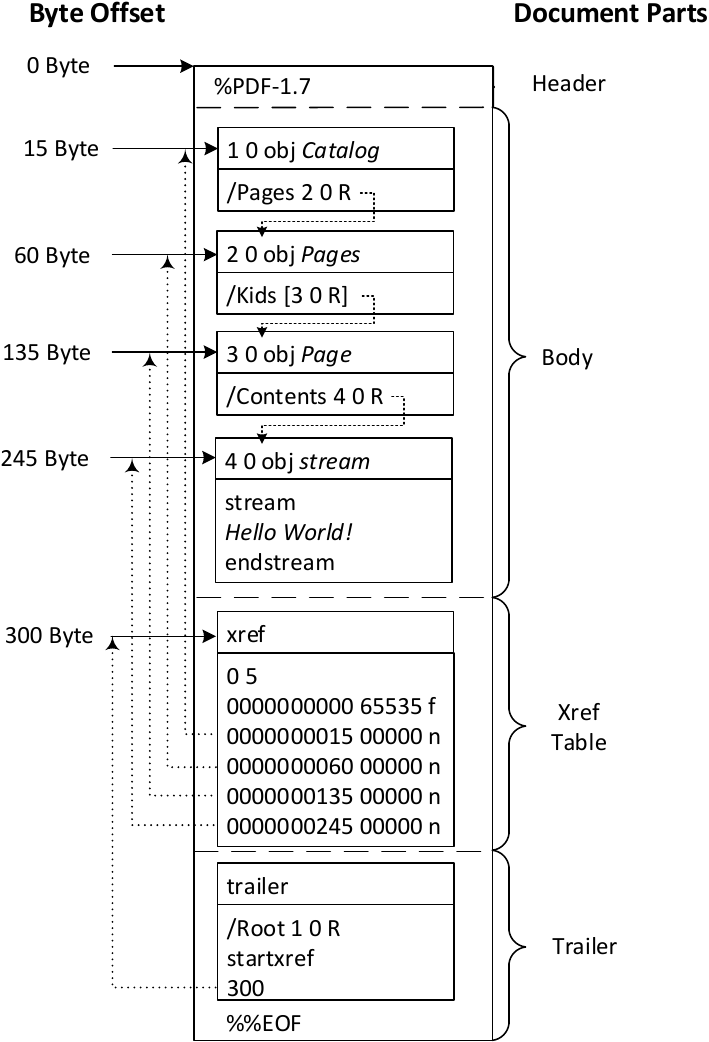
У PDF же особый путь – наибольшее распространение он получил как формат-паразит, в котором документы не создаются человеком «с нуля», а чаще всего порождаются из других форматов путём глубокой машинной переработки, теряющей многие или даже все детали, ненужные для отображения документа в фиксированном виде. Cамым распространенным способом получения PDF является печать на виртуальный PDF-принтер из любого приложения, имеющего в меню команду «Print».
PDF-принтер переводит GDI(«интерфейс графических устройств»)-команды вывода в нужные места символов, линий, кривых, прямоугольников, растровых изображений и прочих геометрических примитивов в соответствующие им PDF-команды с сохранением в файл. При этом, разумеется, сохраняются количество и размер страниц, на которое выполнялась печать.
Такое преобразование способно очень точно передать внешний вид того, что получилось, перед печатью (например, линии и символы не теряют своей чёткости при любом масштабировании и при этом хранятся достаточно компактно), но совершенно игнорирует устройство документа, из которого это получилось. Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи. В общем, сплошные имитация и надувательство. Такие PDF я ниже буду называть «векторными» (как состоящие из векторных команд, к которым относится и рисование символов).
Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи. В общем, сплошные имитация и надувательство. Такие PDF я ниже буду называть «векторными» (как состоящие из векторных команд, к которым относится и рисование символов).
Другой способ получения PDF-документов, ставший особенно популярным в последние годы, – переработка в него отсканированных бумажных страниц.
Некоторые современные приложения (в том числе приложения комплекта OpenOffice, Microsoft Office новых версий, ABBYY FineReader и ABBYY PDF Transformer) умеют создавать PDF самостоятельно, пользуясь при этом гораздо большим арсеналом средств, чем PDF-принтеры, ибо знают об исходном документе гораздо больше, чем нужно передать принтеру. Это позволяет сохранить, например, гиперссылки как таковые (а не просто как окрашенный и/или подчёркнутый текст) или описать некоторые элементы структуры документа для его переформатирования и показа на экранах малых разрешений.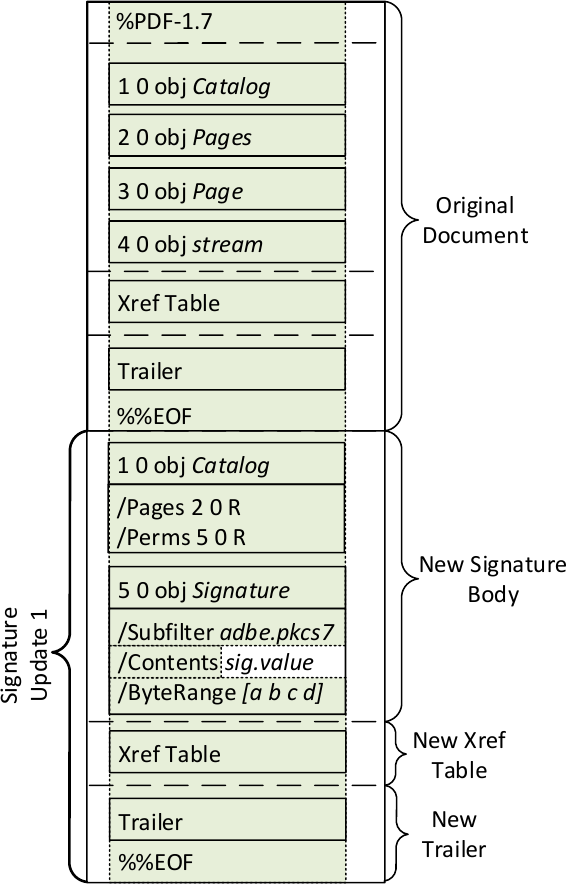
Преобразование PDF-документов в другие форматы
Желание отредактировать содержимое PDF-документа или преобразовать его в другие, желательно редактируемые форматы (как для немедленного редактирования, так и для хранения с возможностью поиска/редактирования «когда-нибудь»), возникает по разным причинам. Простейшие средства извлечения текстового содержимого предоставляет любое приложение, отображающее PDF – я имею привычный Copy-Paste, который работает довольно примитивно – как правило, теряется символьное и абзацное форматирование, игнорируются таблицы и сложная вёрстка PDF-документа. Есть приложения, которые позволяют «точечно» редактировать PDF без преобразования в другие форматы – но их арсенал средств редактирования очень ограничен, ну просто никакого сравнения с привычными текстовыми процессорами 🙂 В дорогущем Adobe Acrobat для многих документов единственным работающим видом редактирования является «аннотирование» – есть инструменты для добавления комментариев, выделения текста маркером, зачёркивания и т.п. Да, более продвинутое редактирование как бы есть, но вы, случайно, не встречали забавного сообщения «All or part of the selection has no available system font. You cannot add or delete text using the currently selected font.» при невинной попытке удалить символ или слово из «хорошего», «векторного» PDF-документа в Акробате? А не пробовали заменить фрагмент строки на более длинный, грустно наблюдая уползающие вправо хвосты строк? Если нет, значит любовь к продуктам Adobe у вас ещё впереди! К простым и привычным для текстовых процессоров задачам – например, «заменить за несколько секунд по всему документу слово «MS» на «Microsoft», с изменением размещения текста по колонкам и страницам» – такое «редактирование» и близко не стоит.
Простейшие средства извлечения текстового содержимого предоставляет любое приложение, отображающее PDF – я имею привычный Copy-Paste, который работает довольно примитивно – как правило, теряется символьное и абзацное форматирование, игнорируются таблицы и сложная вёрстка PDF-документа. Есть приложения, которые позволяют «точечно» редактировать PDF без преобразования в другие форматы – но их арсенал средств редактирования очень ограничен, ну просто никакого сравнения с привычными текстовыми процессорами 🙂 В дорогущем Adobe Acrobat для многих документов единственным работающим видом редактирования является «аннотирование» – есть инструменты для добавления комментариев, выделения текста маркером, зачёркивания и т.п. Да, более продвинутое редактирование как бы есть, но вы, случайно, не встречали забавного сообщения «All or part of the selection has no available system font. You cannot add or delete text using the currently selected font.» при невинной попытке удалить символ или слово из «хорошего», «векторного» PDF-документа в Акробате? А не пробовали заменить фрагмент строки на более длинный, грустно наблюдая уползающие вправо хвосты строк? Если нет, значит любовь к продуктам Adobe у вас ещё впереди! К простым и привычным для текстовых процессоров задачам – например, «заменить за несколько секунд по всему документу слово «MS» на «Microsoft», с изменением размещения текста по колонкам и страницам» – такое «редактирование» и близко не стоит.
Неслучайно в софтверной индустрии сформировалась целая отрасль, производящая средства конверсии с лучшей функциональностью. Из написанного выше (и особенно – ниже), должно стать понятно, насколько это непростая задача. Большинство пользователей, не читавших этого креатива, так не считают – поэтому я его и пишу 🙂
Основные проблемы при преобразовании PDF в другие форматы
Часто в обсуждении связанных с PDF вопросов употребляется понятие «текстового слоя». Интуитивно многими пользователями предполагается, что в PDF-файлах есть такие выделенные части, где логично и понятно описаны все нужные характеристики видимого текста – или невидимого, но находимого поиском или выделяемого мышью. Хочу открыть вам страшную тайну (вероятно, с риском в ближайшее время получить пулю от киллера, подосланного авторами формата PDF и их отделом маркетинга) – никакого текстового слоя в указанном смысле в PDF нет! На деле для каждой страницы есть общий поток команд её рисования, в котором совершенно произвольно перемешаны разнотипные команды – задания областей отсечения, смены текущих толщины, цвета и шаблона пунктирности линий, изменения системы координат, смены шрифта, рисования прямых и кривых (с текущими атрибутами), вывода группы символов с текущими атрибутами и указанными «номерами глифов» (глиф – описание изображение символа, без учёта других его характеристик), вывода растровых картинок и т.
Хуже другое – даже в пределах одной страницы PDF можно использовать (слишком) широкий набор средств изображения похожего глазу текста: буквы могут быть видны как части растрового изображения – например, в логотипах (задача их распознавания – в чистом виде задача OCR-приложений, того же ABBYY FineReader), как результат рисования кривыми Безье или специальными текстовыми командами. Этот последний случай – самый лучший для обработки, но даже здесь не обязательно указываются общепринятые коды символов из Unicode или других кодировок – ибо в PDF-файл можно записывать особые шрифты из подмножества только реально использованных символов и ссылаться на символы по совершенно условным «номерам глифов», а не по кодам. То есть не всегда просто как обнаружить символы в нужном месте, так и определить их коды! С форматированием, в том числе с выбором похожего шрифта при отсутствии точного аналога, всё ещё хитрее.
Символы, даже если их присутствие и коды тем или иным способом установлены, своим порядком вывода на страницу очень часто никак не соответствуют исходной последовательности их размещения и чтения на странице. Например, на двухколоночной странице команды вывода текста из правой и левой колонок могут быть произвольно перемешаны. На такой странице нужно выделить области, в каждой из которых размещён логически связный текст – это тоже задача, много лет решаемая OCR-приложениями. Некоторую помощь даёт структурная информация из тегированных PDF – но часто даже у сделанных сейчас PDF эта информация либо отсутствует – как при выводе через PDF-принтер – либо бывает недостаточно полна.
Когда мы решили, что в некоторых местах страницы есть связный текст (а где-то даже поняли, как он сгруппирован в таблицы – это очень нетривиальная задача!), и нашли, какие символы и в какие строчки складываются, нужно преобразовать эти строчки в абзацы и более высокоуровневые элементы, привычные пользователям как текстовых процессоров, так и HTML – колонки, таблицы, врезки. Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Только проделав всё это, можно превратить содержимое PDF в файл редактируемого формата, выглядящий похоже на оригинал и удобный для работы. Конечно, за многие годы многие умные люди в разных компаниях научились решать каждую из этих задач хорошо или даже отлично, но идеального решения всей задачи в целом я ещё не встречал. Но мы над этим работаем 🙂
Вячеслав Сапроненко SlaSapro
Департамент продуктов для распознавания текстов
Структурирование документов PDF в InDesign
Содержимое документа Adobe PDF можно повторно использовать для других целей. Например, предусмотрена возможность создания PDF-файла отчета с текстом, таблицами и изображениями для последующего распространения в различных форматах: для печати или чтения на полноразмерном мониторе, для просмотра на карманном устройстве, для озвучивания программой чтения с экрана и для прямого доступа через веб-браузер, как к HTML-странице. Базовая логическая структура документа определяет простоту и надежность повторного использования содержимого в будущем.
Например, предусмотрена возможность создания PDF-файла отчета с текстом, таблицами и изображениями для последующего распространения в различных форматах: для печати или чтения на полноразмерном мониторе, для просмотра на карманном устройстве, для озвучивания программой чтения с экрана и для прямого доступа через веб-браузер, как к HTML-странице. Базовая логическая структура документа определяет простоту и надежность повторного использования содержимого в будущем.
Чтобы гарантировать для документа Adobe PDF возможность повторного использования содержимого и надежность доступа, необходимо добавить в документ теги. При расстановке тегов в документ добавляется базовая организационная структура, или дерево логической структуры. Дерево логической структуры обращается к таким организационным элементам содержимого, как титульные листы, главы, разделы и подразделы. Оно определяет четкий порядок чтения и упрощает навигацию без изменения внешнего вида документа PDF, особенно в длинных и сложных документах.
Надежный доступ к содержимому документа с помощью дерева логической структуры обеспечивают вспомогательные программы, позволяющие читать содержимое документа людям с ослабленным зрением. На основе именно этой структуры большинство таких вспомогательных программ преобразуют смысл содержимого и изображений в альтернативный формат (например, в звуковой). В неразмеченном документе подобная структура отсутствует, поэтому программа Acrobat вводит структуру на основе последовательности чтения, выбранной в установках. Этот метод является ненадежным и часто приводит к тому, что элементы страницы прочитываются в неправильном порядке или вообще не читаются.
Теги отображаются на вкладке «Теги» в Acrobat 6.0 и более поздних версиях, где они вложены в соответствии с определениями отношений для размеченных элементов. В версии Acrobat Standard редактирование тегов не предусмотрено. Если для выполнения конкретной задачи требуется работать непосредственно с тегами, необходимо обновить приложение до версии Acrobat 9 Professional. Дополнительные сведения см. в справке Acrobat.
Дополнительные сведения см. в справке Acrobat.
[Перевод] Подробное объяснение в формате PDF
1. Введение
Все мы знаем, что злоумышленники включают какой-либо шелл-код в PDF-документы. Существует множество атак, использующих какую-то уязвимость для анализа PDF-документов и представления их пользователям для выполнения вредоносного кода в целевой системе.
На рисунке ниже показан популярный PDF ReaderAdobe Acrobat ReaderКоличество найденных уязвимостей. Количество уязвимостей увеличивается с годами, но количество уязвимостей, обнаруженных в этом году, немного меньше (но этот год еще не закончился). Самая важная лазейкаВыполнение кодаУязвимости злоумышленники могут использовать эти уязвимости для выполнения произвольного кода на целевой системе (если Acrobat Reader не был исправлен).
Это важный показатель, и мы должны регулярно обновлять нашу программу для чтения PDF, потому что количество обнаруженных недавно уязвимостей очень сложно.
2. Структура файла PDF
Всякий раз, когда мы хотим обнаружить новые уязвимости в программном обеспечении, мы должны сначала понять протокол или формат файла, в котором мы пытаемся обнаружить новые уязвимости. В нашем примере мы должны сначала понять формат файла PDF в деталях. В этой статье мы разберемся с форматом файла PDF и его внутренней структурой.
PDF — это переносимый формат документов, который можно использовать для представления документов, содержащих текст, изображения, мультимедийные элементы, ссылки на веб-страницы и т. Д. Имеет широкий спектр функций. Сначала мы должны понять, что спецификация формата файла PDFздесьОн общедоступен и может быть использован любым, кто интересуется форматом PDF. Формат файла PDF имеет почти 800 страниц, поэтому чтение не является быстрым однодневным чтением, но занимает много времени.
PDF имеет больше функций, чем текст, он может содержать изображения и другие мультимедийные элементы, может быть защищен паролем, может выполнять JavaScript и т. Д. Основная структура файла изображения показана ниже:
Д. Основная структура файла изображения показана ниже:
Каждый документ PDF содержит следующие элементы:
— Название:Это первая строка файла PDF, в которой указан номер версии спецификации PDF, используемой в документе. Если мы хотим найти его, мы можем использовать шестнадцатеричный редактор или просто использоватьxxdКоманда выглядит следующим образом:
<span># xxd temp.pdf | head -n 1
0000000: 2550 4446 2d31 2e33 0a25 c4e5 f2e5 eba7 %PDF-1.3.%......
</span>В PDF-документе temp.pdf используется спецификация PDF 1.3. Символ «%» является комментарием в PDF, поэтому приведенный выше пример фактически показывает, что первая и вторая строки являются комментариями, что справедливо для всех документов PDF. Следующие байты взяты из следующего вывода: 2550 4446 2d31 2e33 0a25 c4e5, что соответствует тексту ASCII «% PDF-1.3.%». Ниже приведены некоторые символы ASCII, в которых используются непечатаемые символы (обратите внимание на точку «. »). Эти символы обычно говорят некоторым программным продуктам, что файл содержит двоичные данные и не должен рассматриваться как 7-битный текст ASCII. Формат номера текущей версии: 1.N, где N варьируется от 0 до 7.
»). Эти символы обычно говорят некоторым программным продуктам, что файл содержит двоичные данные и не должен рассматриваться как 7-битный текст ASCII. Формат номера текущей версии: 1.N, где N варьируется от 0 до 7.
—текст:В теле документа PDF некоторые объекты обычно включают текстовые потоки, изображения и другие мультимедийные элементы. Раздел «Текст» используется для сохранения всех данных документа, отображаемых пользователю.
-xref таблица:Это таблица перекрестных ссылок, которая содержит ссылки на все объекты в документе. Цель таблицы перекрестных ссылок — обеспечить произвольный доступ к объектам в файле, поэтому нам не нужно читать весь документ PDF, чтобы найти конкретные объекты. Каждый объект представлен записью в таблице перекрестных ссылок, длина которой всегда составляет 20 байтов. Давайте возьмем пример:
<span>xref
0 1
0000000023 65535 f
3 1
0000025324 00000 n
21 4
0000025518 00002 n
0000025632 00000 n
0000000024 00001 f
0000000000 00001 f
36 1
0000026900 00000 n
</span>
Мы можем отобразить таблицу перекрестных ссылок PDF-документов, просто открыв PDF-файл с помощью текстового редактора и прокрутив его до конца документа. В приведенном выше примере мы видим, что у нас есть четыре подраздела (обратите внимание, что четыре строки содержат только два числа). Первое число в этих строках соответствует номеру объекта, а второе — количество объектов в текущем подразделе. Каждый объект представлен записью длиной 20 байт (включая CRLF). Первые 10 байтов — это смещение объекта от начала документа PDF до начала объекта. Далее идет разделитель пробела, где другое число указывает номер поколения объекта. Затем есть еще один разделитель пробела, за которым следует буква «f» или «n», указывающая, свободен ли объект или используется.
В приведенном выше примере мы видим, что у нас есть четыре подраздела (обратите внимание, что четыре строки содержат только два числа). Первое число в этих строках соответствует номеру объекта, а второе — количество объектов в текущем подразделе. Каждый объект представлен записью длиной 20 байт (включая CRLF). Первые 10 байтов — это смещение объекта от начала документа PDF до начала объекта. Далее идет разделитель пробела, где другое число указывает номер поколения объекта. Затем есть еще один разделитель пробела, за которым следует буква «f» или «n», указывающая, свободен ли объект или используется.
Идентификатор первого объекта равен 0 и всегда содержит запись с номером сборки 65535, который находится в начале списка свободных объектов (обратите внимание, что буква «f» означает «свободный»). Последний объект в таблице перекрестных ссылок использует номер поколения 0.
Второй подраздел имеет идентификатор объекта 3 и содержит элемент 1. Объект 3 начинается с 25324 байтов в начале документа. В третьем подразделе четыре объекта: идентификатор первого подобъекта — 21, и он начинается со смещения 25518 в начале файла. Другие объекты имеют последующие номера 22, 23 и 24. Все объекты отмечены знаком «f» или «n». Флаг ‘f’ указывает, что объект все еще может существовать в файле, но помечен как свободный, поэтому его не следует использовать. Эти объекты содержат ссылку на следующий свободный объект и номер поколения, который будет использоваться, когда объект снова вступит в силу. Флаг ‘n’ используется для обозначения действительных и используемых объектов, которые содержат смещение от начала файла до номера поколения объекта.
В третьем подразделе четыре объекта: идентификатор первого подобъекта — 21, и он начинается со смещения 25518 в начале файла. Другие объекты имеют последующие номера 22, 23 и 24. Все объекты отмечены знаком «f» или «n». Флаг ‘f’ указывает, что объект все еще может существовать в файле, но помечен как свободный, поэтому его не следует использовать. Эти объекты содержат ссылку на следующий свободный объект и номер поколения, который будет использоваться, когда объект снова вступит в силу. Флаг ‘n’ используется для обозначения действительных и используемых объектов, которые содержат смещение от начала файла до номера поколения объекта.
