Как найти элемент в коде
Новичку очень трудно найти нужный символ или слово в массе кода, однако это делается очень быстро и просто. Если не знаете как, то читайте дальше.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
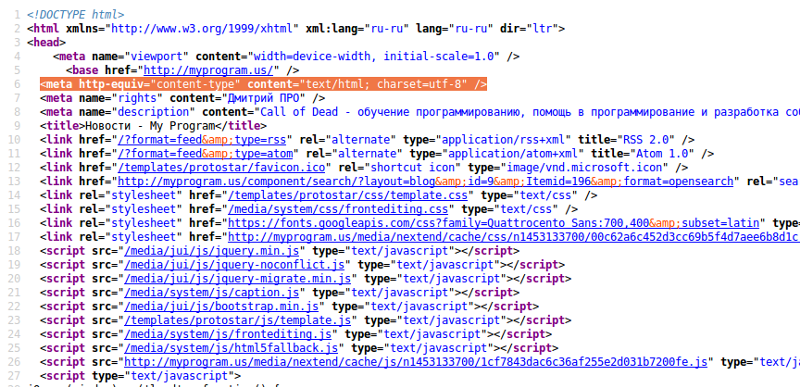
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Перед Вами откроется код файла style.css. Покрутите его вниз, и первое, что придёт Вам в голову будет: ё-моё, как же в этой массе английских слов, цифр и символов, найти то, что нам будет нужно.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Рассмотрим два варианта, в зависимости от начальных условий, нахождения нужного элемента в коде.
Вариант 1.
Условие: мы точно знаем то, что нам нужно найти.
Для примера возьмём код страницы.
Комбинация клавиш Contrl-F откроет окно поиска в правом верхнем углу, в которое можно ввести искомый элемент кода. Элемент и все его повторения подсветятся.
Этот поиск работает абсолютно для любого кода, открытого в браузере, то есть на странице.
Вариант 2.
Условие: мы видим элемент на странице, но не знаем ни его html, ни css.
В этом случае потребуется web-инспектор, или по другому Инструмент разработчика.
Инструмент разработчика есть во всех браузерах и открыть его можно или клавишей F12, или правой клавишей мыши, выбрав «Просмотреть код» или «Исследовать элемент». В разных браузерах по разному.
Главное не выбирайте «Просмотреть код страницы». Похоже, но не то.
После этого появится web-инспектор. Его интерфейс в разных браузерах немного отличается, но принцип действия везде одинаковый.
Я покажу на примере web-инспектора Chrome.
Заходим на страницу и открываем web-инспектор. По умолчанию он откроется в двух колонках, в левой будет html код всех элементов, находящихся на странице, а в правой — css оформление.
Изначально, код откроется в сложенном виде, то есть будут видны только основные элементы страницы, но если щёлкнуть по треугольничку в начале строки, то откроются все вложения, находящиеся в элементе.
И вот так, открывая вложение за вложением, можно добраться практически до любого элемента, находящегося на странице.
Определить, какой код, какому элементу соответствует, очень просто.
Надо просто вести по строкам курсором, и как только курсор оказывается на строке с кодом, так тут-же элемент, которому соответствует этот код, подсвечивается.
Теперь найдём css этого элемента. Для этого надо один раз щёлкнуть левой клавишей по строке с html, и в правой колонке отобразятся все стили, которые ему заданы, а так-же стили, влияющие на элемент, от родительских элементов.
Теперь, зная class или id элемента, можно спокойно идти в файл style.css, найти в нём нужный селектор, с помощью Поиска (Ctrl+F), и править внешний вид элемента.
Желаю творческих успехов.
Неужели не осталось вопросов? Спросить
Перемена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?!
— Дочь а нечего что я папа?
Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
В раздел > > > Исправляем шаблон WordPress. Веб-инспектор
Запись опубликована в рубрике CMS WordPress Система управления сайтом для создания блога. Добавьте в закладки постоянную ссылку.