Обратите внимание, что нулевой объект указывает на следующий свободный объект в таблице, а именно на объект 23. Но поскольку объект 23 также свободен, он указывает на следующий свободный объект в таблице, объект 24. Но объект 24 является последним свободным объектом в файле. Таким образом, это указывает на объект ноль. Если мы будем использовать каждый номер объекта для представления таблицы перекрестных ссылок, это будет выглядеть так:
<span>xref
0 1
0000000023 65535 f
3 1
0000025324 00000 n
21 1
0000025518 00002 n
22 1
0000025632 00000 n
23 1
0000000024 00001 f
24 1
0000000000 00001 f
36 1
0000026900 00000 n
</span>
Когда объект освобождается, номер поколения объекта увеличивается, поэтому, если объект снова становится действительным (измените флаг с «f» на «n»), номер поколения остается действительным без его увеличения. Объект 23 имеет номер поколения 1, поэтому, если он снова станет действительным, номер поколения все равно будет 1, но если он будет снова удален, номер поколения увеличится до 2.
Объект 23 имеет номер поколения 1, поэтому, если он снова станет действительным, номер поколения все равно будет 1, но если он будет снова удален, номер поколения увеличится до 2.
В документе PDF, который был постепенно обновлен, обычно существует несколько подразделов, в противном случае должен появиться только один подраздел, начинающийся с нуля.
— Трейлер:Трейлер PDF определяет, как приложения, читающие документы PDF, должны находить списки перекрестных ссылок и другие специальные объекты. Все программы для чтения PDF должны начинать чтение PDF-файлов с конца файла. Вот пример трейлера:
<span>trailer
<<
/Size 22
/Root 2 0 R
/Info 1 0 R
>>
startxref
24212
%%EOF
</span>
Последняя строка документа PDF содержит конец строки файла «%% EOF». До конца файла отмечается строка со строкойstartxref, Используется для указания смещения от начала файла до таблицы перекрестных ссылок. В нашем примере таблица перекрестных ссылок начинается со смещения 24212 байт. До того, как это строкатрейлер, Который указывает начало части трейлера. Содержание части трейлера встроено в символы << и >> (это словарь, который принимает пары ключ-значение). Мы видим, что часть трейлера определяет несколько ключей, каждый из которых используется для определенного действия. В трейлере можно указать следующие ключи:
В нашем примере таблица перекрестных ссылок начинается со смещения 24212 байт. До того, как это строкатрейлер, Который указывает начало части трейлера. Содержание части трейлера встроено в символы << и >> (это словарь, который принимает пары ключ-значение). Мы видим, что часть трейлера определяет несколько ключей, каждый из которых используется для определенного действия. В трейлере можно указать следующие ключи:
— / Size[Целое число]: укажите количество записей в таблице перекрестных ссылок (также подсчитайте количество объектов в разделе обновления). Используемое число не должно быть косвенной ссылкой.
— / Prev [целое число]: укажите смещение от начала файла до предыдущей части перекрестной ссылки.Если имеется несколько частей перекрестной ссылки, используется смещение. Номер должен иметь перекрестные ссылки.
— / Root[Словарь]: Определяет ссылочный объект объекта каталога документов. Это специальный объект, который содержит различные указатели на другие специальные объекты различных типов (подробнее об этом позже).
— / Encrypt [словарь]: укажите словарь шифрования документа.
— / Info [Словарь]: указание ссылочного объекта информационного словаря документа.
— / ID [массив]: указать массив двухбайтовых незашифрованных строк символов, которые образуют идентификатор файла.
— / XrefStm [целое число]: указывает смещение от начала файла в декодированном потоке к потоку перекрестных ссылок. Это существует только в смешанных ссылочных файлах, если мы также хотим открыть документ, он будет указан, даже если приложение не поддерживает сжатые ссылочные потоки.
Мы должны помнить, что если мы обновим документ PDF позже, мы можем изменить исходную структуру. Обновления обычно добавляют другие элементы в конец файла.
Этические хакерские учебные ресурсы
3. Инкрементное обновление
Дизайн PDF допускает постепенные обновления, потому что мы можем прикрепить некоторые объекты к концу файла PDF, не переписывая весь файл. Поэтому изменения в документах PDF можно быстро сохранить. Новая структура документа PDF показана ниже:
Новая структура документа PDF показана ниже:
Мы видим, что документ PDF по-прежнему содержит оригинальное название, основной текст, таблицу перекрестных ссылок и трейлер. Кроме того, в PDF-документ добавлены другие детали кузова, перекрестных ссылок и трейлеров. Другие разделы с перекрестными ссылками будут содержать записи только для объектов, которые были изменены, заменены или удалены. Удаленный объект останется в файле, но будет помечен как «f». Каждый трейлинг должен заканчиваться тегом ‘%% EOF’ и должен содержать запись / Prev, указывающую на предыдущий раздел перекрестных ссылок.
В PDF версии 1.4 и выше мы можем указать в справочнике справочника документаVersionЗапись для переопределения версии по умолчанию в заголовке PDF.
4. Примеры
Давайте предоставим простой пример в формате PDF и проанализируем его. Давайте начнем сздесьЗагрузите образец PDF-документа и проанализируйте его. После открытия этого документа PDF он выглядит следующим образом:
Перекрестная ссылка и детали прицепа показаны на рисунке ниже:
Для ясности раздел перекрестных ссылок был уменьшен. Раздел перекрестных ссылок содержит подраздел, который сам содержит 223 объекта. Часть трейлера начинается со смещения байта 50291 и включает в себя 223 объекта, где корневой элемент указывает на объект 221, а элемент Info указывает на объект 222.
Раздел перекрестных ссылок содержит подраздел, который сам содержит 223 объекта. Часть трейлера начинается со смещения байта 50291 и включает в себя 223 объекта, где корневой элемент указывает на объект 221, а элемент Info указывает на объект 222.
В следующем разделе мы разберемся с основными типами данных структуры PDF.
5. Тип данных PDF
Документ PDF содержит восемь основных типов объектов, описанных ниже. Это типы объектов: логические значения, числа, строки, имена, массивы, словари, потоки и пустые объекты. Вы можете пометить объекты, чтобы другие объекты могли ссылаться на них. Помеченные объекты также называют косвенными объектами.
5.1. логический
Есть два ключевых слова:trueиfalseПредставляет логическое значение.
5.2. цифровой
В документах PDF есть два типа чисел: целые и действительные числа. Целые числа состоят из одной или нескольких цифр, которым может предшествовать знак плюс (символ «+») или знак минус (символ «-»). Примеры целочисленных объектов:
Примеры целочисленных объектов:
<span>123 +123 -123
</span>Реальные значения могут быть представлены одним или несколькими числами с необязательными символами и начальными, конечными или встроенными десятичными точками (точка-символ ‘.’). Ниже приведен пример действительного числа:
<span>123.0 -123.0 +123.0 123. -.123
</span>5.3. Имя
Имя в документе PDF представлено последовательностью символов ASCII в диапазоне 0x21-0x7E. Исключения:%, (,), <,>, [,], {,}, / и #, которые должны начинаться с косой черты. Альтернативным представлением символа является шестнадцатеричный эквивалент, которому предшествует символ «#». Существует ограничение на длину элемента name, который может быть только 127 байтов.
При написании имени вы должны использовать косую черту, чтобы ввести имя, косая черта — это не часть имени, а префикс, указывающий, что за именем следует последовательность символов. Если мы хотим использовать пробелы или любые другие специальные символы в качестве части имени, мы должны использовать 2 шестнадцатеричные обозначения для кодирования.
Если мы хотим использовать пробелы или любые другие специальные символы в качестве части имени, мы должны использовать 2 шестнадцатеричные обозначения для кодирования.
Пример имени можно увидеть в таблице ниже, которая взята из [1]:
5.4. строка
Строка символов в документе PDF представляется в виде последовательности байтов, заключенных в квадратные или угловые скобки, но максимальная длина составляет 65535 байтов. Любой символ может быть выражен в ASCII, или в восьмеричном или шестнадцатеричном. Восьмеричное представление требует, чтобы символы были записаны в формате \ ddd, где ddd — восьмеричное число. Шестнадцатеричное представление требует, чтобы символы были записаны в форме <dd>, где dd — шестнадцатеричное число.
Примеры строк, заключенных в круглые скобки:
<span>(mystring)
</span>Пример представления строки, заключенной в угловые скобки, показан ниже (шестнадцатеричное представление ниже такое же, как и выше, оно произносится как «mystring»):
<span><6d79737472696e67>
</span>Мы также можем использовать специальные известные символы при представлении строк: это: \ n для новой строки, \ r для возврата каретки, \ t для горизонтальной табуляции, \ b для клавиши возврата, \ f для изменения Разрыв страницы \, (левая скобка), \) означает правую скобку, \\ означает обратную косую черту.
5.5. массив
Массивы в документах PDF представляются в виде серии объектов PDF, которые могут быть разных типов и заключены в квадратные скобки. Вот почему массивы в документах PDF могут содержать объекты любого типа (например, числа, строки, словари и даже другие массивы). Массивы также могут иметь ноль элементов. Массив представляет квадратные скобки. Пример массива приведен ниже:
<span>123 123.0 true (mystring) /myname]
</span>5.6. словарь
Словарь в PDF-документе представлен в виде таблицы пар ключ / значение. Ключ должен быть объектом Name, а значением может быть любой объект, включая другой словарь. Максимальное количество записей в словаре составляет 4096 записей. Вы можете использовать двойные угловые скобки << и >> для отображения словаря. Пример словаря выглядит следующим образом:
<span><< /mykey1 123
/mykey2 0.123
/mykey3 << /mykey4 true
/mykey5 (mystring)
>>
>>
</span>5,7. поток
поток
Объекты потока представлены последовательностью байтов, а длина может быть бесконечной, поэтому изображения и другие большие блоки данных обычно представляются в виде потоков. Объекты потока представлены объектами словаря, за которыми следуют ключевые словаstream,Вслед за новой строкой иendstream。
Ниже приведен пример объекта потока:
<span><<
/Type /Page
/Length 23 0 R
/Filter /LZWDecode
>>
stream
…
endstream
</span>Все потоковые объекты должны быть косвенными объектами, а потоковые словари должны быть прямыми объектами. Словарь потока указывает точное количество байтов в потоке. Там должно быть разрывы строк иendstreamКлючевые слова.
Общие ключевые слова, используемые во всех потоковых словарях, следующие (обратите внимание, чтодлинаВступление обязательно):
-Длина: количество байтов в файле PDF используется для потоковой передачи данных. Если поток содержитFilterВступление, тоLengthКоличество байтов кодированных данных должно быть указано.
Если поток содержитFilterВступление, тоLengthКоличество байтов кодированных данных должно быть указано.
Тип: тип объекта PDF, описанный в словаре.
-Filter: имя фильтра, который будет применяться при обработке потоковых данных. Несколько фильтров могут быть указаны в порядке применения.
— DecodeParms:FilterуказанныйфильтрСловарь или словарный массив для использования. Это значение указывает параметры, которые необходимо передать в фильтр при применении фильтра. Если фильтр использует значение по умолчанию, вам не нужно этого делать.
-F: указать файл, содержащий потоковые данные.
-FFilter: имя фильтра, применяемого при обработке данных, найденных во внешнем файле потока.
-FDecodeParms: поFFilterСловарь или словарный массив, используемый указанным фильтром。
-DL: указать количество байтов в декодированном потоке. Вы можете использовать этот метод, если у вас достаточно места на диске для записи потока в файл.
-N: количество косвенных объектов, хранящихся в потоке.
-Первое: смещение в декодированном потоке первого сжатого объекта.
-Extends: указать ссылки на другие потоки объектов для формирования дерева наследования.
Данные потока в потоке объекта будут содержатьNДля целых чисел первое целое число представляет номер объекта, а второе целое число представляет смещение в декодированном потоке объекта. Объекты в потоке объектов являются непрерывными и не должны храниться в возрастающем порядке относительно номера объекта. вПрежде всегоОпределите первый объект потока объекта в словарной записи.
Мы не должны хранить следующую информацию в потоке объекта:
-Потоковый объект
-Объекты, номер поколения которых не равен нулю
-Документ шифрования словаря
-В словаре потока объектовLengthПредмет косвенного предмета
-Документ документов, линеаризованный словарь, объекты страницы
В PDF 1. 5 информация о перекрестных ссылках может храниться в потоке перекрестных ссылок, а не храниться в таблице перекрестных ссылок. Каждый поток перекрестных ссылок содержит информацию, эквивалентную таблице перекрестных ссылок и хвосту.
5 информация о перекрестных ссылках может храниться в потоке перекрестных ссылок, а не храниться в таблице перекрестных ссылок. Каждый поток перекрестных ссылок содержит информацию, эквивалентную таблице перекрестных ссылок и хвосту.
5,8. Пустой объект
нулевой объект по ключевому словуnullПредставление.
5.9. Косвенный объект
Прежде всего, мы должны знать, что любой объект в документе PDF может быть помечен как косвенный объект, он предоставляет уникальный идентификатор объекта для объекта, и другие объекты могут использовать его для ссылки на косвенный объект. Косвенные объекты — это ключевые словаobjиendobjПронумерованный объект представлен. endobj должен существовать в своей собственной строке, но obj должен появляться в конце строки идентификатора объекта, которая является первой строкой косвенного объекта. Строка идентификатора объекта состоит из номера объекта, номера поколения и ключевого слова «obj».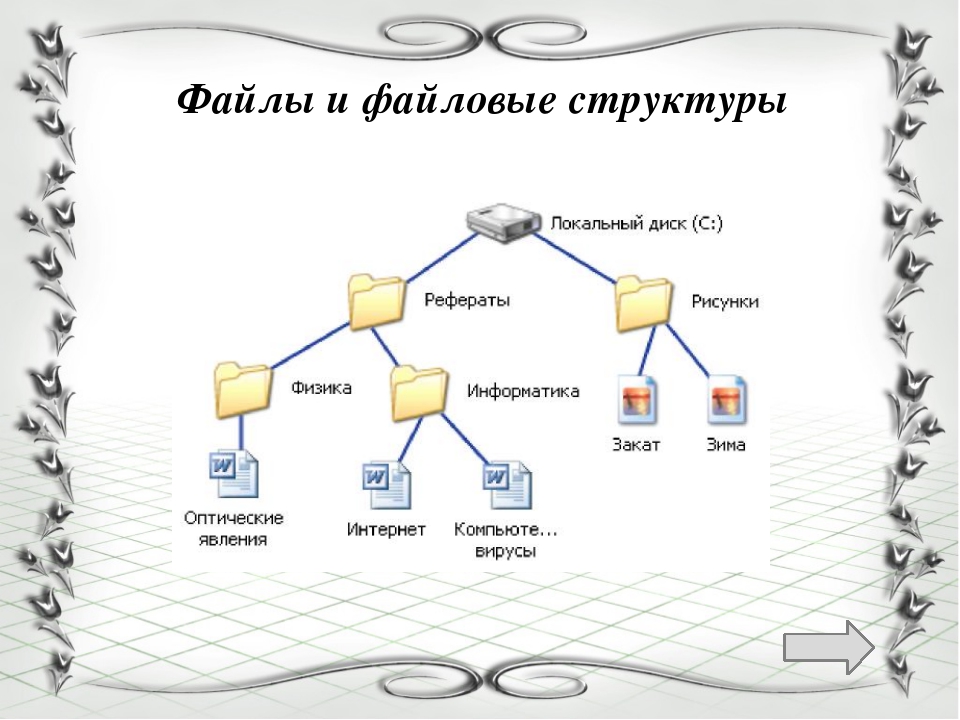 Примеры косвенных объектов:
Примеры косвенных объектов:
<span>2 1 obj
12345
endobj
</span>В приведенном выше примере мы создали новый косвенный объект, который сохранил 12345 объектов. Объявив объект как косвенный объект, мы можем использовать его в таблице перекрестных ссылок документа PDF и повторно использовать его на любой странице, в словаре и т. Д. В документе. Поскольку у каждого косвенного объекта есть собственная запись в таблице перекрестных ссылок, к косвенному объекту можно получить доступ очень быстро.
Идентификатор объекта косвенного объекта состоит из двух частей, первая часть — номер объекта текущего косвенного объекта. Косвенные объекты не должны быть последовательно пронумерованы в документе PDF. Вторая часть — это номер поколения, который устанавливается равным нулю для всех объектов во вновь созданном файле. Этот номер увеличивается позже, когда объект обновляется.
Мы можем сослаться на косвенный объект косвенной ссылки, который состоит из номера объекта, номера поколения и ключевого словаR состав, Чтобы сослаться на вышеупомянутый косвенный объект, мы должны написать следующее:
<span>2 1 R
</span>Если мы пытаемся ссылаться на неопределенный объект, мы фактически ссылаемся на нулевой объект.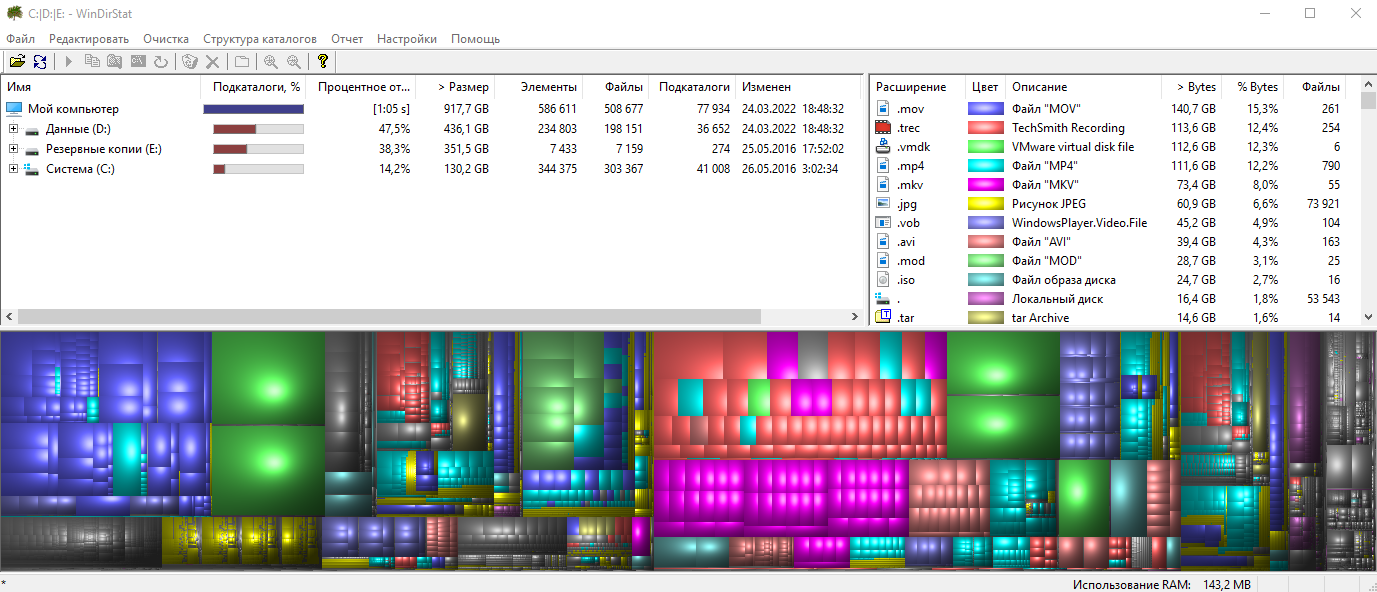
6. Файловая структура
Документ PDF состоит из объектов, содержащихся в основной части файла PDF. Большинство объектов в документах PDF являются словарями. Каждая страница документа представлена объектом страницы, который представляет собой словарь, содержащий ссылки на содержимое страницы. Объекты страницы соединяются вместе и образуют дерево страниц, используя косвенные объявления ссылок в каталоге документов.
Вся структура документа PDF может быть представлена следующей картинкой [1]:
На изображении выше мы видим, что каталог документов содержит ссылки на дерево страниц, иерархию структуры, потоки статей, именованные цели и интерактивные формы. Мы не будем вдаваться в подробности о каждой части, но представим только самую важную часть, а именно дерево страниц.
6.1. Файловый каталог
Из картинки выше, мы можем видетьКаталог документов
является корнем объекта в документе PDF. Мы уже сказали,TrailerВ разделе PDF/ RootЭлемент указывает каталог документа. Каталог документа содержит ссылки на другие объекты, которые определяют содержимое документа. Он также содержит информацию о том, как документ отображается на экране. Записи в каталоге документов следующие:
Каталог документа содержит ссылки на другие объекты, которые определяют содержимое документа. Он также содержит информацию о том, как документ отображается на экране. Записи в каталоге документов следующие:
— / Type: тип объекта PDF, который описывается в каталоге (в нашем примере этоCatalog,Потому что это объект каталога документов).
— / Версия: версия спецификации PDF, которая создает документ.
— / Расширения: информация о расширениях разработчика в этом документе.
— / Pages: косвенная ссылка на объект, являющийся корнем дерева страниц документа.
— / Dests: косвенная ссылка на объект, который является корнем названного целевого объекта.
— / Outline: косвенная ссылка на объект каталога схемы, который является корнем иерархии структуры документа.
— / Threads: косвенная ссылка на массив словаря потоков, представляющий поток статьи документа.
— / Метаданные: косвенная ссылка на поток метаданных, который содержит метаданные документа.
Мы видим, что многие другие элементы являются частью каталога документов, но они не будут здесь описаны. Читатели могут проверить [1] для деталей. Пример каталога документов выглядит следующим образом:
<span>1 0 obj
<< /Type /Catalog
/Pages 2 0 R
/PageMode /UseOutlines
/Outlines 3 0 R
>>
endobj
</span>6.2. Дерево страницы
Доступ к страницам документа осуществляется через дерево страниц, которое определяет все страницы в документе PDF. Дерево содержит узлы, представляющие страницы документа PDF, которые могут быть двух типов: промежуточные узлы и конечные узлы. Промежуточные узлы также называются узлами дерева страниц, а конечные узлы называются объектами страницы. Простейшая структура дерева страниц может состоять из одного узла дерева страниц, который напрямую ссылается на все объекты страницы (поэтому все объекты страницы являются листьями).
Каждый узел в дереве страниц должен иметь следующие записи:
— / Тип: тип объекта PDF, описанный этим объектом (в нашем случае этоPages, Потому что речь идет об узлах дерева страниц).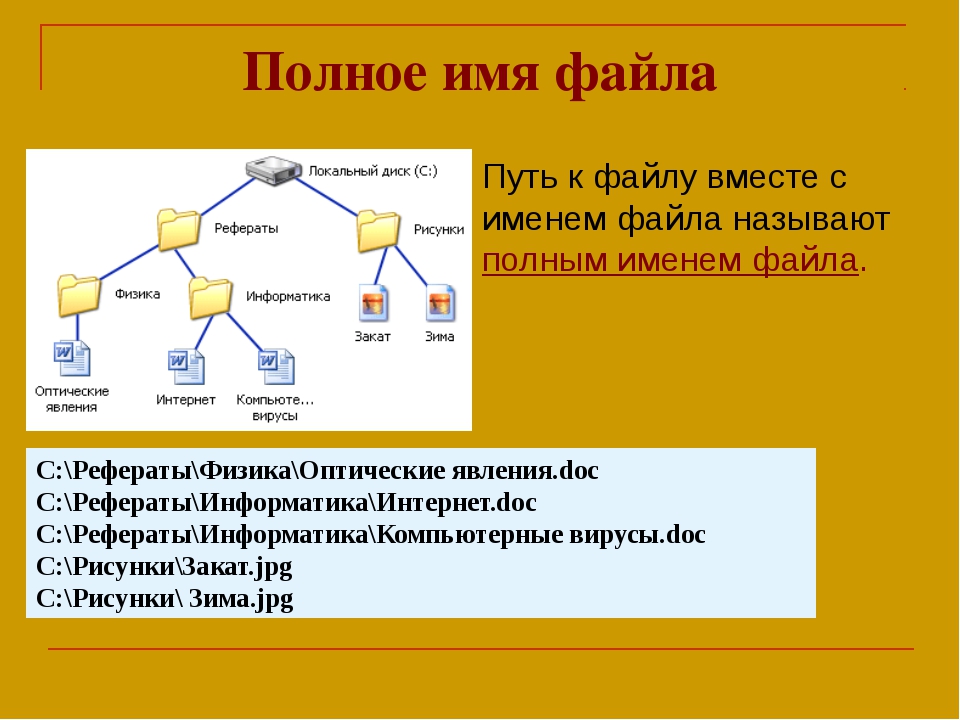
— / Parent: эта запись не должна появляться во всех узлах дерева страниц, кроме root. Эта запись указывает на своего родителя.
— / Kids: должен отображаться во всех узлах дерева страниц, кроме листьев, и указывать все дочерние элементы, к которым можно непосредственно получить доступ из текущего узла.
— / Count: укажите количество листовых узлов потомков этого узла в последующем дереве страниц.
Мы должны помнить, что дерево страниц не имеет ничего общего с чем-либо в документе PDF, таким как страницы или главы.
Базовый пример дерева страниц выглядит следующим образом [1]:
<span>2 0 obj
<< /Type /Pages
/Kids [ 4 0 R
10 0 R
24 0 R
]
/Count 3
>>
endobj
4 0 obj
<< /Type /Page
...
>>
endobj
10 0 obj
<< /Type /Page
...
>>
endobj
24 0 obj
<< /Type /Page
...
>>
endobj
</span>Дерево страницы выше определяет идентификатор 2RootОбъект, он имеет три дочерних узла, объекты 4, 10 и 20. Мы также можем видеть, что лист дерева страниц представляет собой словарь, который определяет атрибуты одной страницы документа. При определении их для каждой страницы документа мы можем использовать несколько атрибутов, все они указаны в [1].
Мы также можем видеть, что лист дерева страниц представляет собой словарь, который определяет атрибуты одной страницы документа. При определении их для каждой страницы документа мы можем использовать несколько атрибутов, все они указаны в [1].
Мы увидели базовую структуру PDF-документов и их типы данных. Если мы хотим начать поиск уязвимостей в программе чтения PDF-файлов, нам нужно изменить документ PDF, чтобы программа чтения PDF-файлов не могла его обработать и привести к сбою. Как правило, если мы можем аварийно завершить работу программы чтения PDF, мы обнаружим дыру в безопасности, которую мы можем использовать для выполнения произвольного кода на целевой машине.
7. Пример
В этой статье мы рассмотрим очень простой пример PDF-документа. Сначала нам нужно создать PDF-документ, а затем мы попытаемся проанализировать его. Чтобы создать PDF-документ, мы сначала создаем очень простой латексный .tex-документ, который содержит содержимое, показанное ниже:
Мы видим, что документов . tex не так много. Сначала мы определяем документ как статью, а затемначатьиконецДокумент содержит содержание статьи. Мы включим заголовок под названием «Введение «Новая его часть, которая содержит статический текст“Hello World!”, Мы можем использоватьpdflatexКоманда компилирует документ .tex в документ PDF и указывает имя файла .tex в качестве параметра. Созданный PDF выглядит так, как показано ниже:
tex не так много. Сначала мы определяем документ как статью, а затемначатьиконецДокумент содержит содержание статьи. Мы включим заголовок под названием «Введение «Новая его часть, которая содержит статический текст“Hello World!”, Мы можем использоватьpdflatexКоманда компилирует документ .tex в документ PDF и указывает имя файла .tex в качестве параметра. Созданный PDF выглядит так, как показано ниже:
Мы видим, что документ PDF не содержит много, только текст, который мы фактически включили, без картинок, JavaScript или других элементов.
8. Пример 1
Давайте посмотрим на структуру документа PDF, которая показана в следующем выводе:
<span>%PDF-1.5
%ÐÔÅØ
3 0 obj <<
/Length 138
/Filter /FlateDecode
>>
stream
...
endstream
endobj
10 0 obj <<
/Length2 1526
/Length3 7193
/Length4 0
/Length 8194
/Filter /FlateDecode
>>
stream
. ..
endstream
endobj
12 0 obj <<
/Length2 1509
/Length3 9410
/Length4 0
/Length 10422
/Filter /FlateDecode
>>
stream
...
endstream
endobj
15 0 obj <<
/Producer (pdfTeX-1.40.12)
/Creator (TeX)
/CreationDate (D:20121012175007+02'00')
/ModDate (D:20121012175007+02'00')
/Trapped /False
/PTEX.Fullbanner (This is pdfTeX, Version 3.1415926-2.3-1.40.12 (TeX Live 2011) kpathsea version 6.0.1)
>> endobj
6 0 obj <<
/Type /ObjStm
/N 10
/First 65
/Length 761
/Filter /FlateDecode
>>
stream
...
endstream
endobj
16 0 obj <<
/Type /XRef
/Index [0 17]
/Size 17
/W [1 2 1]
/Root 14 0 R
/Info 15 0 R
/ID [<1DC2E3E09458C9B4BEC8B67F56B57B63> <1DC2E3E09458C9B4BEC8B67F56B57B63>]
/Length 60
/Filter /FlateDecode
>>
stream
...
endstream
endobj
startxref
20215
%%EOF
</span>
..
endstream
endobj
12 0 obj <<
/Length2 1509
/Length3 9410
/Length4 0
/Length 10422
/Filter /FlateDecode
>>
stream
...
endstream
endobj
15 0 obj <<
/Producer (pdfTeX-1.40.12)
/Creator (TeX)
/CreationDate (D:20121012175007+02'00')
/ModDate (D:20121012175007+02'00')
/Trapped /False
/PTEX.Fullbanner (This is pdfTeX, Version 3.1415926-2.3-1.40.12 (TeX Live 2011) kpathsea version 6.0.1)
>> endobj
6 0 obj <<
/Type /ObjStm
/N 10
/First 65
/Length 761
/Filter /FlateDecode
>>
stream
...
endstream
endobj
16 0 obj <<
/Type /XRef
/Index [0 17]
/Size 17
/W [1 2 1]
/Root 14 0 R
/Info 15 0 R
/ID [<1DC2E3E09458C9B4BEC8B67F56B57B63> <1DC2E3E09458C9B4BEC8B67F56B57B63>]
/Length 60
/Filter /FlateDecode
>>
stream
...
endstream
endobj
startxref
20215
%%EOF
</span> ..
endstream
endobj
12 0 obj <<
/Length2 1509
/Length3 9410
/Length4 0
/Length 10422
/Filter /FlateDecode
>>
stream
...
endstream
endobj
15 0 obj <<
/Producer (pdfTeX-1.40.12)
/Creator (TeX)
/CreationDate (D:20121012175007+02'00')
/ModDate (D:20121012175007+02'00')
/Trapped /False
/PTEX.Fullbanner (This is pdfTeX, Version 3.1415926-2.3-1.40.12 (TeX Live 2011) kpathsea version 6.0.1)
>> endobj
6 0 obj <<
/Type /ObjStm
/N 10
/First 65
/Length 761
/Filter /FlateDecode
>>
stream
...
endstream
endobj
16 0 obj <<
/Type /XRef
/Index [0 17]
/Size 17
/W [1 2 1]
/Root 14 0 R
/Info 15 0 R
/ID [<1DC2E3E09458C9B4BEC8B67F56B57B63> <1DC2E3E09458C9B4BEC8B67F56B57B63>]
/Length 60
/Filter /FlateDecode
>>
stream
...
endstream
endobj
startxref
20215
%%EOF
</span>
..
endstream
endobj
12 0 obj <<
/Length2 1509
/Length3 9410
/Length4 0
/Length 10422
/Filter /FlateDecode
>>
stream
...
endstream
endobj
15 0 obj <<
/Producer (pdfTeX-1.40.12)
/Creator (TeX)
/CreationDate (D:20121012175007+02'00')
/ModDate (D:20121012175007+02'00')
/Trapped /False
/PTEX.Fullbanner (This is pdfTeX, Version 3.1415926-2.3-1.40.12 (TeX Live 2011) kpathsea version 6.0.1)
>> endobj
6 0 obj <<
/Type /ObjStm
/N 10
/First 65
/Length 761
/Filter /FlateDecode
>>
stream
...
endstream
endobj
16 0 obj <<
/Type /XRef
/Index [0 17]
/Size 17
/W [1 2 1]
/Root 14 0 R
/Info 15 0 R
/ID [<1DC2E3E09458C9B4BEC8B67F56B57B63> <1DC2E3E09458C9B4BEC8B67F56B57B63>]
/Length 60
/Filter /FlateDecode
>>
stream
...
endstream
endobj
startxref
20215
%%EOF
</span>Существует много необходимых элементов для создания такого простого PDF-документа, поэтому мы можем представить, как выглядит очень сложный PDF-документ. Нам также нужно помнить, что для ясности и краткости все потоки закодированных данных удаляются и заменяются тремя точками (см. Ниже: «…»).
Нам также нужно помнить, что для ясности и краткости все потоки закодированных данных удаляются и заменяются тремя точками (см. Ниже: «…»).
Давайте представим каждый раздел PDF. иззаголовокВы можете увидеть картинку ниже:
чтофюзеляжВы можете увидеть следующую картинку:
XrefЧасть можно увидеть на картинке ниже:
И, наконец,трейлерРазделы следующие:
Мы предоставляем все части документа PDF, но нам все еще нужно проанализировать их дальше. Название документа PDF стандартное, нам действительно не нужно об этом говорить, давайте оставим часть тела для будущего использования. Вот почему мы должны сначала взглянуть на внешний справочный раздел. Мы можем видеть, что смещение от начала файла до таблицы Xref составляет 20215 байт, а шестнадцатеричный формат — 0x4ef7. Если мы посмотримxxdШестнадцатеричное представление файла, который может получить инструмент, мы можем видеть содержимое, показанное на рисунке ниже:
Подсвеченный байт находится в начале 20125 байтов от начала файла. Предыдущий байт 0x0a — это новая строка, а текущий байт 0x31 представляет число 1, которое является началом таблицы Xref. Вот почему таблица внешних ссылок представлена косвенным объектом с идентификатором 16 и номером генерации 0 (это должно иметь место для всех объектов, поскольку мы только что создали документ PDF, а все объекты не были изменены; По всему документу PDF мы видим, что это, очевидно, правильно: все объекты имеют нулевой номер генерации).
Предыдущий байт 0x0a — это новая строка, а текущий байт 0x31 представляет число 1, которое является началом таблицы Xref. Вот почему таблица внешних ссылок представлена косвенным объектом с идентификатором 16 и номером генерации 0 (это должно иметь место для всех объектов, поскольку мы только что создали документ PDF, а все объекты не были изменены; По всему документу PDF мы видим, что это, очевидно, правильно: все объекты имеют нулевой номер генерации).
Косвенный объект/ TypeКлассифицируйте его как внешнюю справочную таблицу. из/ ИндексМассив содержит пару целых чисел для каждого подраздела в этом разделе. Первое целое число указывает номер первого объекта в подразделе, а второе целое число указывает количество записей в подразделе. В нашем примере номер объекта равен нулю, и в этом подразделе 17 записей. Это также вызвано/ SizeДиректива указана. Обратите внимание, что это число больше, чем наибольшее число любого номера объекта в подразделе. из/ WАтрибут задает целочисленный массив, представляющий размер полей в элементе перекрестной ссылки. [1 2 1] указывает, что поле состоит из одного байта, двух байтов и одного байта.
из/ WАтрибут задает целочисленный массив, представляющий размер полей в элементе перекрестной ссылки. [1 2 1] указывает, что поле состоит из одного байта, двух байтов и одного байта.
После этого/ RootЭлемент, который указывает каталог документа PDF как объект № 14./ InfoЭто информационный каталог документов PDF, включенных в объект № 15. /IDМассив необходим, потому чтошифрованиеЗапись существует и содержит две символьные строки, которые составляют идентификатор файла. Эти две строки используются в качестве входных данных для алгоритма шифрования. из/ ДлинаУкажите длину ключа битового шифрования, значение должно быть кратно 8 в диапазоне от 40 до 128 (значение по умолчанию — 40) В нашем примере длина ключа шифрования составляет 60 бит. что/ ФильтрУкажите имя обработчика безопасности для этого документа, это также обработчик безопасности для зашифрованных документов. В нашем примере этоFlateDecode, Он использует метод сжатия zlib / deflate для кодирования данных.
В нашем примере этоFlateDecode, Он использует метод сжатия zlib / deflate для кодирования данных.
Мы видим, что остальная часть таблицы Xref сжата, поэтому мы не можем ее прочитать. Конечно, мы можем применить некоторые алгоритмы распаковки zlib к сжатым данным, но есть и лучшие варианты. Если инструмент уже существует, зачем нам писать программу для него? Использоватьpdftk,Мы можем использовать следующую команду для восстановления поврежденной внешней справочной таблицы PDF:
<span># pdftk in.pdf output out.pdf
</span>После этого файл out.pdf содержит следующие внешние ссылки и трейлеры:
Очевидно, что номера объектов / Root и / Info также изменились, также изменился и другой контент, но мы получили определение таблицы Xref.трейлериXrefКлючевые слова. Мы можем видеть, что в таблице внешних ссылок есть 14 объектов.
Мы можем продолжать пытаться декодировать другие части, но я думаю, что это выходит за рамки этой статьи. Далее мы бы предпочли проверить незакодированные документы.
Далее мы бы предпочли проверить незакодированные документы.
9. Пример 2
Давайте взглянем на образец PDF-документа, с которым можно ознакомиться здесь:www.stluciadance.com/prospectus_file/sample.pdf, Некоторые объекты потока зашифрованы, но теперь они не так важны. Теперь, когда мы знаем, как обращаться с PDF-документами, мы не будем слишком много терять на простых вещах. Давайте откроем PDF в текстовом редакторе, таком как gvim, и просмотримTrailerРаздел. Теперь мы должны знать, что все документы в формате PDF должны читаться от начала до конца. Трейлер показан ниже:
Давайте также используем только несколько объектов для представления внешней ссылки (остальное отбрасывается для ясности):
Мы можем увидеть PDF документ/ RootВключенный в объект с идентификатором 221, объект 222 имеет дополнительную информацию. Объект 221 является наиболее важным объектом во всем документе, поэтому давайте представим его, это можно увидеть на рисунке ниже:
Мы можем видеть, что объект действительноКаталог документов, чтоДерево страницыОбъект 212,контурОбъект 213,ИмяОбъект 220 аOpenActionОбъекту 58. Мы не говорили ни о каких других типах объектов дерева страниц, поэтому будем продолжать говорить только о деревьях страниц.
Мы не говорили ни о каких других типах объектов дерева страниц, поэтому будем продолжать говорить только о деревьях страниц.
Объект дерева страниц с идентификатором 212 показан ниже:
Поэтому объект 212 содержит фактическую страницу документа PDF. Он содержит 10 страниц, что совершенно правильно (если мы откроем PDF-файл любым PDF-ридером и проверим количество страниц, мы можем это проверить). Мы знаемKidsАтрибут определяет все дочерние элементы, к которым можно получить прямой доступ из текущего узла. В нашем примере есть два прямых дочерних узла с идентификаторами объектов 66 и 135. Объект 66 выглядит следующим образом:
Объект 66 содержит другие дочерние элементы с идентификаторами 57, 69, 75, 97, 108 и 120.
Объект 135 также определяет объекты 129, 138, 133 и 158.
Если мы вычислим все элементы, мы увидим, что есть ровно 10 элементов, что означает 10 страниц из 10. Это также означает, что все представленные объекты фактически являются фактическими страницами документа PDF и не содержат никаких других дочерних узлов. Все представленные объекты являются похожими утверждениями, поэтому мы не будем рассматривать каждый объект по очереди. Вместо этого мы смотрим только на один объект, объект 57. Объект 57 содержит объявление следующим образом:
Все представленные объекты являются похожими утверждениями, поэтому мы не будем рассматривать каждый объект по очереди. Вместо этого мы смотрим только на один объект, объект 57. Объект 57 содержит объявление следующим образом:
Мы можем видеть, что тип объекта/ Page, Что прямо подразумевает, что это листовой узел, который отображает страницу документа PDF. Содержимое страницы PDF можно найти в объекте 62, объект показан ниже:
Мы можем видеть, что фактическое содержимое страницы PDF кодируется с помощью Flatecode, который является простым алгоритмом кодирования zlib.
10. Вывод
Мы видели два примера того, как создавать PDF документы. Обладая знаниями, которые мы получили, мы можем начать создавать неправильные документы PDF и предоставлять их различным читателям PDF. Если при чтении PDF-документа происходит сбой программы чтения PDF-файлов, документ содержит содержимое, с которым программа чтения PDF-файлов не может справиться, и вылетает. Это означает, что существует возможность появления лазеек, что требует дальнейших исследований.
Это означает, что существует возможность появления лазеек, что требует дальнейших исследований.
Наконец, если есть уязвимость, мы можем даже написать PDF-документ, содержащий вредоносный код, и выполнить вредоносный код, когда жертва открывает PDF-документ на целевом компьютере с помощью уязвимой программы чтения PDF. В этом случае вся машина может быть взломана, потому что любой вредоносный код может быть выполнен простым открытием вредоносного PDF-документа.
Перепечатано из:https://resources.infosecinstitute.com/pdf-file-format-basic-structure/
Сохранение или конвертация файлов в формат PDF или XPS в классической версии Project
Чтобы экспортировать или сохранить файл Office в формате PDF, откройте его и в меню Файл выберите пункт Экспорт или Сохранить как. Чтобы просмотреть пошаговые инструкции, выберите приложение Office в раскрывающемся списке.
-
Откройте таблицу или отчет, которые требуется опубликовать в формате PDF.
-
На вкладке Внешние данные в группе Экспорт нажмите кнопку PDF или XPS.
-
В поле Имя файла введите или выберите имя документа.
-
В списке Тип файла выберите PDF.
-
Если требуется высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. Нажмите кнопку ОК.
-
Нажмите кнопку Опубликовать.


Эти сведения также относятся к Microsoft Excel Starter 2010.
Примечание: Вы не можете сохранять листы Power View как PDF-файлы.
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы от видите диалоговое окно Сохранить как в Excel 2013 или Excel 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Открыть файл после публикации.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. Подробную информацию о диалоговом окне «Параметры» в Excel см. в статье Дополнительные сведения о вариантах создания PDF. По завершении нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.
OneNote 2013 и OneNote 2016
-
Откройте вкладку Файл.
-
Нажмите кнопку Экспорт.
-
В разделе Экспорт текущего элемента выберите часть записной книжки, которую необходимо сохранить в формате PDF.
-
В разделе Выбор формата выберите пункт PDF (*.pdf) и нажмите кнопку Экспорт.
-
В диалоговом окне Сохранить как в поле Имя файла введите название записной книжки.
-
Нажмите кнопку Сохранить.

OneNote 2010
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как и выберите параметр, соответствующий части записной книжки, которую необходимо сохранить в формате PDF.
-
В разделе Сохранить раздел как выберите пункт PDF и нажмите кнопку Сохранить как.
-
В поле Имя файла введите имя для записной книжки.
-
Нажмите кнопку Сохранить.
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы увидеть диалоговое окно Сохранить как в PowerPoint 2013 и PowerPoint 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Открыть файл после публикации.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. По завершении нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.
-
На вкладке Файл выберите команду Сохранить как.
Чтобы от видите диалоговое окно Сохранить как в Project 2013 или Project 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF-файлы (*.pdf) или XPS-файлы (*.xps) и нажмите кнопку Сохранить.
-
В диалоговом окне Параметры экспорта документа укажите в пункте Диапазон публикации, следует ли Включить непечатаемые данные или использовать Совместимость с ISO 19500-1 (только для PDF).
Советы по форматированию
Приложение Project не поддерживает все возможные функции форматирования документов PDF или XPS, но с помощью некоторых параметров печати вы можете изменять вид конечного документа.
На вкладке Файл выберите пункт Печать, а затем измените любой из следующих параметров:
В диалоговом окне Параметры страницы вы можете изменить параметры на таких вкладках:
-
«Поля»,
-
«Легенда»,
-
«Вид».
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы диалоговое окно Сохранить как в Publisher 2013 или Publisher 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если необходимо изменить способ оптимизации документа, выберите команду Изменить.
(Щелкните Параметры в Publisher 2013 или Publisher 2016).-
Внесите все необходимые изменения в разрешение изображения и непечатаемые сведения.
-
Чтобы изменить параметры печати документа, выберите Параметры печати.