Поиск связанных между собой сайтов по коду Google Analytics
Язык:
- English (UK)
Допустим, вы нашли в сети анонимный веб-сайт и хотите узнать, кто его создал. Воспользовавшись уникальным кодом, вы можете найти связь между этим ресурсом и другими сайтами и даже узнать, кто является их собственником. С правильными инструментами найти интересующую вас информацию будет очень легко.
Поиск сайтов по коду
При помощи популярного сервиса Google Analytics веб-разработчики собирают данные о посещаемости (такие как страна, тип браузера и оперативной системы) по пользователям разных доменов. Для этого в html-код каждой страницы добавляется уникальный идентификационный номер (код) – именно благодаря ему можно проследить связь между различными сайтами. По такому же принципу работают Google AdSense, Amazon и AddThis.
Для этого в html-код каждой страницы добавляется уникальный идентификационный номер (код) – именно благодаря ему можно проследить связь между различными сайтами. По такому же принципу работают Google AdSense, Amazon и AddThis.
Существует несколько ресурсов, позволяющих выполнить обратный поиск этого уникального кода и найти связанные сайты. Лично мне больше всего нравится работать с http://sameid.net (производит поиск не только по коду Analytics и AdSense, но и по коду Amazon, Clickbank и Addthis) и с http://www.spyonweb.com. SpyOnWeb совершенно бесплатный, а вот на SameID без оплаты предоставляются только пять запросов в день.
Результаты поиска кода Analytics на сайте SameID
Более продвинутым пользователям могу посоветовать ресурс NerdyData https://search.nerdydata.com/, который ищет совпадения по любому введенному фрагменту кода. В платной версии есть очень удобная функция сохранения результатов поиска. Но иногда этот сайт отображает один и тот же результат несколько раз, и из-за этого на поиск уходит много времени.
В NerdyData можно ввести любой код и просмотреть результаты поиска.
Meanpath.com – аналогичный по функциональности сайт для поиска кодов, в бесплатной версии выводится не более 100 результатов.
Советую использовать сразу несколько инструментов, потому что они иногда предоставляют разные результаты. В ходе эксперимента я выяснил, что SpyOnWeb выдает меньше результатов, чем SameID, а в Meanpath было два результата, которых не нашли ни SpyOnWeb, ни SameID.
Еще коды Analytics или AdSense можно ввести в поиск в Google – только не забудьте заключить их в кавычки (например, “UA-12345678”). Таким образом вы получите результаты обратного поиска из других инструментов. Кроме того, если адрес или код Analytics сайта недавно был изменен, через Google вам, возможно, удастся найти сохраненные в кэш результаты из сервисов по типу SameID и все-таки выйти на связанный сайт. Чтобы просмотреть сохраненную копию, нажмите на зеленую направленную вниз стрелку рядом с результатом:
Сверка с кодом страницы
Результаты, выданные средствами поиска по коду, необходимо проверить.
Для этого в браузерах Firefox, Chrome, Internet Explorer и Opera нажмите правой кнопкой мыши на любое место на странице и в появившемся контекстном меню выберите View Source или Source (Просмотр кода страницы / Исходный код / Просмотр HTML-кода).
В браузере Safari для этого нужно открыть меню Page (Страница) в правом верхнем углу окна и выбрать аналогичную команду.
После этого появится окно с исходным кодом – в нем мы будем искать код Analytics. Для этого выберите Edit (Изменить / Редактировать) > Find (Найти) или воспользуйтесь комбинацией клавиш CTRL + F для Windows (аналогичная комбинация для Mac: ⌘ + F). Введите в строку поиска следующие теги:
- AdSense: Pub- или ca-pub
- Analytics: UA-
- Amazon: &tag=
- AddThis: #pubid / pubid
Поиск кода Google Analytics в исходном коде страницы
Поиск связанных сайтов через сервисы WHOIS
Из данных о том, на кого зарегистрирован домен, мы можем извлечь ценную информацию о лицах, связанных с интересующим нас сайтом. Эти данные включают имена, адреса электронной почты, почтовые адреса, номера телефонов. Конечно, не исключено, что они уже устарели, но для нас это не принципиально – мы просто ищем связь между сайтами.