-
По завершении нажмите кнопку ОК.
-
-
Если после сохранения файл требуется открыть в выбранном формате, установите флажок Открыть файл после публикации.
-
Нажмите кнопку Сохранить.
 (Щелкните Параметры в Publisher 2013 или Publisher 2016).
(Щелкните Параметры в Publisher 2013 или Publisher 2016).-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы от видите диалоговое окно Сохранить как в Visio 2013 или Visio 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Автоматический просмотр файла после сохранения.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. Нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.


Word 2013 и более новые
-
Выберите Файл > Экспорт > Создать PDF/XPS.
-
Если свойства документа Word содержат информацию, которую вы не хотите включать в PDF-файл, в окне Опубликовать как PDF или XPS нажмите кнопку Параметры. Затем выберите пункт Документ и снимите флажок Свойства документа. Задайте другие нужные параметры и нажмите кнопку ОК.
Дополнительные сведения о свойствах документа см. в разделе Просмотр или изменение свойств файла Office 2016.
-
В окне Опубликовать как PDF или XPS выберите место, где нужно сохранить файл. При необходимости измените имя файла.
-
Нажмите кнопку Опубликовать.

Дополнительные сведения о вариантах создания PDF
-
Чтобы преобразовать в формат PDF только некоторые страницы, укажите их в полях Страницы.
-
Чтобы включить исправления в PDF, в разделе Опубликовать установите переключатель в положение Документ с исправлениями. В противном случае убедитесь установите переключатель в положение Документ.
-
Чтобы создать набор закладок в PDF-файле, установите флажок Создать закладки, используя. Затем установите переключатель Заголовки или, если вы добавили закладки в свой документ, Закладки Word.
-
Если вы хотите включить в PDF-файл свойства документа, убедитесь в том, что флажок Свойства документа установлен.
-
Чтобы сделать документ удобней для чтения в программах чтения с экрана, установите флажок Теги структуры документа для улучшения восприятия.
-
Совместимость с ISO 19005-1 (PDF/A). Этот параметр предписывает создать PDF-документ, используя стандарт архивации 1.7 PDF. Стандарт PDF/A позволяет гарантировать, что при открытии на другом компьютере документ будет выглядеть точно так же.
-
Преобразовать текст в точечный рисунок, если невозможно внедрить шрифты. Если невозможно внедрить шрифты в документ, при создании PDF-файла используется точечный рисунок текста, чтобы PDF-документ выглядел так же, как оригинальный. Если этот параметр не выбран и в файле используется невстраиваемый шрифт, программа чтения PDF-файлов может применить другой шрифт.
-
Зашифровать документ с помощью пароля.
Выберите этот параметр, чтобы ограничить доступ к PDF-файлу людям, у которых нет пароля. Когда вы нажмете кнопку ОК, Word откроет диалоговое окно Шифрование документа в формате PDF, в котором вы можете ввести пароль и его подтверждение.

 Выберите этот параметр, чтобы ограничить доступ к PDF-файлу людям, у которых нет пароля. Когда вы нажмете кнопку ОК, Word откроет диалоговое окно Шифрование документа в формате PDF, в котором вы можете ввести пароль и его подтверждение.
Выберите этот параметр, чтобы ограничить доступ к PDF-файлу людям, у которых нет пароля. Когда вы нажмете кнопку ОК, Word откроет диалоговое окно Шифрование документа в формате PDF, в котором вы можете ввести пароль и его подтверждение.Открытие PDF-файла в Word и копирование содержимого из него
Вы можете скопировать из PDF-документа нужное содержимое, открыв его в Word.
Выберите Файл > Открыть и найдите PDF-файл. Word откроет PDF в новом файле. Вы можете скопировать нужное содержимое, включая изображения и схемы.
Word 2010
Эти сведения также относятся к Microsoft Word Starter 2010.
-
Откройте вкладку Файл.
-
Выберите команду Сохранить как.
Чтобы увидеть диалоговое окно Сохранить как в Word 2013 и Word 2016, необходимо выбрать расположение и папку. -
В поле Имя файла введите имя файла, если оно еще не присвоено.
-
В списке Тип файла выберите PDF.
-
Если файл требуется открыть в выбранном формате после его сохранения, установите флажок Открыть файл после публикации.
-
Если необходимо высокое качество печати документа, установите переключатель в положение Стандартная (публикация в Интернете и печать).
-
Если качество печати не так важно, как размер файла, установите переключатель в положение Минимальный размер (публикация в Интернете).
-
-
Нажмите кнопку Параметры, чтобы выбрать страницы для печати, указать, должна ли печататься разметка, а также выбрать параметры вывода. По завершении нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.


Чтобы сохранить файл в формате PDF в Office для Mac, выполните эти простые действия:
-
Откройте вкладку Файл.
-
Нажмите кнопку Сохранить как.
-
Щелкните Формат файла в нижней части окна.
-
Выберите PDF в списке доступных форматов.
-
Присвойте файлу имя, если оно еще не указано, а затем нажмите кнопку Экспорт.

С помощью Word, PowerPoint и OneNote в Интернете можно преобразовать документ в формат PDF.
-
Выберите файл > печать >печать (в PowerPoint выберите один из трех форматов).
-
В меню в области Принтер выберитесохранить в формате PDF, а затем — Сохранить.
-
Затем в открываемом меню проводника можно назвать PDF-файл, выбрать, где его сохранить, а затем выбрать сохранить.

При этом приложение создаст обычный PDF-файл, в котором будут сохранены макет и форматирование исходного документа.
Если вам нужны дополнительные возможности для управления PDF-файлом, например добавление закладок, преобразуйте документ в ФОРМАТ PDF с помощью настольного приложения. Нажмите кнопку Открыть в настольном приложении на панели инструментов PowerPoint и OneNote, чтобы начать работу с классическим приложением, а затем в Word сначала выберите в word dropdown Editing (Редактирование), а затем выберите открыть в настольном приложении.
Если у вас нет настольного приложения, вы можете попробовать или купить последнюю версию Office сейчас.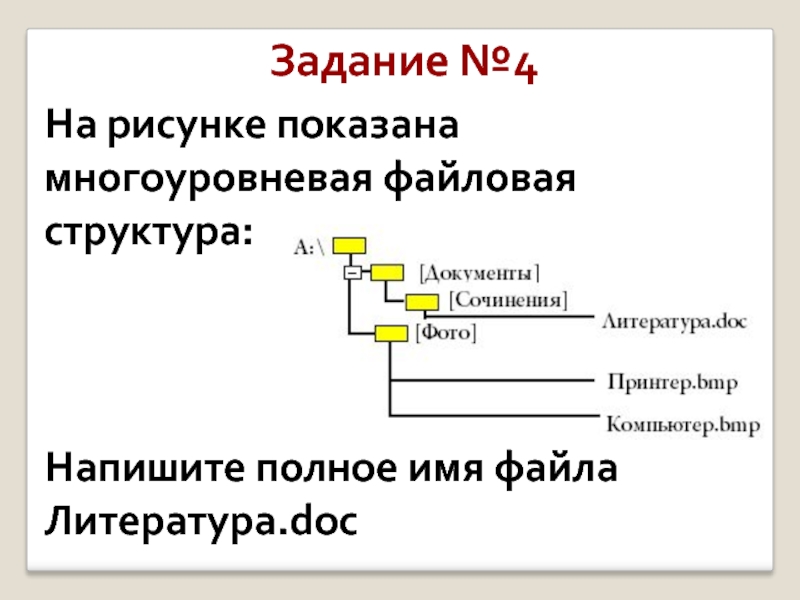
У вас есть предложения для этой возможности?
Голосуйте за понравившиеся идеи или предлагайте свои в копилке идей на сайте word.uservoice.com.
Чтобы экспортировать документ Word или книгу Excel в файл формата PDF на устройстве с iOS, нажмите в левом верхнем углу кнопку Файл и выберите пункт Экспорт, а затем — PDF.
Создание удобочитаемых PDF-документов
Office 365, Office 2019, Office 2016
-
Перед созданием PDF-файла запустите проверку доступности, чтобы убедиться, что документ легко найти и отредактировать всем людям.
-
Выберите команду Файл > Сохранить как и укажите папку для сохранения документа.
-
В диалоговом окне Сохранить как в раскрывающемся списке Тип файла выберите пункт PDF.
-
Откройте меню Параметры, убедитесь, что установлен флажок Теги структуры документа для улучшения восприятия, и нажмите кнопку ОК.
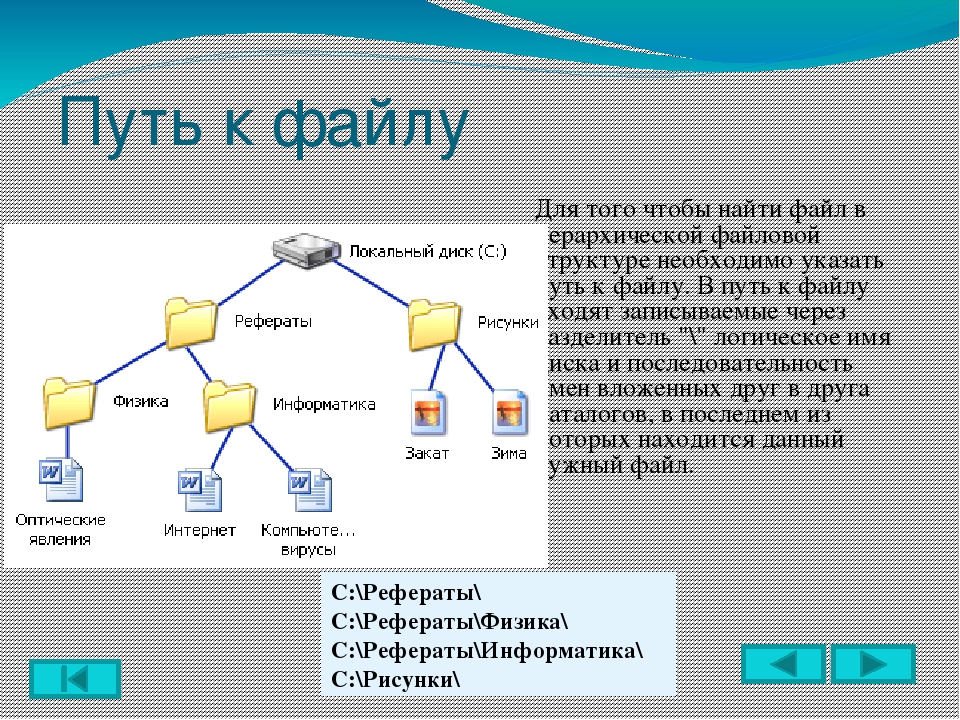
К началу страницы
Office 2013
-
Перед созданием PDF-файла запустите проверку доступности, чтобы убедиться, что документ легко найти и отредактировать всем людям.
-
Откройте вкладку Файл и выберите команду Сохранить как.
-
В разделе Выбор местоположения выберите место, куда необходимо сохранить файл.
-
В разделе Выберите папку выберите используемую папку или нажмите кнопку Обзор дополнительных папок, чтобы выбрать другую папку.
-
В диалоговом окне Сохранить как щелкните стрелку в списке Тип файла, а затем выберите пункт PDF.
-
Нажмите кнопку Параметры.
-
Установите флажок Теги структуры документа для улучшения восприятия и нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.


К началу страницы
Office 2010
-
Перед созданием PDF-файла запустите проверку доступности, чтобы убедиться, что документ легко найти и отредактировать всем людям.
-
Откройте вкладку Файл и выберите команду Сохранить как.
-
В диалоговом окне Сохранить как щелкните стрелку в списке Тип файла, а затем выберите пункт PDF.
-
Нажмите кнопку Параметры.
-
Установите флажок Теги структуры документа для улучшения восприятия и нажмите кнопку ОК.
-
Нажмите кнопку Сохранить.

К началу страницы
Проверьте соответствие и подтвердите свои документы PDF/A
PDF / A лучше, чем PDF для архивирования
Основная цель PDF-файла, поэтому он так популярен, — это открывать и просматривать на всех системах и устройствах, сохраняя при этом макет. С 1995 года миллионы (миллиарды?) Пользователей создают и конвертируют свои файлы в формат PDF, чтобы архивировать их в электронном виде. Однако в 2005 году новый нестандартный PDF-файл, специально разработанный для долгосрочное архивирование был выпущен. Так почему же для этого не хватило PDF?Если «обычный» PDF-файл идеально подходит для повседневного использования, его спецификация допускает действия, которые могут затруднить просмотр в будущем и предотвратить безупречное архивирование файлов.
 Например, блокировка документа паролем противоречит идее доступа к файлам. Другой проблемой является использование динамического контента, такого как запуск, звук и фильмы, поскольку они требуют использования сторонних приложений, которые могут быть недоступны в будущем. В отличие от PDF, PDF / A требует, чтобы вся информация, необходимая для обеспечения точной визуализации документа, содержалась в файле, включая шрифты, цветовые профили, изображения и многое другое.
Например, блокировка документа паролем противоречит идее доступа к файлам. Другой проблемой является использование динамического контента, такого как запуск, звук и фильмы, поскольку они требуют использования сторонних приложений, которые могут быть недоступны в будущем. В отличие от PDF, PDF / A требует, чтобы вся информация, необходимая для обеспечения точной визуализации документа, содержалась в файле, включая шрифты, цветовые профили, изображения и многое другое.Существуют разные версии PDF / A, основанные на разных версиях PDF.
PDF / A-1 стандартизирован в соответствии с ISO 19005-1: 2005. На основе версии 1.4 спецификации PDF в нем отсутствуют важные функции, такие как поддержка JPEG2000, прозрачность, слои и вложения.
Следующая версия, PDF / A-2 (ISO 19005-2: 2011), основана на PDF 1.7 и включает то, что раньше отсутствовало в PDF / A-1. Дополнительной важной функцией является встраивание файлов PDF / A для облегчения архивирования наборов документов в один файл.
PDF / A-3 (ISO 19005-3: 2012) также основан на PDF 1. 7. Основное отличие состоит в том, что он позволяет встраивать файлы произвольных форматов (например, XML, CSV, CAD, текстовые документы, электронные таблицы и другие) в документы PDF / A.
7. Основное отличие состоит в том, что он позволяет встраивать файлы произвольных форматов (например, XML, CSV, CAD, текстовые документы, электронные таблицы и другие) в документы PDF / A.
Наконец, в 2020 году был выпущен PDF / A-4 (ISO 19005-4: 2020), чтобы соответствовать глобальным улучшениям, внесенным в PDF 2.0.
И есть много разных уровней PDF / A
Помимо версий, спецификация PDF / A включает несколько уровней, каждый для разных целей.
Уровень a (с «доступным») находится в PDF / A-1, PDF / A-2 и PDF / A-3. Он направлен на повышение доступности файла благодаря логической структуре документа и необходимым тегам и информации, которые помогут пользователям со вспомогательными технологиями.
Уровень b (где b означает «базовый») можно найти в PDF / A-1, PDF / A-2 и PDF / A-3. Он включает только необходимые функции, необходимые для надежного воспроизведения внешнего вида документа.
Уровень u (где u означает «Unicode») находится в PDF / A-2 и PDF / A-3. Он требует, чтобы весь текст в документе имел отображение Unicode.
С выпуском PDF / A-4, основанного на спецификации PDF 2.0, новый уровень f заменяет уровни a, b и u. Кроме того, PDF / A-4f позволяет встраивать файлы любого формата.
Уровень e также является новым и специфичным для PDF / A-4. Он заменяет менее известный и используемый PDF / E-1 (ISO 24517-1: 2008, формат технических документов с использованием стандарта PDF) на основе PDF 1.6. Кроме того, PDF / A-4e включает аннотации RichMedia для 3D-контента в формате U3D или PRC и встроенных файлов.
Подборка быстрых решений по работе с документами PDF на все случаи жизни
За два с лишним десятка лет своего существования межплатформенный формат файлов PDF из никому не известного пионера превратился в видного партийного деятеля электронного документооборота. Почему? PDF всеобъемлющ! В него можно впихнуть и текст, и векторную/растровую графику, и мультимедийный контент, и интерактивные ссылки, и сценарии JavaScript, и объекты 3D-моделирования.
Пускай большинство из нас и не использует всю мощь PDF на полную катушку, но иметь дело с этим универсальным форматом файлов периодически приходится всем. Посему предлагаю вам ознакомиться и сохранить про запас шпаргалку с быстрыми рецептами по работе с PDF на любом устройстве, имеющем доступ в Сеть.
Посему предлагаю вам ознакомиться и сохранить про запас шпаргалку с быстрыми рецептами по работе с PDF на любом устройстве, имеющем доступ в Сеть.
Как создать PDF без Adobe Acrobat
Компания Adobe уже много лет развивает специализированную программу для создания PDF-файлов Adobe Acrobat. Это крайне функциональное решение распространяется за немалые деньги и занимает на винчестере порядочное пространство. Если у вас нет нужды создавать PDF-файлы умопомрачительной сложности и вы нацелены на обычный документооборот, лучше познакомиться с более простыми средствами.
Например, браузер Chrome умеет генерировать PDF-файлы из любой открытой вами веб-страницы. Для этого необходимо лишь выбрать в меню браузера «Печать» (или нажать комбинацию клавиш Ctrl + P). В открывшемся окне обратиться к подменю «Принтер» и щёлкнуть по варианту «Сохранить как PDF». Вам будет предложено задать ориентацию страницы, размер полей и отменить сохранение колонтитулов.
Окно сохранения файла в формате PDF в ChromeНапомню, что веб-обозреватель от Google умеет открывать разнообразные типы файлов. Например, графические изображения. Тем самым вы можете закинуть картинку в Chrome и быстро сохранить её как PDF для секретаря успешной организации, не принимающей никаких других типов файлов.
Например, графические изображения. Тем самым вы можете закинуть картинку в Chrome и быстро сохранить её как PDF для секретаря успешной организации, не принимающей никаких других типов файлов.
Возможно, вы не замечали, но Google Docs, равно как и его конкурент — пакет офисных утилит Microsoft Office, умеет сохранять результаты вашей работы напрямую в PDF.
Окно сохранения файла в формате PDF в Google DocsПользователям других популярных браузеров могу посоветовать поискать расширения, заточенные под сохранение PDF-файлов. Например, любителям Firefox стоит обратить внимание на дополнение Save as PDF. По аналогии с Chrome оно позволяет сохранять PDF-файлы на основе отрытого сайта за пару кликов мышью.
Почитатели Windows-среды наверняка слышали о так называемых виртуальных принтерах — специальных утилитах, обеспечивающих создание PDF-файлов из любых установленных в системе программ. К примеру, BullZip PDF Printer распространяется на бесплатной основе и может похвастаться неплохим функционалом.
Как быстро создать PDF на мобильном
Многие офисные пакеты для мобильной платформы Android имеют встроенный инструмент сохранения файлов в формате PDF. К примеру, широко известный Kingsoft Office с лёгкостью справляется с этой задачей.
Окно сохранения файла в формате PDF в Kingsoft OfficeЕсли у вас не установлен офисный пакет, а его скачивание затруднительно, на помощь придёт веб-сервис pdfconvert.me. Веб-инструмент умеет перегонять текст сообщения, ссылки на интернет-страницы и прилагаемые файлы в формат PDF. Для этого отправьте сообщение на адрес [email protected], напишите текст, укажите ссылку или прикрепите документ Word, Excel или PowerPoint, а сервис через некоторое время отправит вам ответное сообщение, содержащее переработанный PDF-файл.
Как конвертировать PDF в другой формат
Если вам приспичило сделать из PDF-файла текстовый документ, проще всего воспользоваться услугами Zamzar. Этот мощный онлайн-конвертёр форматов файлов умеет в том числе и сохранять PDF в TXT или DOC. Закиньте свой файл PDF через веб-интерфейс на сервер сервиса и получите ссылку на результат по электронной почте.
Закиньте свой файл PDF через веб-интерфейс на сервер сервиса и получите ссылку на результат по электронной почте.
Как перевести PDF с незнакомого языка
Получили контракт на зулусском? Не беда! Google Translate сумеет переварить для вас столь далёкий от понимания язык. И да, нет нужды перепечатывать текст из присланного PDF-документа: вы можете загрузить файл напрямую и в результате получить готовый перевод.
Как вычленить текст из отсканированного PDF онлайн
Огромное количество офисных тружеников искренне мучаются вопросом: почему в одних PDF-файлах можно выделить текст, а в других — нет? Оставлю вопрос без прямого ответа, лишь укажу на малоизвестную функцию Google Drive.
Перейдите на свой облачный диск, кликните по шестерёнке настроек, выберите пункт «Настройки загрузки» и обратите внимание на второю опцию.
Активируем OCR-движок от GoogleЗа преобразование текста из PDF-файлов и изображений отвечает собственный OCR-движок от Корпорации добра. Этой настройке подвластны все непослушные PDF-документы.
Как объединить несколько PDF-файлов
На просторах Сети можно отыскать множество сервисов, позволяющих скрепить несколько PDF-файлов в один. Но мне нравится PDF Joiner. Чем? Предпросмотром загруженных файлов и возможностью их перетасовывания в свободном порядке.
Объединение нескольких PDF-файлов в PDF JoinerПричём сделано всё в простой и наглядной форме. С помощью веб-инструмента вам будет легко скрепить до 20 документов, относящихся к одному договору, например.
Как снять ограничения с PDF-файла
Систему ограничений PDF от копирования текста, внесения изменений и распечатки на самом деле очень просто обойти. Интернет кишит узконаправленными сервисами, снимающими такие запреты с PDF-документов. Например, посоветую PDFUnlock. Веб-инструмент убирает ограничения с PDF, расположенных как на вашем компьютере, так и в популярных облачных хранилищах Dropbox и Google Drive.
Как снять защиту с PDF-файла
Более сложная ситуация возникает в том случае, если создатель PDF-файла поставил пароль на открытие файла. Такая защита шифруется, и для её обхода необходимо устанавливать специальные программы. Беда в том, что при должной сложности пароля процесс его подбора (а именно так и устроен механизм разблокировки) может занять огромное количество времени. Вполне может случиться, что овчинка не будет стоить выделки. Но если вы полны уверенности в своих силах (уверены, что пароль использует только цифры или состоит из трёх-четырёх символов, например), попробуйте Appnimi PDF Unlocker.