Эти данные включают имена, адреса электронной почты, почтовые адреса, номера телефонов. Конечно, не исключено, что они уже устарели, но для нас это не принципиально – мы просто ищем связь между сайтами.
Существует множество сервисов WHOIS, рекомендую вам всегда проверять найденную информацию по нескольким сервисам. Мне нравится https://who.is/, который отображает как историю регистрации сайта, так и текущие данные. Это оказывается особенно полезным в том случае, если сайт недавно был переведен на анонимную регистрацию.
Сайт Domaintools, где представлены адрес электронной почты и название организации, зарегистрировавшей домен, – при помощи этих данных можно найти связь с другими сайтами.
Есть еще http://whois.domaintools.com, где, помимо прочего, указаны тип и версия серверного программного обеспечения, используемого на сайте, и примерное количество размещенных на нем изображений. Whoisology выдает не только архивные результаты, но и домены, зарегистрированные по определенным адресам электронной почты.
Отображение всех доменов, зарегистрированных по одному и тому же адресу электронной почты, на сайте Whoisology.
Некоторые сервисы WHOIS не распознают кириллические URL-адреса. Для преобразования адреса воспользуйтесь этим инструментом: Verisign IDN Conversion Tool.
Использование метаданных
Основная масса изображений и документов, загруженных в сеть, содержит метаданные – информацию, записанную при создании или редактировании файла. Один из журналистов Bellingcat Мелисса Хэнхем уже написала о том, как использовать метаданные при геолокации. Нас же интересует, как метаданные помогут нам найти связанные сайты.
Два, на мой взгляд, наиболее удобных инструмента для просмотра метаданных – http://fotoforensics.com/ (только для фотографий) и Jeffrey’s EXIF Viewer (также анализирует документы, в том числе PDF, Word и OpenOffice.
 )
)Метаданные документа в формате ODF на сайте Jeffrey’s EXIF Viewer.
Существует много разных видов метаданных, но нас в первую очередь интересуют EXIF, Maker Notes, ICC Profile, Photoshop и XMP.
Результаты анализа метаданных на FotoForensics.
В них содержится такая информация, как точная версия редактора изображений. Например, в поле XMP «Creator Tool» может стоять «Microsoft Windows Live Photo Gallery 15.4.3555.308». В поле «XMP Toolkit» часто отображаются похожие данные, например «Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27». Главное – выбрать поля, где указана конкретная и подробная информация. При анализе фотографии иногда отображается модель фотоаппарата, на который она была сделана (например, «KODAK DX4330 DIGITAL CAMERA»).
Разумеется, одна и та же версия Photoshop или одинаковый фотоаппарат могут быть у миллионов разных людей, так что эту информацию следует использовать только при наличии других надежных доказательств, таких как код Google Analytics.
Иногда в метаданных фотографии даже может быть указан уникальный серийный номер фотоаппарата. Проведите обратный поиск по такой информации при помощи инструментов http://www.stolencamerafinder.com/ и http://www.cameratrace.com/, чтобы найти другие снимки, сделанные этим же устройством.
Сохранение страниц
Часто бывает такое, что веб-контент неожиданно изменяется или исчезает – а вместе с ним и все важные для нас коды Analytics. К счастью, у нас есть возможность сохранять веб-страницы. Предпочтительно сохранять не только сайты, которые вы изучаете, но и результаты поиска из SameID и других сервисов.
Для быстрого и удобного сохранения воспользуйтесь Internet Archive Wayback Machine. После архивации содержание страницы нельзя изменить, так что вряд ли кто-то возьмется оспаривать ее подлинность.
Кроме того, Wayback Machine вставляет дату и время в код архивированной страницы, так что этому инструменту доверяют даже криминалисты.
Сервис WebCite похож на Wayback Machine, но здесь пользователю разрешается редактировать некоторые данные. Для просмотра кода архивной страницы вместо View Source вам придется использовать View Frame Source (This Frame в браузере Firefox). Но плюсы у этого сервиса тоже есть – он отправляет адреса архивированных страниц в ваш почтовый ящик. Существует также Archive.is, он очень удобен для сохранения профилей из социальных сетей.
Есть одна загвоздка – все эти инструменты позволяют архивировать вручную только отдельные страницы, но не весь сайт. Кроме того, они не будут работать, если ресурс защищен от поисковых роботов или автоматического копирования контента с целью его размещения на других сайтах. В этом случае лучше всего будет сохранить отдельные страницы на компьютер и/или сделать скриншот. Я пользуюсь бесплатным инструментом Web Page Saver с сайта Magnet Forensics, хотя в некоторых случаях подойдут также Windows Snipping Tool и DropBox.
Кроме того, имеет смысл вручную добавить страницу в индекс Google. Тогда она с больше вероятностью будет сохранена в кэш Google, где вы потом сможете ее найти.
Тогда она с больше вероятностью будет сохранена в кэш Google, где вы потом сможете ее найти.
Графическое отображение
Если вы изучаете большую группу сайтов, то в связях между ними легко запутаться. Для удобства организуйте их в диаграмму.
Бесплатное приложение yEd Graph Editor (для операционных систем Windows, OS X и Linux) – очень удобный инструмент для составления как простых, так и сложных графиков и диаграмм. Чтобы сделать диаграмму, просто перетащите иконки мышкой в нужное место и обозначьте связь между ними.
Для начала внесите все элементы, которые вам удалось найти: адреса сайтов, имена, названия организаций и уникальные коды. Если вы узнали что-то новое, не забудьте добавить эту информацию в диаграмму. В приложении yEd есть иконки, обозначающие компьютеры, файлы, людей и т. д., так что можете дать волю креативности.
Выбор диаграмм и графиков достаточно большой. В этом примере я воспользовался диаграммами Circular и BCC Isolated, отобразив в виде круга сайты, каждый из которых связан с расположенным в центре кодом Analytics.
Выводы
В этой статье мы рассмотрели открытые источники информации и инструменты, которые позволяют найти связь между сайтами, на первый взгляд не имеющими ничего общего. Мы также выяснили, что чтобы никто не сомневался в результатах нашего расследования, необходимо искать подтверждение в других источниках и всегда сохранять найденные страницы.
Поисковая система для исходного кода
Найдите любой буквенно-цифровой фрагмент, подпись или ключевое слово в коде веб-страниц HTML, JS и CSS.
Синтаксис запроса : RegEx, ccTLD и т. д. Идет поиск…
504 958 218 веб-страниц
26 октября 2022 г.
Идеальное решение для цифрового маркетинга и исследований партнерского маркетинга, PublicWWW позволяет вам выполнять поиск таким образом, то, что невозможно с другими обычными поисковыми системами:
- Любой HTML, JavaScript, CSS и обычный текст в исходном коде веб-страницы
- Ссылки на вопросы StackOverflow в HTML,
.
 CSS и
.JS-файлы
CSS и
.JS-файлы - Веб-дизайнеры и разработчики, ненавидящие IE
- Сайты с одинаковым идентификатором аналитики: «UA-19778070-»
- Сайты, использующие следующую версию nginx: «Сервер: nginx/1.4.7»
- Пользователи рекламных сетей: «adserver.adtech.de»
- Сайты, использующие одну и ту же учетную запись AdSense: «pub-9533414948433288»
- WordPress с темой: «/wp-content/themes/twentysixteen/»
- Поиск связанных веб-сайтов с помощью уникальных кодов HTML, которые они используют, т. е. идентификаторов виджетов и издателей
- Идентифицировать сайты с помощью определенных изображений или значков
- Узнайте, кто еще использует вашу тему
- Определите сайты, на которых вас упоминают
- Ссылки на использование библиотеки или платформы
- Найдите примеры кода в Интернете
- Выясните, кто какие JS-виджеты использует на своих сайтах.