Такая защита шифруется, и для её обхода необходимо устанавливать специальные программы. Беда в том, что при должной сложности пароля процесс его подбора (а именно так и устроен механизм разблокировки) может занять огромное количество времени. Вполне может случиться, что овчинка не будет стоить выделки. Но если вы полны уверенности в своих силах (уверены, что пароль использует только цифры или состоит из трёх-четырёх символов, например), попробуйте Appnimi PDF Unlocker.
Как заполнить PDF-форму онлайн
Если вам необходимо заполнить заявление, декларацию или отчёт, предоставленные в PDF-форме, без раздумий отправляйтесь за помощью к PDFfiller.
Дружелюбный интерфейс PDFfiller удобен для заполнения PDF-формВеб-сервис преобразует ваш файл в картинку, позволяет напечатать поверх неё текст, а затем выдаёт результат объединения двух слоёв.
Как добавить к PDF рукописную подпись и своё фото
Ваш партнёр требует заверения присланной документации подписью, выполненной от руки? FillanyPDF удовлетворит его желание при минимуме ваших усилий.
Плюс к этому, веб-инструмент позволяет встроить в документ любое фото, например ваше селфи.
Как вычленить отдельные страницы из PDF
Если ваш потенциальный клиент не желает видеть весь многотомник коммерческого предложения, отправьте ему лишь конкретные листы. Для этих целей идеальным вариантом выглядит PDF Split!. Достаточно указать диапазон(ы) вырезаемых страниц, а веб-сервис сохранит указанные страницы в отдельные файлы или объединит их в меньшую, по сравнению с оригиналом, выжимку.
Как защитить PDF паролем
Хотите быть уверенными, что PDF не прочтёт постороннее лицо? Защитите документ паролем на PDF Protect!.
PDF Protect! содержит ряд полезных настроекВеб-сервис предлагает выбрать тип шифрования, задать пароль на открытие файла, ограничить доступ к некоторым функциям PDF.
В этой статье я делал упор именно на сетевые ресурсы, облегчающие те или иные манипуляции с PDF-документами. У каждого предложенного сервиса есть онлайн-конкуренты. Если вы знаете хорошие альтернативы, напишите их в комментариях.
У каждого предложенного сервиса есть онлайн-конкуренты. Если вы знаете хорошие альтернативы, напишите их в комментариях.
4. Структура документа — объяснение в формате PDF [Книга]
Глава 4. Структура документа
В этой главе мы оставляем биты и байты файла PDF, и рассмотрим логическую структуру. Рассматриваем прицеп словарь , каталог документов и дерево страниц . Перенумеруем необходимые записи в каждом объект. Затем мы рассмотрим две общие структуры в файлах PDF: текст строки и даты .
На рисунке 4-1 показана логическая структура. типового документа.
Рисунок 4-1. Типичная структура документа для двухстраничного PDF-документа
Этот словарь, находящийся в трейлере файла, а не в главном
тело файла, это одна из первых вещей, которые обрабатываются, когда
программа хочет прочитать документ PDF. Он содержит записи, позволяющие
таблица перекрестных ссылок — и, следовательно, объекты файла — для чтения. Его
важные записи сведены в Таблицу 4-1.
Его
важные записи сведены в Таблицу 4-1.
Таблица 4-1. Записи в словаре прицепа (* обозначает обязательную запись)
| Ключ | Тип значения | Значение |
/ Размер * | Целое число | Общее количество записей в таблица перекрестных ссылок файла (обычно равно количеству объектов в файле плюс один). |
/ Корень * | Косвенная ссылка на словарь | Каталог документов . |
/ информация | Косвенная ссылка на словарь | Информация о документе словарь . |
/ ID | Массив из двух строк | Однозначно определяет файл в рабочем потоке. Первое
строка определяется, когда файл создается впервые, второй
изменяются системами рабочего процесса при изменении файла. |
Вот пример словаря для трейлеров:
<< / Размер 421 / Корень 377 0 R / Инфо 375 0 R / ID [<75ff22189ceac848dfa2afec93deee03> <057928614d9711db835e000d937095a2>] >>
После обработки словаря трейлера мы можем продолжить чтение информационный словарь документа и каталог документов .
Словарь информации о документе
Словарь информации о документе содержит даты создания и изменения файла, а также некоторые простые метаданные (не путать с более полными метаданными XMP обсуждается в метаданных XML).
Записи словаря информации о документе описаны в Табл. 4-2. Типичный информационный словарь документа приведено в Примере 4-1.
Таблица 4-2. Записи в информационном словаре документа. Типы «текст строка »и« строка даты »объясняются далее в этой главе.
| Клавиша | Тип значения | Значение |
/ название | текстовая строка | Название документа. Обратите внимание, что это не имеет отношения к
любой заголовок, отображаемый на первой странице. Обратите внимание, что это не имеет отношения к
любой заголовок, отображаемый на первой странице. |
/ Тема | текстовая строка | Тема документа. Опять же, это просто метаданные без каких-либо особых правил о содержании. |
/ Ключевые слова | текстовая строка | Ключевые слова, связанные с этим документом. Никаких советов не дается как их структурировать. |
/ Автор | текстовая строка | Имя автора документа. |
/ Дата создания | строка даты | Дата создания документа. |
/ Дата модификации | строка даты | Дата последнего изменения документа. |
/ Создатель | текстовая строка | Имя программы, которая изначально создала этот
документ, если он запускался в другом формате (например,
«Microsoft Word»).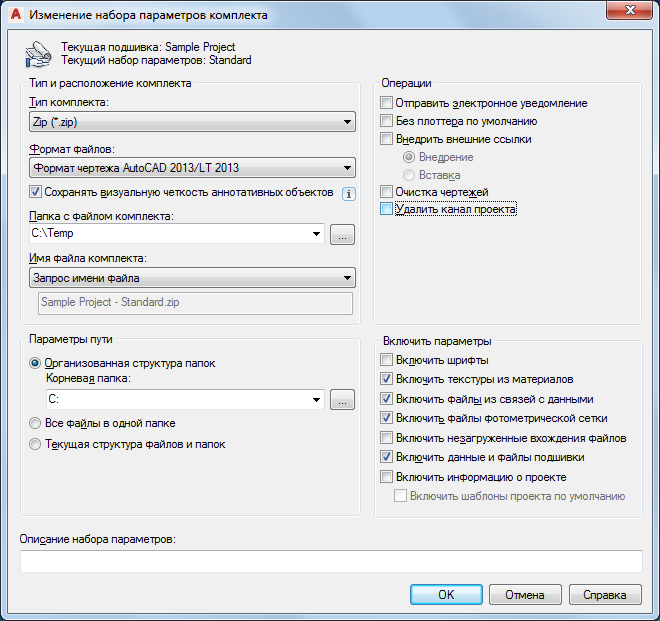 |
/ Производитель | текстовая строка | Название программы, которая преобразовала этот файл в PDF, если он начинался как другой формат (например, формат слова процессор). |
Пример 4-1. Типовой информационный словарь документа
<< / ModDate (D: 20060926213913 + 02'00 ') / CreationDate (D: 20060926213913 + 02'00 ') / Заголовок (catalogueproduit-UK.qxd) / Creator (QuarkXPress: фильтр pictwpstops 1.0) / Производитель (Acrobat Distiller 6.0 для Macintosh) / Автор (Джеймс Смит) >>
Формат строки строки даты (для / CreationDate и / ModDate ) обсуждается в разделе Даты. Текстовая строка в формате (который
описывает, как различные кодировки могут использоваться в строковом типе)
описано в текстовых строках.
Каталог документов является корневым объектом
основной граф объектов, из которого все остальные объекты могут быть достигнуты через
косвенные ссылки. В Таблице 4-3 мы перечисляем
каталог документов, словарные статьи, которые необходимы, и некоторые из
много дополнительных, чтобы представить краткие темы PDF, которые мы не охватываем
в другом месте на этих страницах.
В Таблице 4-3 мы перечисляем
каталог документов, словарные статьи, которые необходимы, и некоторые из
много дополнительных, чтобы представить краткие темы PDF, которые мы не охватываем
в другом месте на этих страницах.
Таблица 4-3. Каталог документов (* обозначает обязательную запись)
| Ключ | Тип значения | Значение |
/ Тип * | имя | Должно быть / Каталог . |
/ Страницы * | косвенная ссылка на словарь | Корневой узел дерева страниц. Деревья страниц обсуждаются в Страницы и деревья страниц. |
/ PageLabels | дерево номеров | Дерево номеров, дающее метки страниц для этого документа.
Этот механизм позволяет страницам документа иметь больше
сложная нумерация, чем просто 1,2,3….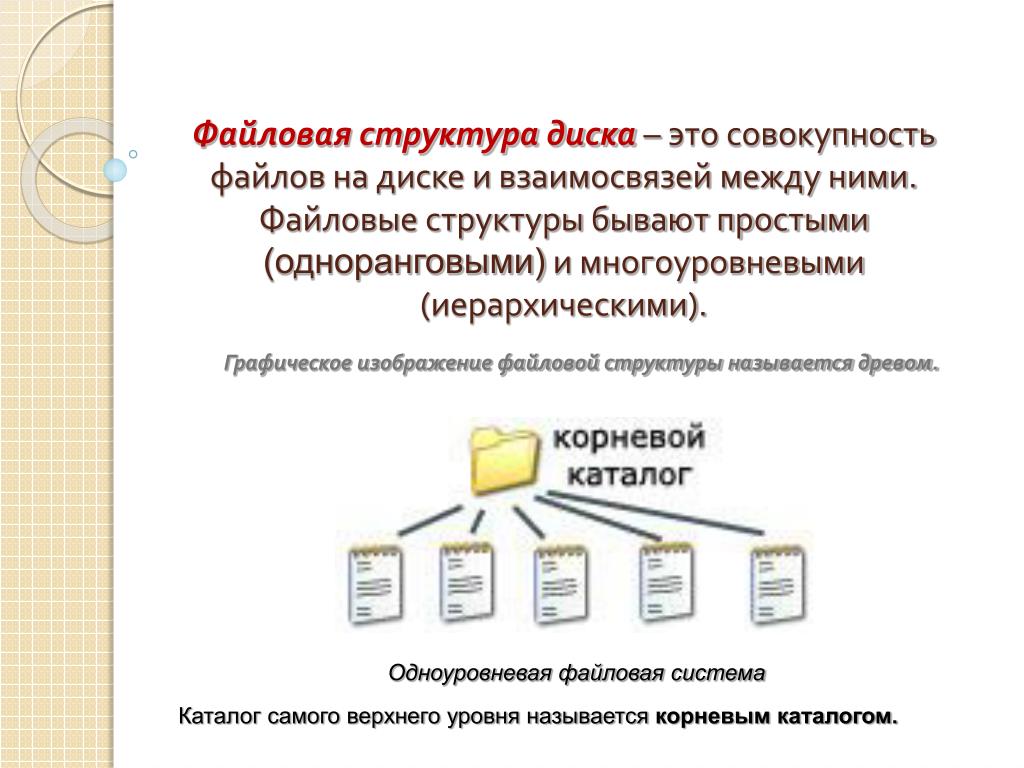 Например, предисловие
книги могут быть пронумерованы i, ii, iii …, в то время как основное содержание
начинается снова с 1,2,3…. Эти метки страниц отображаются в PDF
зрители — они не имеют никакого отношения к печатной продукции. Например, предисловие
книги могут быть пронумерованы i, ii, iii …, в то время как основное содержание
начинается снова с 1,2,3…. Эти метки страниц отображаются в PDF
зрители — они не имеют никакого отношения к печатной продукции. |
/ Имена | словарь | Словарь имен. Это содержит различные названия деревья , которые сопоставляют имена с сущностями, чтобы предотвратить использовать номера объектов для непосредственной ссылки на них. |
/ Dests | словарь | Словарь, отображающий имена в пункты назначения. Пункт назначения это описание места в документе PDF, в которое гиперссылка отправляет пользователю. |
/ Просмотрщик Настройки | словарь | Словарь настроек зрителя , который
позволяет флагам определять поведение средства просмотра PDF, когда
документ просматривается на экране, например, страница, на которой он открыт,
начальный масштаб просмотра и так далее. |
/ PageLayout | имя | Определяет макет страницы, который будет использоваться программами просмотра PDF. Ценности
являются / SinglePage , / OneColumn , / TwoColumnLeft , / TwoColumnRight , / TwoPageLeft , / TwoPageRight .
(По умолчанию: / SinglePage ). Подробности в таблице
28 ISO 32000-1: 2008. |
/ PageMode | имя | Определяет режим страницы, который будет использоваться программами просмотра PDF.Ценности / UseNone , / UseOutlines , / UseThumbs , / FullScreen , / UseOC , / UseAttachments . (По умолчанию: / UseNone ). Подробности в Таблице 28.
ISO 32000-1: 2008. |
/ Контуры | косвенная ссылка на словарь | Краткий словарь является корнем схема документа , широко известная как закладки. |
/ Метаданные | косвенная ссылка на stream | Метаданные XMP документа — см. Метаданные XML. |
Дерево страниц , построенное из словарей страниц , приносит вместе инструкции по рисованию графического и текстового контента (которые мы рассматриваем в Главе 5 и Главе 6) с ресурсами (шрифтами, изображениями и другими внешние данные), которые используются в этих инструкциях.Он также включает размер страницы, вместе с рядом других коробок определение кадрирования и т. д.
Записи в словаре страниц представлены в Таблице 4-4.
Таблица 4-4. Записи в словаре страниц (* обозначает обязательную запись)
| Ключ | Тип значения | Значение |
/ Тип * | имя | Должно быть / стр.. |
/ Родительский * | косвенная ссылка на словарь | Родительский узел этого узла в дереве страниц. |
/ Ресурсы | словарь | Ресурсы страницы (шрифты, изображения и т. Д.). Если это запись полностью опущена, ресурсы наследуются от родительский узел в дереве страниц. Если ресурсов действительно нет, включите эту запись, но используйте пустой словарь. |
/ содержание | косвенная ссылка на поток или массив таких ссылки | Графическое содержимое страницы в одном или нескольких разделах. Если эта запись отсутствует, страница пуста. |
/ Повернуть | целое | Поворот страницы при просмотре в градусах по часовой стрелке от
север. Значение должно быть кратно 90. Значение по умолчанию: 0. Это
относится как к просмотру, так и к печати. Если эта запись отсутствует,
его значение наследуется от родительского узла на странице
дерево. Значение по умолчанию: 0. Это
относится как к просмотру, так и к печати. Если эта запись отсутствует,
его значение наследуется от родительского узла на странице
дерево. |
/ MediaBox * | прямоугольник | Медиа-бокс страницы (размер его носитель, т.е. бумага). Для большинства целей размер страницы. Если это запись отсутствует, она унаследована от родительского узла на странице дерево. |
/ CropBox | прямоугольник | Поле обрезки страницы.Это определяет область страницы отображается по умолчанию при отображении или печати страницы. Если отсутствует, его значение определяется как такое же, как у медиа-бокса. |
Структура данных прямоугольника для медиа-бокс и другие коробки представляют собой массив из четырех
числа. Они определяют диагонально противоположные углы прямоугольника —
первые два элемента массива — x и y координаты одного угла, два последних элемента
быть таковыми из другого.Обычно нижний левый и верхний правый углы
даны. Так, например:
Они определяют диагонально противоположные углы прямоугольника —
первые два элемента массива — x и y координаты одного угла, два последних элемента
быть таковыми из другого.Обычно нижний левый и верхний правый углы
даны. Так, например:
/ MediaBox [0 0 500 800] / CropBox [100 100 400 700]
определяет страницу размером 500 на 800 точек с рамкой кадрирования, удаляющей 100 точек. на каждой стороне страницы.
Страницы связаны между собой с помощью страницы дерево , а не простой массив. Эта древовидная структура делает его
быстрее найти заданную страницу в документе с сотнями или тысячами
страниц. Хорошие PDF-приложения создают сбалансированное дерево (один с минимальной высотой для количества узлов).Это гарантирует, что
конкретная страница может быть найдена быстро. Узлы без дочерних узлов — это
сами страницы. Показан пример древовидной структуры для семи страниц.
на Рисунке 4-2.
Это будет записано в объектах PDF, как показано в Примере 4-2. Записи в промежуточном или корневом узел дерева страниц (то есть не сама страница) сведены в Таблицу 4-5.
Рисунок 4-2. Дерево страниц на семь страниц. Осталась точная форма дерева. в индивидуальное приложение PDF.Показан PDF-код для этого дерева. в Примере 4-2. Пример 4-2. Объекты PDF, используемые для построения дерева страниц, показанного на рисунке 4-21 0 obj Корневой узел << / Тип / Pages / Kids [2 0 R 3 0 R 4 0 R] / Счет 7 >> эндобдж 2 0 obj Промежуточный узел << / Type / Pages / Kids [5 0 R 6 0 R 7 0 R] / Parent 1 0 R / Count 3 >> эндобдж 3 0 obj Промежуточный узел << / Type / Pages / Kids [8 0 R 9 0 R 10 0 R] / Parent 1 0 R / Count 3 >> эндобдж 4 0 obj Стр.7 << / Тип / Страница / Родительский 1 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >> эндобдж 5 0 obj Страница 1 << / Тип / Страница / Родительский 2 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >> эндобдж 6 0 obj Стр.
 2
<< / Тип / Страница / Родительский 2 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
7 0 obj Стр. 3
<< / Тип / Страница / Родительский 2 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
8 0 obj Стр. 4
<< / Тип / Страница / Родительский 3 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
9 0 obj Стр.5
<< / Тип / Страница / Родительский 3 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
10 0 obj Стр.6
<< / Тип / Страница / Родительский 3 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
endobj
2
<< / Тип / Страница / Родительский 2 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
7 0 obj Стр. 3
<< / Тип / Страница / Родительский 2 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
8 0 obj Стр. 4
<< / Тип / Страница / Родительский 3 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
9 0 obj Стр.5
<< / Тип / Страница / Родительский 3 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
эндобдж
10 0 obj Стр.6
<< / Тип / Страница / Родительский 3 0 R / MediaBox [0 0 500 500] / Ресурсы << >> >>
endobj Таблица 4-5.Записи в промежуточном или корневом узле дерева страниц (* обозначает обязательная запись)
| Ключ | Тип значения | Значение |
/ Тип * | имя | Должно быть / Страницы . |
/ Kids * | массив косвенных ссылок | Непосредственные дочерние узлы дерева страниц этого узла. |
/ Счетчик * | целое число | Количество узлов страницы (не других узлов дерева страниц), которые являются возможными потомками этого узла. |
/ Родительский | косвенная ссылка на узел дерева страниц | Ссылка на родительский элемент этого узла (узел которого это ребенок). Должен присутствовать, если не корневой узел страницы дерево. |
В этом дереве на любой странице можно найти не более двух косвенных ссылок от корневого узла.
Строки вне фактического текстового содержимого страницы (например,г.,
названия закладок, информация о документе и т. д.) известны как текст струны . Они кодируются с использованием либо PDFDocEncoding или (в более поздних документах)
Юникод. PDFDocEncoding основан на кодировке ISO Latin-1. это
полностью задокументировано в Приложении D стандарта ISO 32000-1: 2008.
Текстовые строки, закодированные как Unicode, различаются глядя на первые два байта: это будет 254, за которыми следует 255. Это маркер порядка байтов Unicode U + FEFF, который указывает UTF16BE кодирование.Это означает, что строка PDFDocEncoding не может начинаться с þ (254). с последующим ÿ (255), но это вряд ли произойдет в любом разумном обстоятельство.
Даты создания и изменения / CreationDate и / ModDate в информационном словаре документа
являются примерами формата даты PDF, который кодирует дату в виде строки,
включая информацию о часовом поясе.
Строка даты имеет формат:
(D: YYYYMMDDHHmmSSOHH'mm ')
, где круглые скобки обозначают строку как обычно.Остальные части даты приведены в Таблице 4-6.
Таблица 4-6. Составные части формата даты PDF
| Часть | Значение |
ГГГГ | Год в четырехзначном формате, например, 2008 . |
ММ | Месяц, состоящий из двух цифр от 01 до 12 . |
DD | День в двухзначном формате от 01 до 31 . |
HH | Час в виде двух цифр от 00 до 23 . |
мм | Минута в виде двух цифр от 00 до 59 . |
СС | Второй, состоящий из двух цифр от 00 до 59 . |
O | Отношение местного времени к всемирному времени, либо + , - или Z . + означает, что местное время позже UT, – раньше и Z равно всемирному времени. |
HH ' | Абсолютное значение смещения от всемирного времени в
часов, двумя цифрами от 00 до 23 . |
мм ' | Абсолютное значение смещения от всемирного времени в
минуты, двумя цифрами из 00 на номер 59 . |
Все части даты после года необязательны. Например, (D: 1999) совершенно верно. Ясно,
однако, если вы опустите одну часть, вы должны пропустить все, что следует за этим,
иначе результат был бы неоднозначным.Значения по умолчанию для ДД и ММ
01, для всех остальных частей по умолчанию — нули.
Например:
(D: 20060926213913 + 02'00 ')
представляет 26 сентября 2006 г., 21:39:13 вечера, во втором часовом поясе. часы опережают всемирное время.
Это текст, созданный вручную для преобразования в действительный PDF-файл. файл pdftk методом
представлен в главе 2. Это трехстраничный документ,
с информационным словарем документа и деревом страниц.На рис. 4-3 показан этот документ, отображаемый в Acrobat.
Читатель. Рисунок 4-4 — соответствующий объект
график.
файл pdftk методом
представлен в главе 2. Это трехстраничный документ,
с информационным словарем документа и деревом страниц.На рис. 4-3 показан этот документ, отображаемый в Acrobat.
Читатель. Рисунок 4-4 — соответствующий объект
график.