 CSS и
.JS-файлы
CSS и
.JS-файлыФункции
- До 1 000 000 результатов на поисковый запрос
- API для разработчиков, которые хотят интегрировать наши данные
- Загрузить результаты в виде файла CSV
- Фрагменты результатов поиска
- Результаты отсортированы по популярности веб-сайта
- Поиск обычно выполняется в течение нескольких секунд
- 504 958 218 веб-страниц проиндексировано
- HTTP-заголовки ответа веб-сервера также индексируются
- Сайты из топ-1 000 000 открываются бесплатно
- Результаты из топ-3 000 000 по факту
регистрация,
остальные платные.

Примеры использования
«angular.min.js»
«Bootstrap.min.js»
«addThis_widget.js»
«Recaptcha/Api.js»
«X-akamai-transmed»
9
4
4
4
4
4499444994449944499444994449944499444994449944499444944944494444944494449494449494
449944944944944944944944944944449444494449. «AlgoliaSearch»
узловая точка
«Begin comScore Tag»
«Histats.com START»
«cmdatatagutils.js»
«api. convertkit.com»
convertkit.com»
«app.adjust.com»
Дополнительные примеры
2
9 Статистика и исследования Вы можете взаимодействовать с нашей статистикой, основанной на нашей веб-аналитике, а также получать помощь в поиске, использовании и понимании данных.
Файлы .JS
Файлы .CSS
Объекты Javascript
Свойства CSS
IMG Files
HTTP Server Header
X-Power-By
Мета генератор
домены IMG
JavaScript Domains
Domains
Files
о Clascers-Publicwwww.com
9003
00 о Clascers-Publicwww.
com
 com
com. «Кластер» — это набор уникальных доменных имен, проиндексированных PublicWWW. Работа с кластерами доступна для зарегистрированных пользователей.
Существует три способа создания кластера:
- Экспорт доменных имен из результатов поиска с помощью кнопки Кластер. Уникальные домены будут сохранены для будущих действий.
- Загрузите файл со списком доменов, URL-адресов или адресов электронной почты. Уникальные известные домены будут сохранены.
- Выполнять логические операции «И», «ИЛИ», вычитания с другими кластерами.
Сохранение и сравнение результатов поиска в обновлениях PublicWWW будет проще с помощью кластеров. Новые веб-сайты с подписями или веб-сайты, потерявшие подписи, могут быть найдены путем вычитания. Также для фильтрации результатов поиска можно применять собственные списки доменов, URL-адресов или адресов электронной почты.
Каждый кластер может быть «извлечен» для конкретного контента веб-сайта, проиндексированного PublicWWW (включая внутренние страницы). Например, упомянутые номера телефонов, аккаунты в социальных сетях, адреса и т. д.
У нас есть несколько полезных шаблонов извлечения, но вы можете создать свой собственный с помощью RegEx.
Например, упомянутые номера телефонов, аккаунты в социальных сетях, адреса и т. д.
У нас есть несколько полезных шаблонов извлечения, но вы можете создать свой собственный с помощью RegEx.
Кластеры доступны для просмотра страница за страницей или загрузки в виде файла.
- Давайте используем примеры кода для виджетов:
- Найдите сайты с кодом виджета ShareThis и скопируйте доменные имена в кластер:
- То же самое с кодом виджета AddToAny и копированием доменных имен в другой кластер:
- Дождитесь обновления PublicWWW и повторите запрос для ShareThis:
- Сохраните свежие результаты ShareThis в кластер:
- Повторите запрос для AddToAny:
- Также сохраните свежие результаты AddToAny в кластер:
- Найдите новые веб-сайты с помощью кода ShareThis:
- Найдите старые веб-сайты с удаленным кодом AddToAny:
- Пересеките кластеры, чтобы узнать, кто установил ShareThis и удалил AddToAny:
- Загрузите, просмотрите или сохраните результаты для других операций:
Пример 2.