Пример 4-3. Трехстраничный документ с информацией о документе словарь
% PDF-1.1 Заголовок
1 0 obj Верхний уровень дерева страниц: имеет два дочерних элемента - страницу один и промежуточный узел дерева страниц .
<< / Kids [2 0 R 3 0 R] / Type / Pages / Count 3 >>
эндобдж
4 0 obj Поток содержимого для первой страницы
<< >>
ручей
1.0.000000 0.000000 1. 50. 770. cm BT / F0 36. Tf (Первая страница) Tj ET
конечный поток
эндобдж
2 0 obj Первая страница
<<
/ Повернуть 0
/ Родитель 1 0 R
/Ресурсы
<< / Шрифт << / F0 << / BaseFont / Times-Italic / Subtype / Type1 / Type / Font >> >> >>
/ MediaBox [0.000000 0.000000 595.2755 841.88976378]
/ Тип / Страница
/ Содержание [4 0 R]
>>
эндобдж
5 0 obj Каталог документов
<< / PageLayout / TwoColumnLeft / Pages 1 0 R / Type / Catalog >>
эндобдж
6 0 obj Страница три
<<
/ Повернуть 0
/ Родитель 3 0 R
/Ресурсы
<< / Шрифт << / F0 << / BaseFont / Times-Italic / Subtype / Type1 / Type / Font >> >> >>
/ MediaBox [0. 000000 0,000000 595.2755 841.88976378]
/ Тип / Страница
/ Содержание [7 0 R]
>>
эндобдж
3 0 obj Узел промежуточного дерева страниц, ссылающийся на вторую и третью страницы
<< / Родитель 1 0 R / Дети [8 0 R 6 0 R] / Счетчик 2 / Тип / Страницы >>
эндобдж
8 0 obj Страница 2
<<
/ Повернуть на 270
/ Родитель 3 0 R
/Ресурсы
<< / Шрифт << / F0 << / BaseFont / Times-Italic / Subtype / Type1 / Type / Font >> >> >>
/ MediaBox [0,000000 0,000000 595,2755 841.88976378]
/ Тип / Страница
/ Содержание [9 0 R]
>>
эндобдж
9 0 obj Поток контента для второй страницы
<< >>
ручей
q 1. 0.000000 0.000000 1. 50.770. cm BT / F0 36. Tf (Страница 2) Tj ET Q
1. 0.000000 0.000000 1. 50. 750 см BT / F0 16 Tf ((повернут на 270 градусов)) Tj ET
конечный поток
эндобдж
7 0 obj Поток контента для третьей страницы
<< >>
ручей
1. 0.000000 0.000000 1. 50. 770. cm BT / F0 36. Tf (Третья страница) Tj ET
конечный поток
эндобдж
10 0 obj Словарь информации о документе
<<
/ Заголовок (Пример с пояснениями в формате PDF)
/ Автор (Джон Уайтингтон)
/ Продюсер (создается вручную)
/ ModDate (D: 20110313002346Z)
/ CreationDate (D: 2011)
>>
endobj xref
0 11
Прицеп Словарь прицепов
<<
/ Инфо 10 0 R
/ Корень 5 0 R
/ Размер 11
/ ID [<75ff22189ceac848dfa2afec93deee03> <75ff22189ceac848dfa2afec93deee03>]
>>
startxref
0
%% EOF Рисунок 4-3. 000000 0,000000 595.2755 841.88976378]
/ Тип / Страница
/ Содержание [7 0 R]
>>
эндобдж
3 0 obj Узел промежуточного дерева страниц, ссылающийся на вторую и третью страницы
<< / Родитель 1 0 R / Дети [8 0 R 6 0 R] / Счетчик 2 / Тип / Страницы >>
эндобдж
8 0 obj Страница 2
<<
/ Повернуть на 270
/ Родитель 3 0 R
/Ресурсы
<< / Шрифт << / F0 << / BaseFont / Times-Italic / Subtype / Type1 / Type / Font >> >> >>
/ MediaBox [0,000000 0,000000 595,2755 841.88976378]
/ Тип / Страница
/ Содержание [9 0 R]
>>
эндобдж
9 0 obj Поток контента для второй страницы
<< >>
ручей
q 1. 0.000000 0.000000 1. 50.770. cm BT / F0 36. Tf (Страница 2) Tj ET Q
1. 0.000000 0.000000 1. 50. 750 см BT / F0 16 Tf ((повернут на 270 градусов)) Tj ET
конечный поток
эндобдж
7 0 obj Поток контента для третьей страницы
<< >>
ручей
1. 0.000000 0.000000 1. 50. 770. cm BT / F0 36. Tf (Третья страница) Tj ET
конечный поток
эндобдж
10 0 obj Словарь информации о документе
<<
/ Заголовок (Пример с пояснениями в формате PDF)
/ Автор (Джон Уайтингтон)
/ Продюсер (создается вручную)
/ ModDate (D: 20110313002346Z)
/ CreationDate (D: 2011)
>>
endobj xref
0 11
Прицеп Словарь прицепов
<<
/ Инфо 10 0 R
/ Корень 5 0 R
/ Размер 11
/ ID [<75ff22189ceac848dfa2afec93deee03> <75ff22189ceac848dfa2afec93deee03>]
>>
startxref
0
%% EOF
000000 0,000000 595.2755 841.88976378]
/ Тип / Страница
/ Содержание [7 0 R]
>>
эндобдж
3 0 obj Узел промежуточного дерева страниц, ссылающийся на вторую и третью страницы
<< / Родитель 1 0 R / Дети [8 0 R 6 0 R] / Счетчик 2 / Тип / Страницы >>
эндобдж
8 0 obj Страница 2
<<
/ Повернуть на 270
/ Родитель 3 0 R
/Ресурсы
<< / Шрифт << / F0 << / BaseFont / Times-Italic / Subtype / Type1 / Type / Font >> >> >>
/ MediaBox [0,000000 0,000000 595,2755 841.88976378]
/ Тип / Страница
/ Содержание [9 0 R]
>>
эндобдж
9 0 obj Поток контента для второй страницы
<< >>
ручей
q 1. 0.000000 0.000000 1. 50.770. cm BT / F0 36. Tf (Страница 2) Tj ET Q
1. 0.000000 0.000000 1. 50. 750 см BT / F0 16 Tf ((повернут на 270 градусов)) Tj ET
конечный поток
эндобдж
7 0 obj Поток контента для третьей страницы
<< >>
ручей
1. 0.000000 0.000000 1. 50. 770. cm BT / F0 36. Tf (Третья страница) Tj ET
конечный поток
эндобдж
10 0 obj Словарь информации о документе
<<
/ Заголовок (Пример с пояснениями в формате PDF)
/ Автор (Джон Уайтингтон)
/ Продюсер (создается вручную)
/ ModDate (D: 20110313002346Z)
/ CreationDate (D: 2011)
>>
endobj xref
0 11
Прицеп Словарь прицепов
<<
/ Инфо 10 0 R
/ Корень 5 0 R
/ Размер 11
/ ID [<75ff22189ceac848dfa2afec93deee03> <75ff22189ceac848dfa2afec93deee03>]
>>
startxref
0
%% EOF  Пример 4-3 преобразован в действительный PDF-файл
с pdftk и отображается в Acrobat Reader
Пример 4-3 преобразован в действительный PDF-файл
с pdftk и отображается в Acrobat ReaderОбщие сведения о формате переносимого документа (PDF)
Структура файла PDF аналогична различным уровням иерархии в типичной компании. Подобно генеральному директору, словарь каталога документов находится на вершине иерархии. Фактически вы можете просмотреть структуру PDF-файла с помощью инструмента PDFDebugger — я включил более подробную информацию на эту веб-страницу http://www.printmyfolders.com/view-structure-of-a-pdf
Как мы видели ранее, чтение PDF-файла приложение сначала просмотрит трейлер PDF.В трейлере будет корневая запись, в которой указано расположение каталога. Это похоже на человека ( приложение для чтения PDF ), приближающегося к генеральному директору ( Каталог документов ) после того, как он нашел ее контактные данные через контактный раздел ( трейлер ) на веб-сайте компании ( PDF файл ).
Каталог документов: Каталог документов — это словарь, который ссылается на другие объекты, определяющие файл PDF.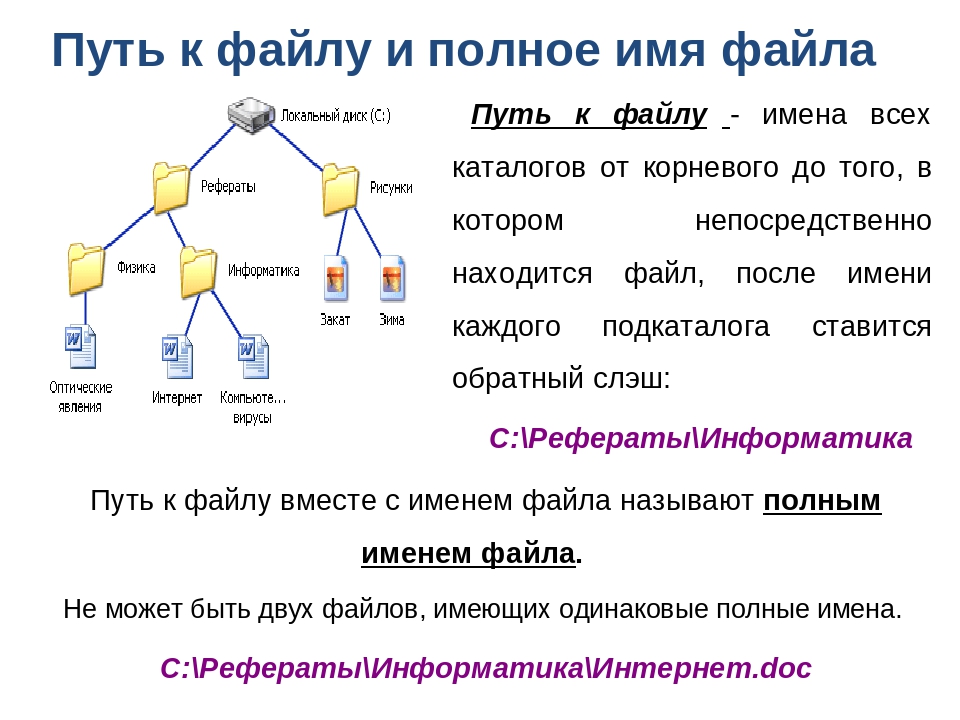 По сути, Каталог документов похож на центр, откуда можно найти любую информацию о файле PDF.Как словарь, он состоит из различных ключей. Мы пока рассмотрим только обязательные ключи.
По сути, Каталог документов похож на центр, откуда можно найти любую информацию о файле PDF.Как словарь, он состоит из различных ключей. Мы пока рассмотрим только обязательные ключи.
Тип — всегда будет Каталог (имя типа)
Страницы — Косвенная ссылка на объект, который является корнем дерева страниц (рассмотрим это позже)
A PDF-файл, который я создал с помощью бесплатного программного обеспечения для создания PDF-файлов, имеет этот словарь каталога
1 0 obj << / Тип / Каталог / Страницы 3 0 R >> endobj Вы заметите, что каждый из этих словарей всегда начинается с записи «/ Тип», которая описывает, какой это тип словаря.В данном случае это словарь «Каталог».
Приложение, которое читает указанный выше словарь Catolog, будет знать, что ему необходимо прочитать словарь «Страницы» (косвенный объект 3), чтобы получить информацию о страницах в этом файле PDF.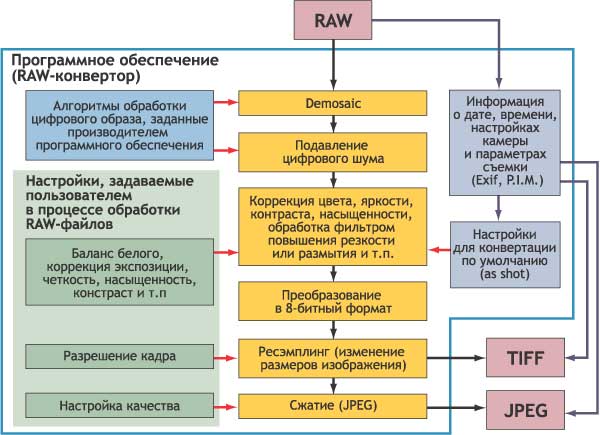
Дерево страниц: Дерево страниц - это имя структуры, используемой для описания страниц в файле PDF. Он имеет два типа узлов - узлов дерева страниц, и объектов страниц. Каждая страница в файле PDF представлена как объект страницы.Каждый из этих объектов называется «листовым» узлом в дереве страниц.
Узлы дерева страниц: Обязательные ключи:
Тип - всегда будет Страницы для узла дерева страниц
Родительский - узел дерева страниц, который является родительским узлом этого узла. Не допускается в корневом узле.
Kids - массив, относящийся к дочерним элементам этого узла. Дочерние элементы могут быть только узлами дерева страниц или объектами страниц
Счетчик - количество объектов страницы, которые являются потомками этого узла
В PDF-файле, который я создал ранее, есть это дерево страниц (помните, что Словарь каталога указывал на косвенный объект 3).
3 0 obj << / Тип / Страницы / Дети [ 4 0 R ] / Счетчик 1 / Повернуть 0 >> endobj У этого узла дерева страниц есть только один дочерний элемент, который является объектом 4. Ключ Parent отсутствует, поэтому это корневой узел.
Поскольку / Count равно 1, мы можем с уверенностью предположить, что под этим деревом страниц находится только 1 страница (которая на основе массива / Kids является косвенным объектом 4.
Как упоминалось ранее, вы заметите, что в этом словаре тоже есть запись «/ Тип», которая показывает, какой это тип словаря.
Объекты страницы : это словарь, который раскрывает характеристики самой страницы. Некоторые из ключей:
Примечание: Большинство ключей для меня новые. Я намеренно упустил ключи, которые в данный момент не имеют для меня смысла. По мере того, как я узнаю больше о спецификации PDF, я, надеюсь, подробно расскажу о них.
По мере того, как я узнаю больше о спецификации PDF, я, надеюсь, подробно расскажу о них.
Тип - всегда будет Page
Родительский - Косвенная ссылка на родительский элемент этой страницы
LastModified - Дата и время последнего изменения этой страницы
Ресурсы - Ресурсы, необходимые для эта страница. Обычно это относится к шрифту, используемому на этой странице, и другой информации.
MediaBox - прямоугольник, определяющий границу, внутри которой должна отображаться страница.
Содержимое - поток содержимого, описывающий содержимое этой страницы.
Повернуть - кратно 90. Поворачивает страницу на количество градусов перед отображением.
Thumb - объект потока, который дает эскиз изображения для этой страницы.
Dur - количество секунд, в течение которых страница будет отображаться в презентациях перед автоматическим переходом к следующей странице.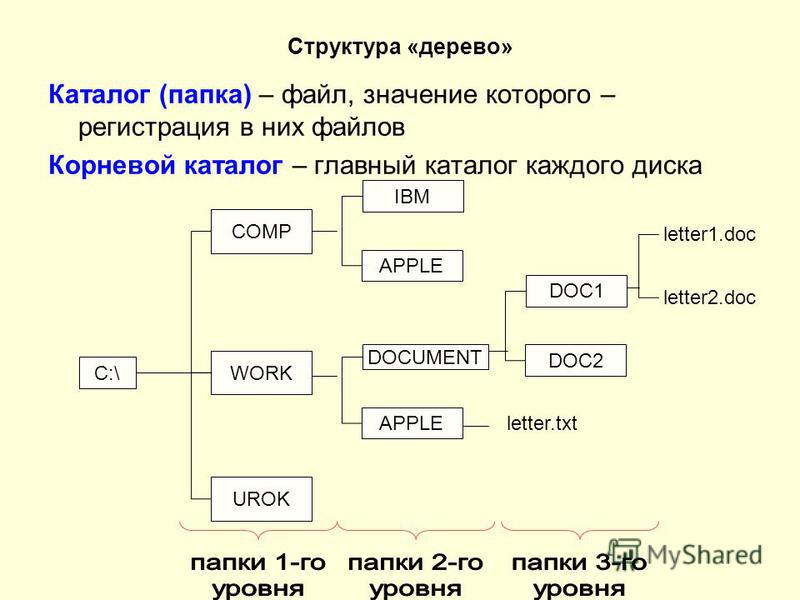
Trans - словарь, указывающий, какой переход использовать при отображении страницы во время презентации.
Аннотации - Это массив словарей, содержащий ссылки на все аннотации к этой странице
AA - Это сокращенная форма для дополнительных действий.Этот словарь определяет действия, которые необходимо предпринять при открытии или закрытии файла.
Метаданные - поток, содержащий метаданные для этой страницы
Вот отрывок из образца PDF, который я создал с помощью бесплатного программного обеспечения для создания PDF.
4 0 obj << / Тип / Страница / MediaBox [0 0 595 842] / Повернуть 0 / Родительский 3 0 R / Ресурсы << / ProcSet [/ PDF / Текст] / ExtGState 10 0 R / Шрифт 11 0 R >> / Содержание 5 0 R >> endobj 3 0 obj << / Тип / Страницы / Дети [ 4 0 R ] / Счетчик 1 / Повернуть 0 >> endobj 1 0 obj << / Тип / Каталог / Страницы 3 0 R >> endobj Как видите, Объект 1 - это каталог, который направляет приложение для чтения PDF в корень дерева страниц (Obj и т.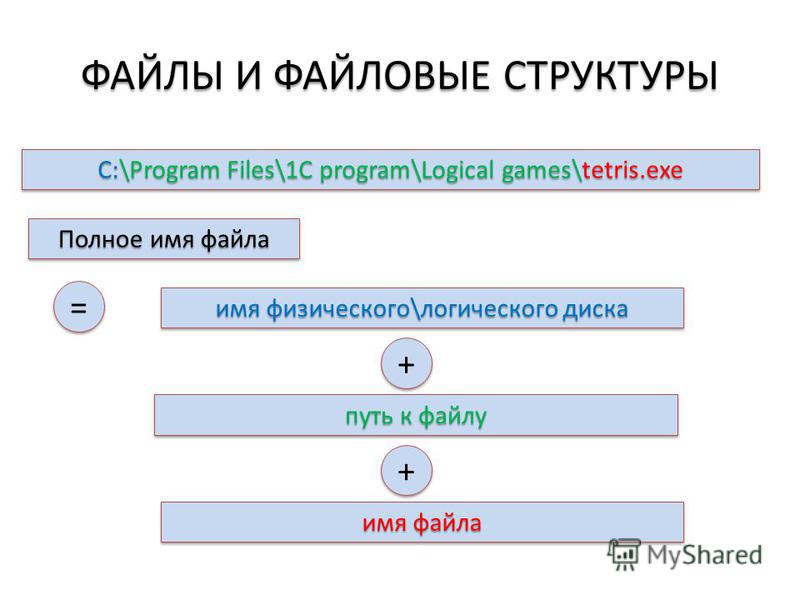 д. 3).Объект 3, корневой узел имел только одного ребенка (объект 4) и, очевидно, не мог иметь родителя. Объект 4 «отображается» в прямоугольнике (0 0 595 842), не поворачивается (Повернуть 0) и имеет Объект 3 в качестве своего родителя. Включены его «ресурсы», а также его содержимое (объект 5). Вот объект 5 из моего файла.
д. 3).Объект 3, корневой узел имел только одного ребенка (объект 4) и, очевидно, не мог иметь родителя. Объект 4 «отображается» в прямоугольнике (0 0 595 842), не поворачивается (Повернуть 0) и имеет Объект 3 в качестве своего родителя. Включены его «ресурсы», а также его содержимое (объект 5). Вот объект 5 из моего файла.
Как мы обсуждали ранее, поток в этом объекте начинается со словаря, который показывает длину потока (который хранится в объекте 6). Мы обсудим больше о потоках контента ниже..uujNWnjY :: si / .L9, ČGPY1k /.% 'f! endstream
endobj Атрибуты страницы наследуются: Интересный факт. Некоторые атрибуты страницы могут быть унаследованы от ее родителя или любого из ее предков в дереве страниц. Устраняет необходимость повторять одинаковые атрибуты для каждого дочернего элемента, внука и т. Д. Если предок определяет значение для атрибута, это значение может быть заменено или изменено дочерним элементом.
Словарь имен: Вместо того, чтобы ссылаться на объекты по их ссылкам, на некоторые объекты можно ссылаться по их именам. Связь между именами и ссылками на них хранится в словаре имен PDF-файла. Один из дополнительных ключей в каталоге, Names , используется для указания словаря имен . Пожалуйста, обратитесь к спецификации PDF для получения более подробной информации.
Связь между именами и ссылками на них хранится в словаре имен PDF-файла. Один из дополнительных ключей в каталоге, Names , используется для указания словаря имен . Пожалуйста, обратитесь к спецификации PDF для получения более подробной информации.
Потоки контента: Это поток (объект в формате PDF, если вы помните), в котором есть инструкции по отображению текста и графики на соответствующей странице. В объекте 5 моего PDF-файла, упомянутого ранее и повторенного ниже, мы можем видеть поток..uujNWnjY :: si / .L9, ČGPY1k /.% 'f! endstream
endobj Данные в потоке не имеют смысла, потому что данные были закодированы (преобразованы из исходной формы в другую). В следующих разделах мы более подробно рассмотрим структуру этих данных и поймем, как они формируют инструкции для приложения для чтения PDF-файлов для отображения страницы.
Обратите внимание, что в отличие от других объектов в файле PDF, инструкции в потоке объектов читаются и выполняются последовательно (одна за другой).
Прежде чем продолжить, мы попытаемся создать простой файл PDF на основе того, что мы узнали до сих пор.
Пример PDF-файла: Вот пример PDF-файла, который я создал с помощью спецификации. Вы можете скопировать этот файл отсюда и сохранить его в текстовом редакторе, например, в блокноте. Сохраните его с именем файла, но с расширением файла «pdf». В блокноте вам нужно будет сохранить как «filename.pdf» (включая кавычки). Затем вы можете просмотреть его с помощью программы для чтения PDF-файлов (например, с помощью Acrobat Reader). Примечание. Не все файлы PDF такие простые. Это очень простой PDF-файл, в котором отображается всего одна строка текста.
Продолжение статьи: Общие сведения о формате переносимых документов (PDF): Часть 2
Мне нравятся ваши отзывы и предложения. Пожалуйста, оставьте комментарий ниже или свяжитесь со мной по адресу [email protected].
| Общие | Предыдущий абзац дает подробное представление о возможном размере PDF-файла. Многие комментаторы утверждают, что предел практичности ниже, чем указано выше. Важно то, можете ли вы открыть данный PDF-файл в любом подходящем приложении, включая Acrobat и Adobe Reader, упомянутые выше.Интернет-форумы также включают отчеты, подобные этим примерам: «Похоже, что у iPad есть ограничение в 30 МБ для отображения файлов PDF» и «пользователи GoodReader сообщают о безупречной производительности с файлами размером более 1 ГБ». Практические ограничения, накладываемые приложениями, могут также включать ограничения, устанавливаемые индексаторами, если PDF-файл содержит доступный для поиска текст. Самоидентификация хронологических версий PDF : Идентификация хронологических версий PDF может быть дана в двух местах в файле PDF.Все файлы PDF должны иметь версию, указанную в заголовке с помощью 5 символов Сжатие «объектов потока» в файлах PDF : Объекты потока в файле PDF часто сжимаются. Для файлов PDF поддерживается ряд схем сжатия, обозначенных значениями фильтра, определенными в спецификации.Имена фильтров соответствуют декодированию / распаковке, которые необходимо применить для восстановления исходных данных. Фильтры можно объединять в конвейеры. Перечисленные ниже фильтры разрешены в общих файлах PDF. Однако некоторые фильтры не разрешены в «подмножествах стандартов для PDF», таких как PDF / A, PDF / X и PDF / E.
Фильтр Crypt (представленный в PDF 1.5) может использоваться для определения алгоритма шифрования, который был применен к потоку данных. Многие алгоритмы шифрования, поддерживаемые в более ранних хронологических версиях PDF, теперь устарели. PDF с тегами : Концепция PDF с тегами была введена в PDF 1.4. В дополнение к дереву содержимого, которое является частью любого PDF-файла, PDF-файл с тегами также имеет структурное дерево. Теги обеспечивают логическую структуру, которая управляет представлением содержимого документа с помощью вспомогательных технологий.Каждый тег идентифицирует связанный элемент содержимого, например абзац , заголовок третьего уровня , элемент списка. Порядок тегов определяет порядок чтения. Справочник PDF (третье издание), который определяет PDF 1.4, указывает, что |  w3.org/2001/XMLSchema-instance"> Tagged PDF представляет собой стилизованное использование PDF, в котором используется набор стандартных типов структур и атрибутов, которые позволяют извлекать содержимое страницы (текст, графику и изображения) и повторно используется для других целей.PDF-файлы с тегами следуют набору правил для представления текста в содержимом страницы, чтобы символы, слова и
порядок текста может быть надежно определен для использования инструментами, выполняющими такие операции, как: w3.org/2001/XMLSchema-instance"> Tagged PDF представляет собой стилизованное использование PDF, в котором используется набор стандартных типов структур и атрибутов, которые позволяют извлекать содержимое страницы (текст, графику и изображения) и повторно используется для других целей.PDF-файлы с тегами следуют набору правил для представления текста в содержимом страницы, чтобы символы, слова и
порядок текста может быть надежно определен для использования инструментами, выполняющими такие операции, как:
Многие файлы PDF создаются с помощью «печати в PDF» или других методов, которые не позволяют создавать структуры тегов.
Руководство по специальным возможностям с использованием Adobe InDesign побуждает пользователей «применять специальные возможности в вашем документе InDesign, вместо того, чтобы вносить серьезные изменения в программное обеспечение Adobe Acrobat.Теги PDF, альтернативные теги и порядок содержимого, который вы назначаете, остаются в документе при его редактировании ". Руководство по передовой практике PDF с тегами: синтаксис, выпущенное в 2019 году Технической рабочей группой PDF / UA (PDF / UA TWG), содержит подробное руководство, направленное на доступность. |
|---|
 \fdd.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> Максимальный размер PDF-файлов : Эта тема обсуждалась на ряде онлайн-форумов.На одном из форумов Adobe в ответ на вопрос 2012 года «Есть ли ограничение на размер PDF?» Описан очень высокий теоретический предел количества страниц: «Явного ограничения количества страниц нет, но есть ограничение на косвенные объекты в 8 388 607 из 32 -битное приложение для рендеринга PDF - Acrobat и Adobe Reader представляют собой 32-битный код, и поскольку каждая страница использует по крайней мере один косвенный объект, каждый PDF-файл, созданный или открытый Acrobat, должен содержать меньше страниц, чем это. создать собственное приложение PDF x64, вы могли бы добавить больше страниц, но полученные файлы вообще не открывались бы в 32-разрядных приложениях.В этой записи форума говорится: «С архитектурной точки зрения в стандарте PDF есть только одно ограничение: общий размер файла должен быть ниже ~ 10 ГБ, поскольку таблицы перекрестных ссылок, которые определяют структуру PDF, используют 10 бит».
\fdd.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> Максимальный размер PDF-файлов : Эта тема обсуждалась на ряде онлайн-форумов.На одном из форумов Adobe в ответ на вопрос 2012 года «Есть ли ограничение на размер PDF?» Описан очень высокий теоретический предел количества страниц: «Явного ограничения количества страниц нет, но есть ограничение на косвенные объекты в 8 388 607 из 32 -битное приложение для рендеринга PDF - Acrobat и Adobe Reader представляют собой 32-битный код, и поскольку каждая страница использует по крайней мере один косвенный объект, каждый PDF-файл, созданный или открытый Acrobat, должен содержать меньше страниц, чем это. создать собственное приложение PDF x64, вы могли бы добавить больше страниц, но полученные файлы вообще не открывались бы в 32-разрядных приложениях.В этой записи форума говорится: «С архитектурной точки зрения в стандарте PDF есть только одно ограничение: общий размер файла должен быть ниже ~ 10 ГБ, поскольку таблицы перекрестных ссылок, которые определяют структуру PDF, используют 10 бит».
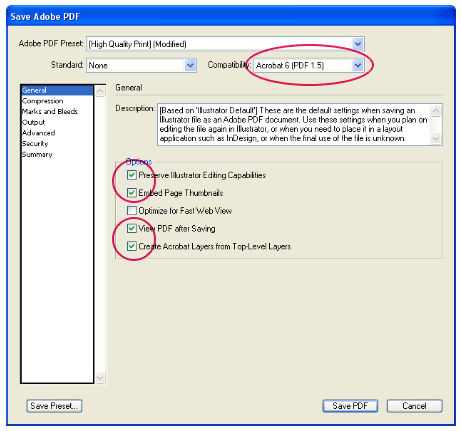 \fdd.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">% PDF– , за которыми следует номер версии в форме 1.N, где N - это цифра от 0 до 7 или номер версии 2.0. Например, PDF 1.7 будет идентифицирован как % PDF – 1.7 . Однако, начиная с PDF 1.4, соответствующий писатель PDF может использовать запись Версия в Каталоге документа, чтобы переопределить версию, указанную в заголовке. Расположение Каталога в файле указывается в корневой записи концевого / нижнего колонтитула файла.Эта функция переопределения была введена для облегчения постепенного обновления PDF-файла путем простого добавления в конец файла. В результате необходимо найти Каталог в файле, чтобы получить правильный номер версии. Если PDF не является «линеаризованным», и в этом случае Каталог находится впереди, для этого потребуется прочитать трейлер, а затем использовать ссылку там, чтобы найти Каталог, который обычно будет сжат. Это имеет практическое значение, поскольку инструменты идентификации формата, включая DROID, обычно ищут определенные символы в начале файла (т.
\fdd.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">% PDF– , за которыми следует номер версии в форме 1.N, где N - это цифра от 0 до 7 или номер версии 2.0. Например, PDF 1.7 будет идентифицирован как % PDF – 1.7 . Однако, начиная с PDF 1.4, соответствующий писатель PDF может использовать запись Версия в Каталоге документа, чтобы переопределить версию, указанную в заголовке. Расположение Каталога в файле указывается в корневой записи концевого / нижнего колонтитула файла.Эта функция переопределения была введена для облегчения постепенного обновления PDF-файла путем простого добавления в конец файла. В результате необходимо найти Каталог в файле, чтобы получить правильный номер версии. Если PDF не является «линеаризованным», и в этом случае Каталог находится впереди, для этого потребуется прочитать трейлер, а затем использовать ссылку там, чтобы найти Каталог, который обычно будет сжат. Это имеет практическое значение, поскольку инструменты идентификации формата, включая DROID, обычно ищут определенные символы в начале файла (т. е.д., в заголовке), чтобы позволить идентификацию с минимальными усилиями. DROID может искать символы в конце файла, но не может следить за косвенной ссылкой или распаковывать содержимое файла. Если номер версии в заголовке и в Каталоге не совпадает, существует вероятность ошибок идентификации формата.
е.д., в заголовке), чтобы позволить идентификацию с минимальными усилиями. DROID может искать символы в конце файла, но не может следить за косвенной ссылкой или распаковывать содержимое файла. Если номер версии в заголовке и в Каталоге не совпадает, существует вероятность ошибок идентификации формата. Этот фильтр был разработан для Postscript в то время, когда было полезно преобразовать двоичные данные в представление, которое можно было безопасно использовать в почтовых сообщениях.Двоичные данные можно преобразовать в ASCII, представив каждый байт двоичных данных в виде двух шестнадцатеричных цифр ASCII (0–9 и либо A – For a – f). Символы новой строки добавляются в закодированный вывод не реже одного раза через каждые 80 символов, тем самым ограничивая длину строк. Полученные данные были вдвое больше, чем исходная двоичная форма. См. Справочник по языку PostScript, 3-е издание.
Этот фильтр был разработан для Postscript в то время, когда было полезно преобразовать двоичные данные в представление, которое можно было безопасно использовать в почтовых сообщениях.Двоичные данные можно преобразовать в ASCII, представив каждый байт двоичных данных в виде двух шестнадцатеричных цифр ASCII (0–9 и либо A – For a – f). Символы новой строки добавляются в закодированный вывод не реже одного раза через каждые 80 символов, тем самым ограничивая длину строк. Полученные данные были вдвое больше, чем исходная двоичная форма. См. Справочник по языку PostScript, 3-е издание. См. Справочник по языку PostScript, 3-е издание.
См. Справочник по языку PostScript, 3-е издание. См. Сжатие факсов группы 4 ITU-T.
См. Сжатие факсов группы 4 ITU-T.
 Как правило, логическая структура документа представлена в файле PDF только в том случае, если создатель или процесс во время создания предпринимают шаги для включения структурных тегов. См. Что такое PDF с тегами? из 2004 г., в котором Дафф Джонсон сказал: «Теги могут быть автоматически сгенерированы для любого файла PDF с помощью Acrobat 6.0 Professional, но если документ действительно не очень прост, автоматическая установка тегов вряд ли даст удовлетворительные результаты и, конечно же, не поможет быстро. исправить для соответствия Разделу 508.«Некоторые приложения, для которых собственный формат по своей природе структурирован соответствующим образом, имеют специализированный экспорт, который может создавать файлы PDF с тегами, которые представляют эту структуру. Например, согласно описанию экспорта в PDF с расширенными возможностями из Framemaker (программное обеспечение для настольных издательских систем)», - предоставляет Adobe PDF с тегами следующие возможности:
Как правило, логическая структура документа представлена в файле PDF только в том случае, если создатель или процесс во время создания предпринимают шаги для включения структурных тегов. См. Что такое PDF с тегами? из 2004 г., в котором Дафф Джонсон сказал: «Теги могут быть автоматически сгенерированы для любого файла PDF с помощью Acrobat 6.0 Professional, но если документ действительно не очень прост, автоматическая установка тегов вряд ли даст удовлетворительные результаты и, конечно же, не поможет быстро. исправить для соответствия Разделу 508.«Некоторые приложения, для которых собственный формат по своей природе структурирован соответствующим образом, имеют специализированный экспорт, который может создавать файлы PDF с тегами, которые представляют эту структуру. Например, согласно описанию экспорта в PDF с расширенными возможностями из Framemaker (программное обеспечение для настольных издательских систем)», - предоставляет Adobe PDF с тегами следующие возможности:
| Обзор в формате PDF - изучение внутреннего устройства PDF | ||
| Автор: Аюш Ананд | ||
| ||
В этой вводной статье я объясню внутреннее устройство PDF. документ, его структуры и компоненты с примерами и
скриншоты. Это поможет вам понять сущность PDF
документ и будет более полезен, если вы занимаетесь анализом вредоносных программ PDF. документ, его структуры и компоненты с примерами и
скриншоты. Это поможет вам понять сущность PDF
документ и будет более полезен, если вы занимаетесь анализом вредоносных программ PDF. | ||
Синтаксис PDF состоит из четырех основных компоненты: | ||
| ||
| Файл PDF состоит в основном из объектов, которых восемь типы: | ||
| ||
Я расскажу подробнее о каждом из
Подробнее об этих объектах в следующем разделе. | ||
| Строковые объекты могут быть представлены двумя способы: | ||
| ||
| Буквенные строки состоят из любого количества символы между открывающими и закрывающими круглыми скобками. | ||
| Пример (Это строковые объекты) Если строка слишком длинная, она может быть представлен с использованием обратной косой черты, как показано ниже (Это очень длинная строка \ .) Шестнадцатеричные строки состоят из шестнадцатеричных символов. заключить в скобку-ангел Пример: | ||
| Здесь каждая пара шестнадцатеричных чисел определяет один байт строки. | ||
Объект имен однозначно определяется
последовательность символов. Символ косой черты (/) определяет имя. Символ косой черты (/) определяет имя. | ||
| Пример / secsavvy / SecSavvy Оба имени разные. / Sec # 20Savvy Среднее значение Sec Savvy 20 - это шестнадцатеричное значение для пробела. Примечание: Pdf чувствителен к регистру. | ||
| Объект массива - это набор объектов. Объект массива PDF может быть неоднородным.Он определяется квадратом скобки. | ||
| Пример [1 (строка) / Имя 3.14] | ||
| Объект словаря состоит из пар
объекты. Первый элемент является ключевым, а второй - значением. Ключ должен иметь имя. Словарь записывается как последовательность
пары ключ-значение, заключенные в двойные угловые скобки (<< >>). | ||
| Пример << / Type / Pages / Kids [4 0 R] / Count 1 >> Count is a ключ, а 1 - значение. | ||
| Объект потока, как и строковый объект,
последовательность байтов. Поток может быть неограниченной длины, тогда как
строка подлежит ограничению реализации.По этой причине,
объекты с потенциально большими объемами данных, например изображения и
описания страниц представлены в виде потоков. поток состоит из словаря, за которым следует ноль или более байтов в квадратных скобках между ключевыми словами поток и конечный поток: | ||
| словарь поток | ||
Объекты могут быть помечены так, чтобы их можно было
упомянутые другими объектами. Помеченный объект называется косвенным
объект. Помеченный объект называется косвенным
объект. | ||
| Пример Рассмотрим объект obj, а endobj - ключевое слово. 10
0 obj Этот объект определил строку
объекта номер 10. | ||
| Фильтр является дополнительной частью
спецификация потока, указывающая, как данные в потоке
должны быть декодированы перед использованием.Например, если у потока есть
Фильтр ASCIIHexDecode, приложение, считывающее данные в этом
поток преобразует данные в шестнадцатеричной кодировке ASCII в
поток в двоичные данные. Для данных, закодированных с использованием LZW и ASCII кодировку base-85 (в этом порядке) можно декодировать, используя следующие запись в словаре потока: / Filter [ / ASCII85Decode / LZWDecode] | ||
| Пример 1 0 obj << / Длина 534 / Фильтр [/ ASCII85Decode / LZWDecode] >> поток J. endstream | ||
| Вот список стандартных фильтров | ||
| ||
| PDF-файл состоит из 4 основных элементов: | ||
| ||
| Таблица перекрестных ссылок содержит
информация, которая разрешает произвольный доступ к косвенным объектам внутри
файл, так что не нужно читать весь файл, чтобы найти какие-либо
конкретный объект.Таблица содержит однострочную запись для каждого
косвенный объект, определяющий местоположение этого объекта в пределах
тело файла. Каждый раздел перекрестных ссылок начинается с строка, содержащая ключевое слово xref. После этой строки идут один или дополнительные разделы с перекрестными ссылками, которые могут появляться в любом порядке. Каждый подраздел перекрестных ссылок содержит записи для непрерывный диапазон номеров объектов. Подраздел начинается с строка, содержащая два числа, разделенных пробелом: номер объекта первого объекта в этом подразделе и количество записей в подраздел.Например, строка 0 8 вводит подраздел, содержащий пять пронумерованных объектов. | ||
| xref 0 8 0000000000 65535 f 0000000009 00000 n 0000000074 00000 n 0000000120 00000 n 0000000179 00000 n 000003 000014 0014 0014 00000 n | ||
| 0000000009 - это 10-значное смещение байта в
случай использования записи, указывающий количество байтов с начала
файла в начало объекта. 0000000000 - это 10-значный номер следующего свободного объекта в случае бесплатного запись | ||
| Вот серия снимков экрана, которые показывает различные части образца PDF-документа. | ||
Эта статья вкратце объясняет внутреннее устройство
PDF-документа, его структуры, составные части с примерами и
подробные скриншоты. Надеюсь, эта статья поможет вам в
работа по исследованию вредоносных программ, основанная на документах PDF. Надеюсь, эта статья поможет вам в
работа по исследованию вредоносных программ, основанная на документах PDF.Для новичков этого достаточно, но опытным пользователям рекомендуется прочтите справочный документ для получения более подробной информации. | ||

 kJZ! C2h2'TO] Rl? Q: & <5 & iP! $ Rq; BXRecDN [IJB`,) o8XJOSJ9sDS] hQ; Rj @! ND) bD_q & C \ g: inYC%) & u #: u, M6Bm% IY! Kb1 +: aAaS`ViJglLb8
kJZ! C2h2'TO] Rl? Q: & <5 & iP! $ Rq; BXRecDN [IJB`,) o8XJOSJ9sDS] hQ; Rj @! ND) bD_q & C \ g: inYC%) & u #: u, M6Bm% IY! Kb1 +: aAaS`ViJglLb8 
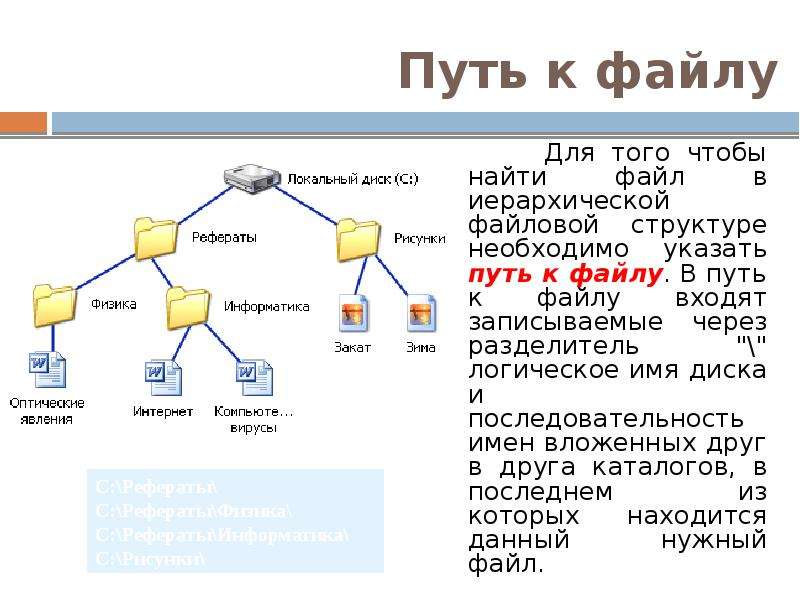 последовательно от 0 до 8.
последовательно от 0 до 8.Синтаксис PDF 101 | PSPDFKit
В этой статье мы рассмотрим некоторые аспекты внутренней структуры PDF-файла и дадим обзор некоторых строительных блоков, из которых состоит формат файла.
Все, что касается структуры PDF, описано в спецификации PDF, хотя иногда спецификация PDF может быть немного расплывчатой, или фактическое поведение, даже в продуктах Adobe, может незначительно отличаться в фактической реализации. Таким образом, при синтаксическом анализе PDF вам нужно будет отрегулировать некоторые крайние случаи и проанализировать некоторые вещи нечетко, чтобы строго не отклонять все, что отличается от спецификации.
Поскольку PSPDFKit уже выполняет синтаксический анализ и интерпретацию файлов PDF, даже в самых необычных случаях, вам не нужно вручную обрабатывать PDF-файлы.Но если вам все еще интересно, как PDF-файл выглядит изнутри и как создаются визуальные представления страниц, (будь моим гостем и) читайте дальше.
Структура файла
Вот как выглядит простой PDF-файл с одной страницей и текстом «Hello PSPDFKit», когда он отображается в виде исходного текста:
% PDF-1.7 1 0 объект << / Тип / Каталог / Страниц 2 0 R >> эндобдж 2 0 obj << / Тип / Pages / Kids [3 0 R] / Count 1 >> эндобдж 3 0 obj << / Тип / Страница / Родительский 2 0 R / MediaBox [0 0 595 842] / Ресурсы 4 0 R / Содержание 5 0 R >> эндобдж 4 0 объект << / ProcSet [/ PDF / Text] / Font << / Font1 << / Type / Font / Subtype / TrueType / BaseFont / Helvetica >> >> >> эндобдж 5 0 объект << / Длина 55 >> ручей BT / Font1 35 Тф 1 0 0 1 170 450 тм (Привет, PSPDFKit) Tj ET конечный поток эндобдж xref 0 6 0000000000 65535 ф 0000000009 00000 н.
 0000000062 00000 н.
0000000125 00000 н.
0000000239 00000 п.
0000000343 00000 п.
трейлер
<< / Корень 1 0 R / Размер 14 >>
startxref
382
%% EOF
0000000062 00000 н.
0000000125 00000 н.
0000000239 00000 п.
0000000343 00000 п.
трейлер
<< / Корень 1 0 R / Размер 14 >>
startxref
382
%% EOF Хотя в этом примере может показаться, что PDF-файлы являются текстовыми документами, это впечатление неверно, поскольку PDF-файлы являются двоичными документами.
Объекты PDF
PDF-файл состоит из так называемых объектов, которые могут иметь разные типы, такие как null, Boolean, integer, real, name, string, array, dictionary и stream.
На эти объекты можно ссылаться прямо или косвенно в файле. Прямые объекты помещаются в строку там, где они используются, в то время как косвенные объекты ссылаются и помещаются где-то в другом месте внутри документа.
Прямая ссылка на объект
Прямые объекты создаются inline, прямо в том месте, где они используются.
В этом фрагменте показано, как использовать шрифт как прямой объект:
<< / ProcSet [/ PDF / Text] / Font << / Font1 << / BaseFont / Helvetica / Subtype / TrueType / Type / Font >> >> >>
Косвенная ссылка на объект
Косвенные объекты ссылаются и помещаются в другое место внутри документа. Это требует, чтобы программы просмотра PDF просматривали реальный объект.
Это требует, чтобы программы просмотра PDF просматривали реальный объект.
Косвенные объекты определяются в PDF-документе, начиная с их уникального идентификатора, увеличивающегося положительного числа, за которым следует генерирующее число, которое обычно равно 0, вместе с ключевыми словами obj и endobj .
В этом фрагменте показано, как определить и использовать шрифт в качестве косвенного объекта:
3 0 объект << / Имя / Шрифт1 / BaseFont / Helvetica / Подтип / TrueType / Тип / Шрифт >> эндобдж 4 0 объект << / ProcSet [/ PDF / Text] / Font << / Font1 3 0 R >> >> endobj
Перекрестная ссылка
Теперь возникает вопрос: как программа просмотра PDF ищет ссылки на косвенный объект? Это делается с помощью таблицы перекрестных ссылок.
Вы могли заметить, что внизу PDF-файла находится ключевое слово startxref .Поскольку PDF-файлы читаются в обратном порядке, снизу вверх, это ключевое слово определяется внизу PDF-файла, а не вверху. Число после
Число после startxref указывает, с какого байта начинается таблица перекрестных ссылок ( xref ):
Фактическая таблица перекрестных ссылок определяет местоположение для каждого объекта в PDF:
xref 0 6 0000000000 65535 ф 0000000009 00000 н. 0000000062 00000 н. 0000000125 00000 н. 0000000239 00000 п. 0000000343 00000 п.
Первая строка показывает, что таблица содержит объявление для шести объектов.Помимо расположения каждого объекта в документе, вверху должен быть пустой объект 0. Поскольку в нашем примере PDF есть пять объектов, в таблице перекрестных ссылок указано расположение шести объектов (включая пустую секцию 0). Это позволяет программам просмотра PDF напрямую переходить к определенному объекту без необходимости анализировать весь документ.
Узнать больше
В этой статье мы изложили некоторые из основных принципов внутренней структуры PDF-файлов, а также обсудили, как определяется и указывается содержимое, отображаемое на странице документа.![]() Чтобы узнать больше о рендеринге в PSPDFKit или PDF-файлах в целом, перейдите к нашему руководству по рендерингу документов.
Чтобы узнать больше о рендеринге в PSPDFKit или PDF-файлах в целом, перейдите к нашему руководству по рендерингу документов.
Рекомендации по формату и размеру PDF-файла
При оптимизации PDF-файла для Интернета перед его публикацией в Flipsnack необходимо принять во внимание несколько моментов. В этой статье будут представлены наиболее частые проблемы и решение (или два) для каждой из них.
Вот как отформатировать PDF-файл в InDesign, чтобы обеспечить плавный процесс публикации в Flipsnack.Кроме того, мы создали набор настроек, гарантирующий, что создаваемый вами PDF-файл будет удобен для Flipsnack. Итак, продолжайте читать для получения дополнительной информации.
Экспорт из Adobe InDesign
Часто пользователи используют Adobe InDesign для создания PDF-файлов и заходят в Flipsnack для загрузки и обмена. Но иногда возникают ошибки. Вот что обычно происходит:
Неудачное преобразование , потому что одна или несколько страниц могут быть слишком сложными, возможно, содержащими слишком много векторных объектов.
Как узнать, что в вашем PDF-файле слишком много векторных объектов? Хороший вопрос!
Вот разница между вектором и растром в PDF:
Совет от профессионалов: При загрузке файлов PDF в Flipsnack у вас есть два основных варианта: оптимизированный PDF-файл и высокое качество.Первый вариант - вариант по умолчанию. Узнайте больше о том, как включить высококачественную загрузку PDF-файлов и выберите лучший вариант для вас.
Возвращаясь к нашему вопросу, как узнать, что в вашем PDF-файле слишком много векторных объектов?
Классный трюк - открыть файл PDF в Acrobat, Acrobat Reader или просто в браузере и увеличить масштаб до 400% или даже больше. Векторные файлы должны выглядеть идеально даже при таком разрешении. Кроме того, вы можете определить более сложные страницы, посмотрев, какие из них загружаются медленнее.Теперь, если вы удалите эти страницы и проверьте, успешно ли выполнено преобразование, вы получите ответ.
Что делать: Преобразовать дизайн более сложных страниц в растровую графику.
Примечание: Изображения в PDF также должны иметь разрешение менее 100 точек на дюйм - сохраните их как оптимизированные для быстрого просмотра в Интернете, а не для печати;
Ваши изображения не отображаются: вы, вероятно, используете неподдерживаемые функции, такие как рамки, маски или формы.
Очень важный аспект, о котором вы должны знать: эффекты InDesign, такие как тени, свечение, специальные штрихи или прозрачность, могут поддерживаться не полностью.
По возможности избегайте эффектов прозрачности в файле PDF. Упростите векторы, объединив похожие цветные слои, растрируйте вектор и попробуйте загрузить как оптимизированный PDF (вариант по умолчанию). Это решит вашу проблему, но может снизить четкость изображений.
Упрощение макета снова является ключевым моментом. Мы рекомендуем вам создать PDF-файл как , оптимизированный для Интернета или linear PDF .
Текст размыт, что делать:
Убедитесь, что текст находится сверху: просмотрите все слои в ваших документах.
Возможно, вы поместили полупрозрачное изображение поверх текстового слоя, и это может вызвать проблемы с тем, как выглядит текст при его загрузке в Flipsnack.Мы рекомендуем включать в выходной PDF только видимые слои.
При экспорте PDF-файла рекомендуется установить флажок Pages , а не развороты, как показано на этом снимке экрана.
 Возможно, вы поместили полупрозрачное изображение поверх текстового слоя, и это может вызвать проблемы с тем, как выглядит текст при его загрузке в Flipsnack.
Возможно, вы поместили полупрозрачное изображение поверх текстового слоя, и это может вызвать проблемы с тем, как выглядит текст при его загрузке в Flipsnack.Как выделить текст в Adobe:
Разблокировать все текстовые слои
Выделить весь текст (Mac: Cmd + A) (ПК: Ctrl + A)
В поле «Тип» », нажмите« Создать контуры »
Нажмите« Файл »и выберите« Сохранить как », и вы сохраните документ как новый файл.Но сохраните копию исходного файла, чтобы редактировать текст в будущем. Как только текст будет обведен, вы больше не сможете его редактировать.
Далее, некоторые другие текстовые проблемы , с которыми вы можете столкнуться, и способы их устранения:
Перед загрузкой файла PDF на Flipsnack убедитесь, что текст в вашем документе вставлен как текст (имеет шрифт, цвет и размер шрифта), а не как изображение.
В противном случае ваш текст не будет выглядеть таким четким при увеличении, потому что при использовании реального текста он будет преобразован в SVG.Кроме того, проверьте, можно ли выделить текст, так вы будете знать, что он будет правильно отображаться в Flipsnack.
 В противном случае ваш текст не будет выглядеть таким четким при увеличении, потому что при использовании реального текста он будет преобразован в SVG.Кроме того, проверьте, можно ли выделить текст, так вы будете знать, что он будет правильно отображаться в Flipsnack.
В противном случае ваш текст не будет выглядеть таким четким при увеличении, потому что при использовании реального текста он будет преобразован в SVG.Кроме того, проверьте, можно ли выделить текст, так вы будете знать, что он будет правильно отображаться в Flipsnack.Примечание : Вот как мы автоматически обнаруживаем ссылки в PDF-файлах. Также читайте больше о добавлении гиперссылок в нашей Дизайн-студии.
Также связанные с текстом, вы можете столкнуться с проблемами с шрифтами . Это почему?
Вы не встроили шрифты в документ при экспорте.
Вероятно, вы используете слишком много семейств шрифтов;
Старайтесь не использовать лигатуры в вашем PDF-файле.Мы можем столкнуться с проблемами рендеринга в Flipsnack.
Другие рекомендации по экспорту PDF:
При экспорте наилучшим форматом для сохранения будет PDF / A или PDF / X.
Перейдите в меню «Инструменты»> «Стандарты PDF» и выберите «Сохранить как PDF / A», «Сохранить как PDF / X».Файл PDF должен быть меньше 100 МБ и содержать 500 страниц;
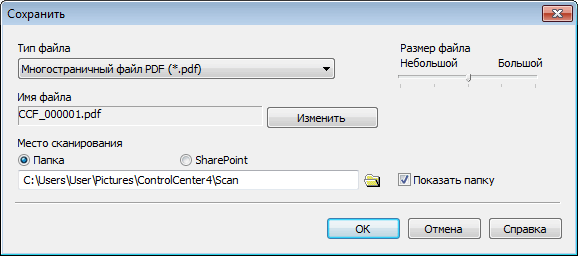 Перейдите в меню «Инструменты»> «Стандарты PDF» и выберите «Сохранить как PDF / A», «Сохранить как PDF / X».
Перейдите в меню «Инструменты»> «Стандарты PDF» и выберите «Сохранить как PDF / A», «Сохранить как PDF / X».Предустановка InDesign
У нас есть хорошие новости для всех: мы создали предустановку для InDesign, которая поможет вам экспортировать гораздо более простые файлы PDF, чтобы весь процесс экспорта и загрузки был максимально плавным.
Расширение Flipsnack для Adobe InDesign
Если вы используете Adobe InDesign CC для создания файлов PDF, узнайте, что вы можете использовать расширение Flipsnack для Adobe InDesign, чтобы сэкономить время и загрузить файлы PDF, с которыми вы работаете прямо в Flipsnack.
Если у вас по-прежнему возникают проблемы с файлами PDF, обязательно свяжитесь с нами через службу поддержки в чате.
Удачной загрузки!
PDF Structure Viewer
Estel Pdf Structure Viewer - отличный инструмент для профессионалов, работающих с PDF-версиями до 10, и позволяет просматривать структуру документа на уровне объекта.Просмотр содержимого файлов PDF на уровне объекта может быть чрезвычайно трудным или невозможным. PDF - это двоичный формат, и традиционные средства просмотра плохо приспособлены для просмотра сложной структуры PDF-документа. Кроме того, потоки данных в формате PDF могут быть зашифрованы и сжаты в различных формах, а обычный просмотр не позволяет увидеть контент. Estel Pdf Structure Viewer автоматизирует задачу низкоуровневого просмотра PDF. Estel Pdf Structure Viewer позволяет просматривать низкоуровневые объекты, такие как словари, массивы, потоки, числа и т. Д.Вы можете видеть не только содержимое объектов, но и изучать взаимосвязи между объектами, видеть настройки безопасности документов. Простой в использовании и интуитивно понятный графический интерфейс пользователя позволяет синхронизировать положение объекта в файле PDF, а также быстро получать помощь по этому проекту, прочитав официальное руководство по формату PDF, которое отображается в отдельной закладке. Вся эта информация необходима и полезна для специалиста или разработчика программного обеспечения PDF и, безусловно, приводит к резкому увеличению производительности.
Вся эта информация необходима и полезна для специалиста или разработчика программного обеспечения PDF и, безусловно, приводит к резкому увеличению производительности.
PDF - самый популярный формат передачи и обмена информацией (http: // www.adobe.com/devnet/pdf.html). Конечно, много разработчиков программного обеспечения, желающих поделиться своими идеями по работе с этим форматом. Я тоже решил изучить этот формат, чтобы найти тему для развития моих программ. Думаю, что многие молодые исследователи формата PDF шокированы количеством документации по нему. Начиная со Справочника в формате PDF (http://wwwimages.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/pdf_reference_1-7.pdf) документация разочаровывает многих разработчиков своим количеством.Блуждая по просторам Интернета в поисках более быстрого развития формата pdf, я наткнулся на программу, которая очень интересна как для меня, так и для любого разработчика, исследующего pdf. Он называется Estel PDF Structure Viewer (http://estelsoft.com/index.php/en/pdf-structure-viewer). Я опишу его, потому что считаю, что он заслуживает внимания, по крайней мере, это сократило мое время изучения основ формата pdf.
Скачайте программу по ссылке http: // estelsoft.com / images / sv / pdf_structure_viewer.exe. Установка программы не вызывает затруднений и занимает меньше минуты вашего времени и пары кликов мышкой. Запустите программу и посмотрите в главное окно программы.
Перед нами изображение известного всем разработчикам PDF-справочника. Главное окно программы состоит из 3-х вкладок. Первый называется справочным и отображает известное руководство на нужной странице в зависимости от того, какой объект вы изучаете. Согласитесь, это очень удобно.Вторая вкладка File отображает открытый файл для изучения. И третья вкладка Objects отображает различную информацию об интересующем нас файле. Итак, мы начинаем. Откройте интересующий файл, нажав кнопку на панели.
или кнопки в конце поля PDF-файла в верхней части вкладок, описанных выше.
Выберите файл в стандартном диалоговом окне выбора файла. Диалоговое окно уже отфильтровано для отображения только файлов формата pdf.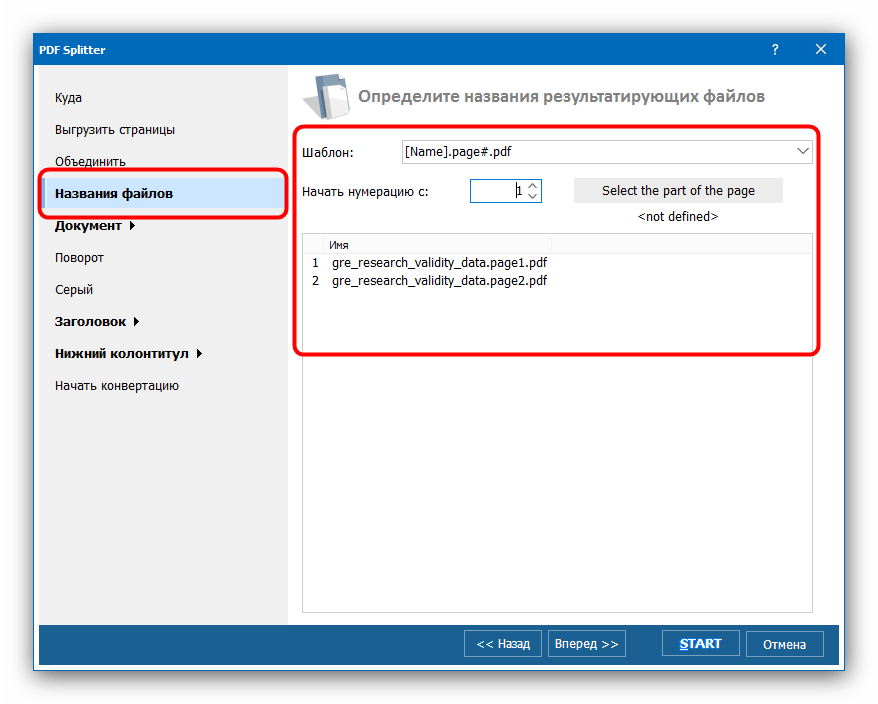
О загрузке файла сообщает индикатор выполнения внизу программы
После финальной загрузки файла становится активной вкладка File, на которой визуально отображается наш загруженный файл.
Считаю это очень хорошим решением, потому что сразу видно, что соответствует данному файлу. Переходим на вкладку Objects.
Мы видим три ряда таблиц. Справа находится таблица файла XREF. Он идентифицирует номер объекта, номер генерации объекта, тип объекта, знак Free, а также смещение от начала файла. Справа находится так называемая программа просмотра HEX-TEXT, которая удобно представляет содержимое файла.Средние таблицы отображают содержимое объекта из таблицы XREF. Если мы щелкнем в таблице XREF на любой строке, которая выбирает этот объект, мы увидим изображение ниже:
Выбранный объект в таблице XREF станет светло-зеленым фоном, справа красным фоном будет выделено содержимое этого объекта в файле, а в верхней средней таблице появится содержимое этого объекта в соответствии с классификацией pdf. В этой таблице показаны три поля - ключ, тип и значение.Наш объект номер 1 имеет словарный тип и состоит из объектов, представленных в верхней средней таблице.
В этой таблице показаны три поля - ключ, тип и значение.Наш объект номер 1 имеет словарный тип и состоит из объектов, представленных в верхней средней таблице.
Если щелкнуть любую строку в средней таблице, дополнительно справа зеленым цветом будет выделено расположение значения внутри основного объекта, как показано на рисунке ниже.
Если в верхней средней таблице щелкнуть строку, где указан объект типа «массив» или «dict», то есть объекты-контейнеры, содержащие другие объекты, будет использоваться средняя нижняя таблица.
Зеленым цветом справа будет выделено содержимое этого контейнера справа, а в средней нижней таблице отобразится содержимое контейнера в соответствии с квалификацией pdf. Если выбрать любую строку в нижней таблице, то аналогично верхней будет выделено зеленым цветом значение этого объекта в правой таблице.
Дополнительно, под появлением информации в нижней таблице, между средними таблицами появилась желтая кнопка с цифрой «0».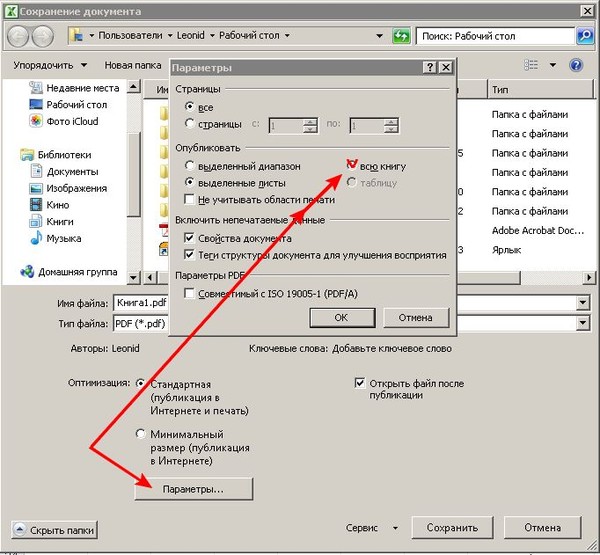
Эта кнопка указывает уровень вложенности или глубину представления объекта. Если этот объект-контейнер включает в себя другой контейнер, то при нажатии на него в нижней таблице появится его содержимое, увеличится глубина обзора и появится кнопка с цифрой «1» и т. Д.
Переход между уровнями осуществляется нажатием кнопки с соответствующим уровнем. Кнопка текущего уровня окрашена в желтый цвет. Независимо от того, находится ли это нижняя или верхняя таблица, когда вы нажимаете на объект ссылки, т.е.е. если в типе объекта есть фраза «ссылка», а поле «Значение» содержит фразу типа obj: 19473 gen: 0, где 19473 - номер объекта в таблице XREF, на который ссылается эта ссылка, вы переходите к этому объекту .
Другими словами, щелчок по ссылке такой же, как если бы мы щелкнули по объекту в таблице XREF.
Как пользоваться вкладкой «Справочник»? Если мы щелкнем по любому объекту в верхней или нижней средней таблице, вы увидите картинку ниже:
Однако, если при этом перейти на вкладку «Справочник», гид автоматически перейдет на страницу с описанием типа выбранного нами объекта.
При выборе объекта типа "число", как показано на рисунке ниже,
страница "справки" в этом случае будет выглядеть (т.е. будет отображать страницу, описывающую числовые объекты).
Могу вам сказать, это значительно сокращает время на поиск конкретной информации.
Сайт программы содержит план дальнейшего развития программы и планы выпуска многих других программ. По их словам, нас ждет много интересных функций.Для указанной выше программы будет добавлен следующий уровень построения объектов, то есть вы сможете узнать, из каких объектов изображения, шрифты и т. Д. Построены в файле pdf. Ссылка на pdf ссылка будет глубже.
Будет выпущена программа, которая посвятит нас миру безопасности и шифрования pdf файлов, поможет нам восстановить забытые пароли на pdf файлы или снять с них любые ограничения. При этом подбор паролей к файлу будет производиться как на компьютере, так и на других компьютерах LAN или WAN, а также с использованием новых вычислительных технологий через ресурсы видеокарты.
Будет интересен выпуск программы, "вытягивающей" ресурсы pdf файла. То есть шрифты, изображения, 2d и 3d презентации, звуки и видео, встроенные в файлы pdf, с помощью этой программы могут быть сохранены в отдельных файлах.
Одним словом, нас ждет много интересного на сайте www.estelsoft.com.1. Для кого предназначена эта программаЭта программа предназначена для разработчиков программного обеспечения для обработки файлов PDF или как-либо для их изменения. Программа позволяет визуально исследовать структуру PDF-файла на уровне так называемых объектов, т.е.е. те элементарные строительные блоки, на которых построены все возможности PDF. Программа также может быть полезна для изучения PDF в качестве справочного материала.
2. Есть ли бесплатный ознакомительный период работы программы и каковы его пределы в этот период.
Да, у программы есть испытательный срок - 30 дней. В этот период есть какие-то функциональные ограничения.
3. Почему при выборе объекта (щелчком мыши) справа мой объект не отображается и не выделяется.